Lightweight Safety Guardrails Using Fine-tuned BERT Embeddings
作者: Aaron Zheng, Mansi Rana, Andreas Stolcke
分类: cs.CL
发布日期: 2024-11-21
备注: To appear in Proceedings of COLING 2025
期刊: Proc. 31st Intl. Conf. Computational Linguistics: Industry Track, COLING 2025, pp. 689-696
💡 一句话要点
提出基于微调BERT嵌入的轻量级安全防护栏,降低LLM部署成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全防护栏 Sentence-BERT 微调 轻量化
📋 核心要点
- 现有LLM安全防护方法依赖微调大型LLM,导致高延迟和维护成本,限制了实际部署。
- 论文提出微调轻量级Sentence-BERT模型作为安全防护栏,显著降低模型大小和计算开销。
- 实验表明,该方法在AEGIS安全基准上保持了与大型LLM防护栏相当的性能,验证了有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速普及,企业能够迅速开发概念验证和原型。因此,越来越需要实施强大的防护栏,以监控、量化和控制LLM的行为,确保其使用可靠、安全、准确,并与用户的期望保持一致。先前过滤不当用户提示或系统输出的方法,如LlamaGuard和OpenAI的MOD API,通过微调现有的LLM取得了显著成功。然而,使用微调的LLM作为防护栏会增加延迟和更高的维护成本,这对于经济高效的部署可能不实用或不具可扩展性。我们采取了一种不同的方法,专注于微调轻量级架构:Sentence-BERT。这种方法将模型大小从LlamaGuard的70亿参数减少到大约6700万,同时在AEGIS安全基准测试中保持了相当的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)部署中安全防护栏的成本和延迟问题。现有方法通常采用微调大型LLM(如LlamaGuard)作为防护栏,虽然有效,但模型体积庞大,推理速度慢,维护成本高昂,难以在资源受限的环境中部署。
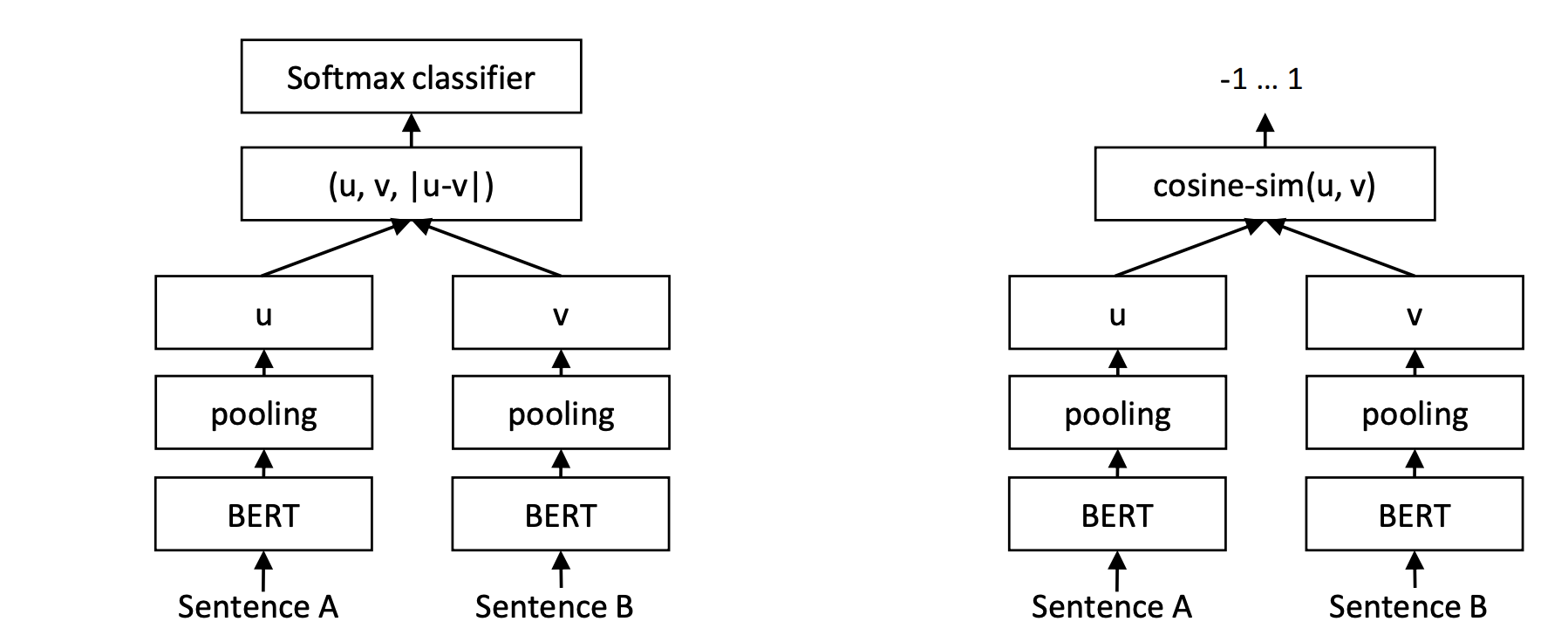
核心思路:论文的核心思路是利用轻量级的Sentence-BERT模型替代大型LLM作为安全防护栏。Sentence-BERT通过预训练的BERT模型生成句子的嵌入向量,然后利用这些向量进行相似度计算或分类,从而判断输入文本是否安全。由于Sentence-BERT模型参数量远小于大型LLM,因此可以显著降低计算成本和延迟。
技术框架:整体框架包含以下步骤:1) 使用包含安全和不安全文本的数据集;2) 使用Sentence-BERT模型将输入文本转换为嵌入向量;3) 使用微调后的Sentence-BERT模型对嵌入向量进行分类,判断文本是否安全。该框架的核心是微调Sentence-BERT模型,使其能够准确区分安全和不安全的文本。
关键创新:最重要的创新点在于使用轻量级的Sentence-BERT模型替代大型LLM作为安全防护栏。与现有方法相比,该方法在保持相当安全性能的同时,显著降低了模型大小和计算成本,使得LLM安全防护更具可扩展性和实用性。
关键设计:论文的关键设计包括:1) 选择合适的Sentence-BERT模型作为基础模型;2) 构建包含安全和不安全文本的高质量数据集;3) 设计合适的损失函数,例如交叉熵损失函数,用于微调Sentence-BERT模型;4) 调整微调过程中的超参数,例如学习率和batch size,以获得最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用微调的Sentence-BERT模型作为安全防护栏,在AEGIS安全基准测试中取得了与LlamaGuard相当的性能,同时模型大小从70亿参数减少到6700万参数,显著降低了计算成本和延迟。这表明该方法在保持安全性能的同时,实现了轻量化和高效性。
🎯 应用场景
该研究成果可广泛应用于各种需要安全防护的大型语言模型应用场景,例如聊天机器人、内容生成平台、智能客服等。通过降低安全防护栏的计算成本和延迟,可以更经济高效地部署LLM,并提高用户体验。此外,该方法还可以应用于其他文本分类任务,例如垃圾邮件过滤、情感分析等。
📄 摘要(原文)
With the recent proliferation of large language models (LLMs), enterprises have been able to rapidly develop proof-of-concepts and prototypes. As a result, there is a growing need to implement robust guardrails that monitor, quantize and control an LLM's behavior, ensuring that the use is reliable, safe, accurate and also aligned with the users' expectations. Previous approaches for filtering out inappropriate user prompts or system outputs, such as LlamaGuard and OpenAI's MOD API, have achieved significant success by fine-tuning existing LLMs. However, using fine-tuned LLMs as guardrails introduces increased latency and higher maintenance costs, which may not be practical or scalable for cost-efficient deployments. We take a different approach, focusing on fine-tuning a lightweight architecture: Sentence-BERT. This method reduces the model size from LlamaGuard's 7 billion parameters to approximately 67 million, while maintaining comparable performance on the AEGIS safety benchmark.