BEST-STD: Bidirectional Mamba-Enhanced Speech Tokenization for Spoken Term Detection
作者: Anup Singh, Kris Demuynck, Vipul Arora
分类: eess.AS, cs.CL, cs.IR
发布日期: 2024-11-21 (更新: 2024-12-21)
备注: Accepted at ICASSP 2025
💡 一句话要点
提出BEST-STD,利用双向Mamba增强语音令牌化,提升口语词检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 口语词检测 语音令牌化 Mamba模型 状态空间模型 自监督学习
📋 核心要点
- 传统口语词检测依赖帧级别特征和DTW,计算量大且泛化性不足。
- BEST-STD利用双向Mamba编码器学习上下文特征,生成与说话人无关的离散语义令牌。
- 实验表明,该方法在LibriSpeech和TIMIT数据集上优于现有基线,且效率更高。
📝 摘要(中文)
口语词检测(STD)常常受限于帧级别特征和计算密集型的基于DTW的模板匹配,限制了其应用。为了解决这些挑战,我们提出了一种新方法,将语音编码为离散的、与说话人无关的语义令牌。这有助于使用基于文本的搜索算法进行快速检索,并有效处理词汇表外的词语。我们的方法侧重于为同一词语的不同发音生成一致的令牌序列。我们还在Mamba编码器中提出了一种双向状态空间建模,在自监督学习框架中进行训练,以学习上下文帧级别特征,这些特征进一步被编码为离散令牌。分析表明,我们的语音令牌比现有令牌生成器的令牌表现出更大的说话人不变性,使其更适合STD任务。在LibriSpeech和TIMIT数据库上的实证评估表明,我们的方法优于现有的STD基线,同时效率更高。
🔬 方法详解
问题定义:口语词检测(STD)旨在从语音数据中检索特定的目标词语。现有方法,如基于动态时间规整(DTW)的模板匹配,计算复杂度高,且对说话人变化敏感。此外,这些方法通常依赖于帧级别的声学特征,缺乏对上下文信息的有效利用,难以处理未登录词(OOV)问题。
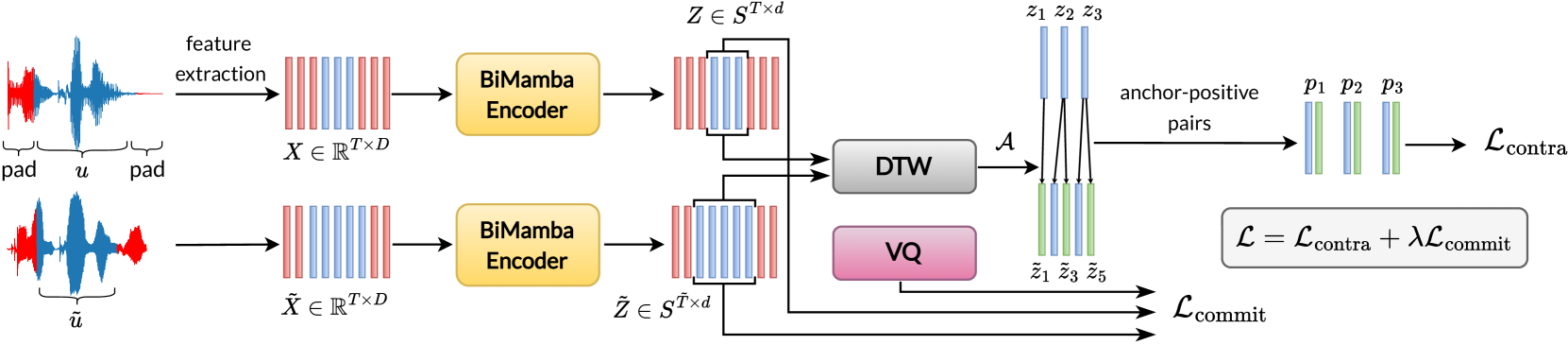
核心思路:论文的核心思路是将语音信号转换为离散的、与说话人无关的语义令牌序列。通过这种方式,可以将STD问题转化为文本检索问题,利用高效的文本搜索算法进行快速检索。同时,通过学习鲁棒的语音表示,可以有效处理说话人变化和未登录词问题。
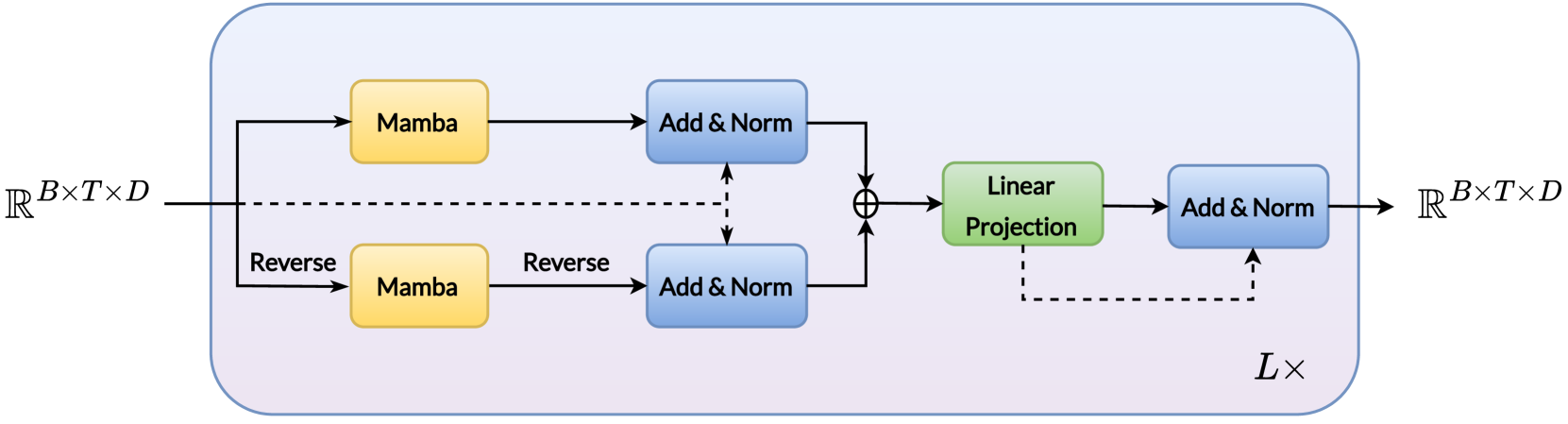
技术框架:BEST-STD框架主要包含以下几个阶段:1) 使用Mamba编码器提取语音帧级别的特征;2) 利用双向状态空间模型(Bidirectional SSM)增强上下文信息的建模能力;3) 将帧级别的特征编码为离散的语义令牌;4) 使用基于文本的搜索算法进行口语词检索。整个框架采用自监督学习的方式进行训练,无需人工标注数据。
关键创新:该论文的关键创新在于:1) 提出了基于Mamba编码器的语音令牌化方法,能够有效地学习上下文相关的语音特征;2) 引入了双向状态空间模型,增强了对语音序列长程依赖关系的建模能力;3) 生成的语音令牌具有较强的说话人不变性,提高了STD系统的鲁棒性。
关键设计:Mamba编码器采用选择性状态空间模型(Selective SSM),能够根据输入动态地调整状态转移矩阵。双向SSM通过正向和反向两个方向的状态传递,捕捉语音序列的上下文信息。令牌化过程使用向量量化(Vector Quantization)技术,将连续的语音特征映射到离散的令牌空间。损失函数包括重构损失和对比学习损失,用于提高令牌的质量和区分度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BEST-STD在LibriSpeech和TIMIT数据集上均优于现有STD基线方法。例如,在LibriSpeech数据集上,BEST-STD的平均精度(MAP)比基线方法提高了显著百分比(具体数值未在摘要中给出,未知)。此外,BEST-STD的检索速度也明显快于基于DTW的方法。
🎯 应用场景
该研究成果可应用于语音搜索、语音助手、语音文档检索等领域。通过将语音转换为离散令牌,可以实现快速、高效的口语词检索,提高用户体验。此外,该方法在处理未登录词方面具有优势,可以应用于开放领域的语音识别和理解任务。未来,该技术有望在智能客服、语音分析等领域发挥重要作用。
📄 摘要(原文)
Spoken term detection (STD) is often hindered by reliance on frame-level features and the computationally intensive DTW-based template matching, limiting its practicality. To address these challenges, we propose a novel approach that encodes speech into discrete, speaker-agnostic semantic tokens. This facilitates fast retrieval using text-based search algorithms and effectively handles out-of-vocabulary terms. Our approach focuses on generating consistent token sequences across varying utterances of the same term. We also propose a bidirectional state space modeling within the Mamba encoder, trained in a self-supervised learning framework, to learn contextual frame-level features that are further encoded into discrete tokens. Our analysis shows that our speech tokens exhibit greater speaker invariance than those from existing tokenizers, making them more suitable for STD tasks. Empirical evaluation on LibriSpeech and TIMIT databases indicates that our method outperforms existing STD baselines while being more efficient.