Robust Detection of Watermarks for Large Language Models Under Human Edits
作者: Xiang Li, Feng Ruan, Huiyuan Wang, Qi Long, Weijie J. Su
分类: stat.ME, cs.CL, cs.LG, math.ST, stat.ML
发布日期: 2024-11-21 (更新: 2025-08-26)
备注: To appear in Journal of the Royal Statistical Society: Series B
💡 一句话要点
提出Tr-GoF方法,解决人工编辑下大语言模型水印鲁棒检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 水印检测 鲁棒性 人工编辑 拟合优度检验
📋 核心要点
- 现有水印检测方法在人工编辑后性能显著下降,因为编辑会稀释水印信号,使得检测变得困难。
- 论文提出Tr-GoF方法,通过混合模型模拟人工编辑,并使用截断拟合优度检验来检测水印文本,无需精确的人工编辑信息。
- 实验表明,Tr-GoF在合成数据和开源LLM上表现出竞争力的性能,有时甚至优于现有方法,证明了其有效性。
📝 摘要(中文)
水印技术是区分大语言模型(LLM)生成文本和人工撰写文本的有效方法。然而,LLM生成文本中普遍存在的人工编辑会稀释水印信号,显著降低现有方法的检测性能。本文通过混合模型检测来模拟人工编辑,提出了一种新的截断拟合优度检验方法(Tr-GoF),用于检测人工编辑下的水印文本。理论证明,在文本修改量大和水印信号消失的特定渐近状态下,Tr-GoF测试在Gumbel-max水印的鲁棒检测方面实现了最优性。重要的是,Tr-GoF能够自适应地实现这种最优性,因为它不需要精确的人工编辑水平知识或LLM的概率规范,这与最优但难以实现的(Neyman-Pearson)似然比测试不同。此外,我们证明了Tr-GoF测试在适度文本修改的特定状态下达到了最高的检测效率。与此形成鲜明对比的是,我们表明现有方法采用的基于求和的检测规则无法在这两种状态下实现最佳鲁棒性,因为其统计数据的加性本质对编辑引起的噪声的抵抗力较弱。最后,我们在合成数据以及OPT和LLaMA系列中的开源LLM上证明了Tr-GoF测试具有竞争力的甚至更优越的经验性能。
🔬 方法详解
问题定义:现有的大语言模型水印检测方法在面对人工编辑时,鲁棒性较差。人工编辑会引入噪声,稀释原始水印信号,导致检测准确率显著下降。现有方法未能有效建模和处理这种人工编辑带来的影响,因此无法在实际应用中可靠地区分机器生成和人工撰写的文本。
核心思路:论文的核心思路是将人工编辑过程建模为一个混合模型,并基于此设计一种新的水印检测方法。通过截断拟合优度检验(Tr-GoF),该方法能够自适应地处理不同程度的人工编辑,而无需事先知道编辑的概率分布或编辑量。这种自适应性使得该方法在实际应用中更加灵活和鲁棒。
技术框架:Tr-GoF方法的核心在于使用截断的Gumbel分布来建模水印信号在人工编辑后的变化。该方法首先计算一个统计量,该统计量反映了文本中水印信号的强度。然后,使用截断的Gumbel分布来评估该统计量在有水印和无水印两种情况下的概率。最后,通过比较这两个概率,判断文本是否包含水印。整个流程包括数据预处理、统计量计算、截断Gumbel分布拟合和假设检验四个主要步骤。
关键创新:Tr-GoF的关键创新在于其截断拟合优度检验和自适应性。传统的基于求和的检测规则对噪声敏感,而Tr-GoF通过截断分布,降低了噪声的影响,提高了鲁棒性。此外,Tr-GoF不需要预先知道人工编辑的概率分布或编辑量,而是能够自适应地估计这些参数,从而在实际应用中更加灵活。
关键设计:Tr-GoF的关键设计包括:1) 使用Gumbel-max水印方案,该方案易于实现且具有良好的理论性质;2) 采用截断的Gumbel分布来建模人工编辑后的水印信号,该分布能够有效地降低噪声的影响;3) 设计了一种新的统计量,该统计量能够有效地反映文本中水印信号的强度;4) 使用拟合优度检验来判断文本是否包含水印,该检验方法具有良好的统计性质。
🖼️ 关键图片


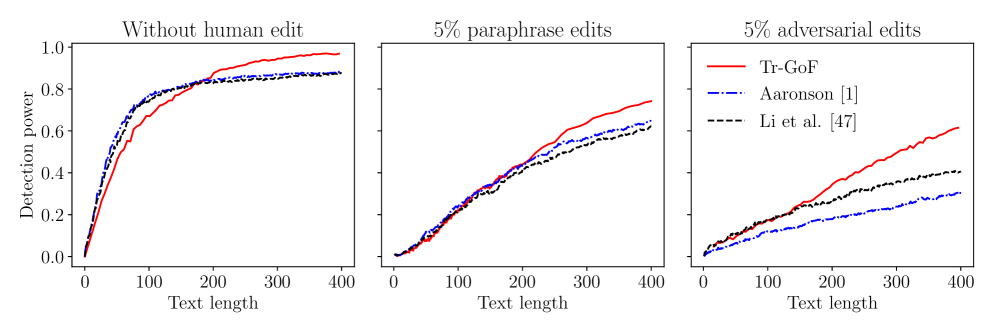
📊 实验亮点
Tr-GoF在合成数据和开源LLM(OPT和LLaMA系列)上的实验结果表明,该方法在人工编辑下具有竞争力的甚至更优越的性能。理论分析表明,Tr-GoF在特定条件下达到了最优的鲁棒检测性能和最高的检测效率,优于传统的基于求和的检测规则。实验结果验证了理论分析的正确性。
🎯 应用场景
该研究成果可应用于内容检测、版权保护和AI生成内容溯源等领域。通过鲁棒地检测LLM生成文本中的水印,可以有效区分机器生成和人工撰写的文本,防止恶意使用LLM生成虚假信息,并为AI生成内容的监管提供技术支持。该方法还有助于提高内容平台的审核效率,降低人工审核成本。
📄 摘要(原文)
Watermarking has offered an effective approach to distinguishing text generated by large language models (LLMs) from human-written text. However, the pervasive presence of human edits on LLM-generated text dilutes watermark signals, thereby significantly degrading detection performance of existing methods. In this paper, by modeling human edits through mixture model detection, we introduce a new method in the form of a truncated goodness-of-fit test for detecting watermarked text under human edits, which we refer to as Tr-GoF. We prove that the Tr-GoF test achieves optimality in robust detection of the Gumbel-max watermark in a certain asymptotic regime of substantial text modifications and vanishing watermark signals. Importantly, Tr-GoF achieves this optimality \textit{adaptively} as it does not require precise knowledge of human edit levels or probabilistic specifications of the LLMs, in contrast to the optimal but impractical (Neyman--Pearson) likelihood ratio test. Moreover, we establish that the Tr-GoF test attains the highest detection efficiency rate in a certain regime of moderate text modifications. In stark contrast, we show that sum-based detection rules, as employed by existing methods, fail to achieve optimal robustness in both regimes because the additive nature of their statistics is less resilient to edit-induced noise. Finally, we demonstrate the competitive and sometimes superior empirical performance of the Tr-GoF test on both synthetic data and open-source LLMs in the OPT and LLaMA families.