Robust Planning with Compound LLM Architectures: An LLM-Modulo Approach
作者: Atharva Gundawar, Karthik Valmeekam, Mudit Verma, Subbarao Kambhampati
分类: cs.CL, cs.AI
发布日期: 2024-11-20
💡 一句话要点
提出LLM-Modulo框架,通过LLM与验证器结合,提升LLM在规划调度任务中的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 规划调度 鲁棒性 验证器 复合架构
📋 核心要点
- 现有LLM在规划调度任务中,依赖提示工程,泛化能力弱,缺乏鲁棒性和可预测性。
- LLM-Modulo框架将LLM与验证器结合,验证LLM输出,若错误则重新提示,确保输出正确性。
- 实验结果表明,LLM-Modulo框架在多个调度领域显著提升性能,并探索了框架配置修改对性能的影响。
📝 摘要(中文)
以往的研究试图通过各种提示工程技术来提升大型语言模型(LLM)在规划和调度任务中的性能。虽然这些方法在测试的分布范围内有效,但它们既不鲁棒也不可预测。这种局限性可以通过复合LLM架构来解决,在这种架构中,LLM与其他组件协同工作以确保可靠性。本文提出了一种复合LLM架构——LLM-Modulo框架的技术评估。在该框架中,LLM与一套完整的可靠验证器配对,以验证其输出,如果失败则重新提示。这种方法确保系统永远不会输出任何错误的输出,因此保证生成的每个输出都是正确的——这是以前的技术无法声称的。我们的结果在四个调度领域进行了评估,证明了使用各种模型的LLM-Modulo框架的显着性能提升。此外,我们探索了对框架基本配置的修改,并评估了它们对整体系统性能的影响。
🔬 方法详解
问题定义:论文旨在解决LLM在规划和调度任务中鲁棒性不足的问题。现有方法依赖于提示工程,虽然在特定分布下有效,但面对新的或未知的场景时,性能会显著下降,缺乏泛化能力和可靠性。因此,需要一种能够保证输出正确性的方法。
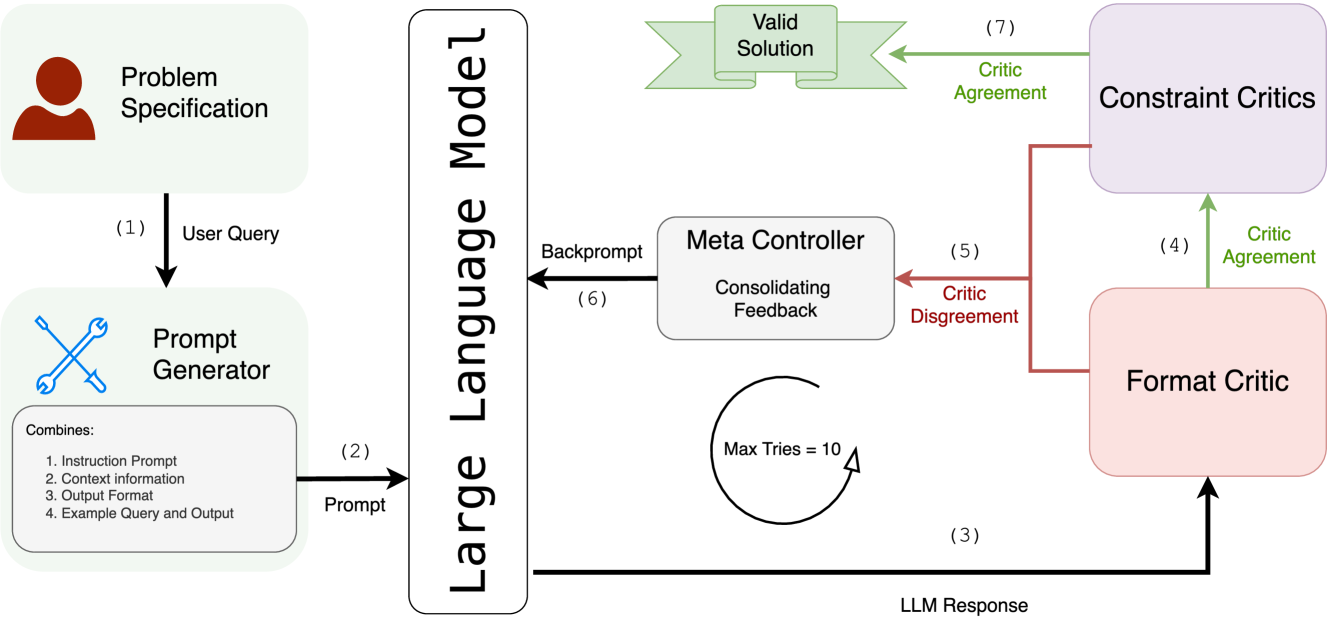
核心思路:论文的核心思路是将LLM与一组完备的验证器结合起来。LLM负责生成规划或调度方案,而验证器则负责对LLM的输出进行验证,判断其是否满足约束条件或规则。如果验证失败,则重新提示LLM生成新的方案,直到生成一个通过验证的方案为止。
技术框架:LLM-Modulo框架包含两个主要模块:LLM和验证器。LLM负责生成候选的规划或调度方案。验证器是一组独立的、可靠的程序,用于验证LLM生成的方案是否满足问题的约束条件。框架的流程如下:1) LLM生成一个方案;2) 验证器对该方案进行验证;3) 如果验证通过,则输出该方案;4) 如果验证失败,则向LLM提供反馈,并要求其生成新的方案;5) 重复步骤2-4,直到找到一个通过验证的方案。
关键创新:该方法最重要的创新点在于将LLM的生成能力与验证器的可靠性相结合,从而保证了输出的正确性。与传统的提示工程方法相比,LLM-Modulo框架不需要针对特定领域进行精细的提示设计,并且能够更好地应对未知的场景。此外,该框架提供了一种通用的架构,可以方便地集成不同的LLM和验证器。
关键设计:验证器的设计是该框架的关键。验证器需要能够准确地判断LLM生成的方案是否满足问题的约束条件。在具体的实现中,验证器可以使用各种技术,例如约束求解器、模型检查器或领域特定的算法。论文中没有详细说明具体的参数设置、损失函数或网络结构,因为LLM-Modulo框架本身是一种通用的架构,可以与不同的LLM和验证器结合使用。关键在于验证器的完备性和正确性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM-Modulo框架在四个调度领域都取得了显著的性能提升。具体而言,该框架能够保证输出的正确性,并且在某些情况下,能够比传统的提示工程方法更快地找到解决方案。论文还探索了对框架基本配置的修改,例如:使用不同的LLM模型、调整验证器的数量等,并评估了这些修改对整体系统性能的影响。
🎯 应用场景
该研究成果可应用于各种需要可靠规划和调度的领域,例如:自动驾驶、机器人任务规划、供应链管理、资源调度等。通过结合LLM的生成能力和验证器的可靠性,可以构建更加智能和可靠的自动化系统,提高效率并降低风险。未来,该框架可以进一步扩展到更复杂的任务和领域,例如:多智能体协作、动态环境下的规划等。
📄 摘要(原文)
Previous work has attempted to boost Large Language Model (LLM) performance on planning and scheduling tasks through a variety of prompt engineering techniques. While these methods can work within the distributions tested, they are neither robust nor predictable. This limitation can be addressed through compound LLM architectures where LLMs work in conjunction with other components to ensure reliability. In this paper, we present a technical evaluation of a compound LLM architecture--the LLM-Modulo framework. In this framework, an LLM is paired with a complete set of sound verifiers that validate its output, re-prompting it if it fails. This approach ensures that the system can never output any fallacious output, and therefore that every output generated is guaranteed correct--something previous techniques have not been able to claim. Our results, evaluated across four scheduling domains, demonstrate significant performance gains with the LLM-Modulo framework using various models. Additionally, we explore modifications to the base configuration of the framework and assess their impact on overall system performance.