Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL
作者: Zhibo Chu, Zichong Wang, Qitao Qin
分类: cs.CL
发布日期: 2024-11-20
💡 一句话要点
LPE-SQL:利用可扩展的辅助知识库,提升文本到SQL的持续学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SQL 持续学习 大型语言模型 知识库 经验检索
📋 核心要点
- 现有文本到SQL方法依赖上下文学习,忽略了人类持续学习能力,导致性能瓶颈。
- LPE-SQL框架通过可扩展的辅助知识库,使LLM具备持续学习能力,无需微调参数。
- 实验表明,LPE-SQL显著提升了文本到SQL的性能,甚至使小模型超越了大模型。
📝 摘要(中文)
大型语言模型(LLMs)在许多任务中表现出令人印象深刻的问题解决能力,但在各种下游应用中,例如文本到SQL,与人类相比仍然表现不佳。在BIRD基准测试排行榜上,人类的准确率达到92.96%,而表现最佳的方法仅达到72.39%。值得注意的是,这些最先进(SoTA)的方法主要依赖于上下文学习来模拟类似人类的推理。然而,它们忽略了一项关键的人类技能:持续学习。受到我们在形成时期保持错题本的教育实践的启发,我们提出了LPE-SQL(Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL),这是一种新颖的框架,旨在通过启用持续学习来增强LLM,而无需参数微调。LPE-SQL由四个模块组成,它们 extbf{i)}检索相关条目, extbf{ii)}高效的SQL生成, extbf{iii)}通过交叉一致性机制生成最终结果,以及 extbf{iv)}记录成功的和失败的任务以及它们的推理过程或反思生成的提示。重要的是,LPE-SQL的核心模块是第四个模块,而其他模块采用基础方法,允许LPE-SQL轻松与SoTA技术集成,以进一步提高性能。我们的实验结果表明,这种持续学习方法产生了显着的性能提升,较小的Llama-3.1-70B模型超越了使用SoTA方法的较大的Llama-3.1-405B模型的性能。
🔬 方法详解
问题定义:论文旨在解决文本到SQL任务中,现有大型语言模型(LLM)依赖上下文学习,缺乏持续学习能力的问题。现有方法无法有效利用历史经验,导致在复杂SQL生成任务中性能受限,与人类水平存在较大差距。
核心思路:论文的核心思路是借鉴人类的错题本学习方法,构建一个可扩展的辅助知识库,用于记录成功和失败的文本到SQL任务及其推理过程。通过检索相关经验,指导LLM生成更准确的SQL语句,实现持续学习。
技术框架:LPE-SQL框架包含四个主要模块:1) 相关条目检索模块:从知识库中检索与当前任务相关的历史经验。2) 高效SQL生成模块:利用检索到的经验,指导LLM生成SQL语句。3) 交叉一致性模块:通过多种方法生成SQL,并进行一致性校验,选择最优结果。4) 经验记录模块:记录成功和失败的任务,以及推理过程或反思生成的提示,用于更新知识库。
关键创新:LPE-SQL的关键创新在于引入了持续学习机制,通过可扩展的辅助知识库,使LLM能够不断学习和改进,而无需进行参数微调。这种方法模拟了人类的错题本学习方式,能够有效利用历史经验,提升文本到SQL的性能。
关键设计:LPE-SQL的关键设计包括:知识库的存储结构和检索算法,用于高效地存储和检索历史经验;交叉一致性模块中多种SQL生成方法的选择和一致性校验策略;以及经验记录模块中,如何有效地记录和利用推理过程或反思生成的提示。
🖼️ 关键图片

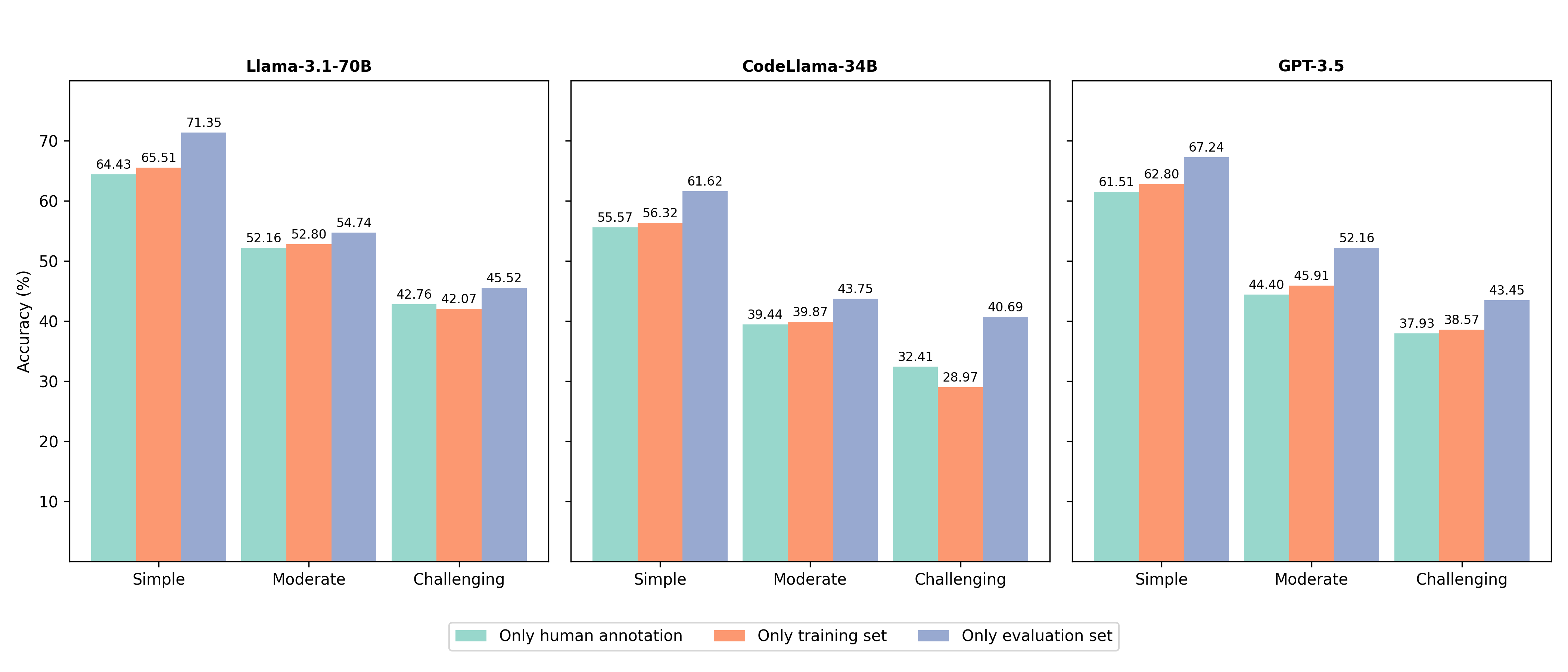
📊 实验亮点
实验结果表明,LPE-SQL能够显著提升文本到SQL的性能。例如,使用LPE-SQL的Llama-3.1-70B模型,其性能超越了使用SoTA方法的更大的Llama-3.1-405B模型。这表明LPE-SQL能够有效利用历史经验,提升LLM的持续学习能力,从而在资源有限的情况下,获得更好的性能。
🎯 应用场景
LPE-SQL可应用于智能客服、数据库查询、商业智能等领域。通过提升文本到SQL的准确率,可以更方便地从数据库中提取信息,为决策提供支持。未来,该方法可以扩展到其他自然语言处理任务,提升LLM的持续学习能力和泛化性能。
📄 摘要(原文)
Large Language Models (LLMs) exhibit impressive problem-solving skills across many tasks, but they still underperform compared to humans in various downstream applications, such as text-to-SQL. On the BIRD benchmark leaderboard, human performance achieves an accuracy of 92.96\%, whereas the top-performing method reaches only 72.39\%. Notably, these state-of-the-art (SoTA) methods predominantly rely on in-context learning to simulate human-like reasoning. However, they overlook a critical human skill: continual learning. Inspired by the educational practice of maintaining mistake notebooks during our formative years, we propose LPE-SQL (Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL), a novel framework designed to augment LLMs by enabling continual learning without requiring parameter fine-tuning. LPE-SQL consists of four modules that \textbf{i)} retrieve relevant entries, \textbf{ii)} efficient sql generation, \textbf{iii)} generate the final result through a cross-consistency mechanism and \textbf{iv)} log successful and failed tasks along with their reasoning processes or reflection-generated tips. Importantly, the core module of LPE-SQL is the fourth one, while the other modules employ foundational methods, allowing LPE-SQL to be easily integrated with SoTA technologies to further enhance performance. Our experimental results demonstrate that this continual learning approach yields substantial performance gains, with the smaller Llama-3.1-70B model with surpassing the performance of the larger Llama-3.1-405B model using SoTA methods.