Ranking Unraveled: Recipes for LLM Rankings in Head-to-Head AI Combat
作者: Roland Daynauth, Christopher Clarke, Krisztian Flautner, Lingjia Tang, Jason Mars
分类: cs.CL, cs.AI
发布日期: 2024-11-19 (更新: 2025-02-17)
💡 一句话要点
探索LLM头对头对比排序方法,提升模型选择的准确性和效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评估 成对排序 Elo算法 头对头比较
📋 核心要点
- 现有LLM评估方法难以准确反映人类偏好,成对排序虽有潜力,但在LLM评估中面临挑战。
- 论文核心在于研究不同排序算法在LLM头对头比较中的有效性,并定义有效排序的基本原则。
- 通过大量实验,分析影响排序准确性和效率的关键因素,为LLM选择提供指导。
📝 摘要(中文)
选择合适的LLM是一个复杂的问题。成对排序已成为评估人类对LLM偏好的新兴方法。该方法涉及人类根据预定义的标准评估模型输出对。通过收集这些比较结果,可以使用诸如Elo之类的方法构建排名。然而,在LLM评估的背景下应用这些算法会带来一些挑战。本文探讨了排序系统在LLM头对头比较中的有效性。我们正式定义了一套有效排序的基本原则,并对几种排序算法在LLM环境中的鲁棒性进行了一系列广泛的评估。我们的分析揭示了影响排序准确性和效率的关键因素,为基于特定评估环境和资源约束选择最合适的方法提供了指导。
🔬 方法详解
问题定义:论文旨在解决如何更有效地对大型语言模型(LLM)进行排序,以便更好地选择适合特定任务的模型。现有的LLM评估方法,例如基于单一指标的评估,往往难以捕捉人类的细微偏好。成对比较方法虽然能够反映人类偏好,但在实际应用中,不同的排序算法表现各异,且缺乏针对LLM评估的系统性研究和指导。
核心思路:论文的核心思路是通过系统性地研究不同的排序算法在LLM头对头比较中的表现,从而为LLM评估提供更有效的排序方法。通过定义有效排序的基本原则,并分析影响排序准确性和效率的关键因素,为用户提供选择排序算法的指导。
技术框架:论文的技术框架主要包括以下几个阶段:1) 定义有效排序的基本原则;2) 选择多种排序算法,例如Elo算法;3) 构建LLM头对头比较数据集;4) 在数据集上评估不同排序算法的性能;5) 分析影响排序准确性和效率的关键因素;6) 提出基于特定评估环境和资源约束选择排序算法的指导。
关键创新:论文的关键创新在于:1) 系统性地研究了不同排序算法在LLM头对头比较中的表现,填补了该领域的空白;2) 定义了有效排序的基本原则,为排序算法的选择和优化提供了理论基础;3) 分析了影响排序准确性和效率的关键因素,为实际应用提供了指导。
关键设计:论文的关键设计包括:1) 选择了Elo算法等经典的排序算法作为研究对象;2) 构建了包含大量LLM头对头比较结果的数据集,保证了实验的可靠性;3) 采用了多种评估指标,例如排序准确率和排序效率,全面评估了排序算法的性能;4) 针对不同的评估环境和资源约束,提出了选择排序算法的指导。
🖼️ 关键图片
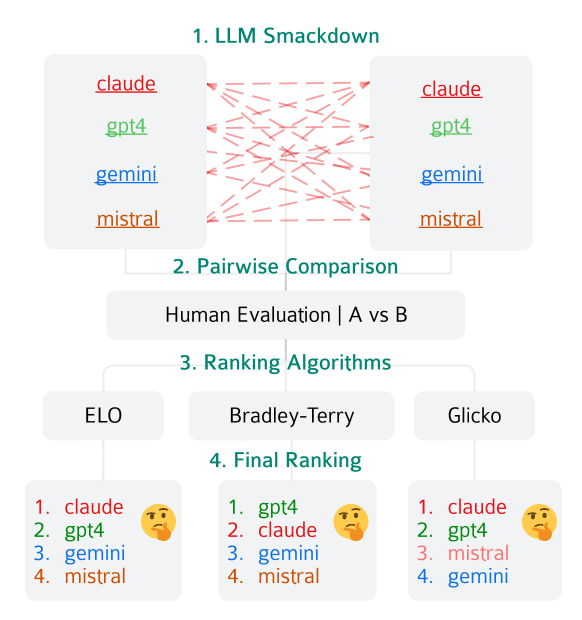
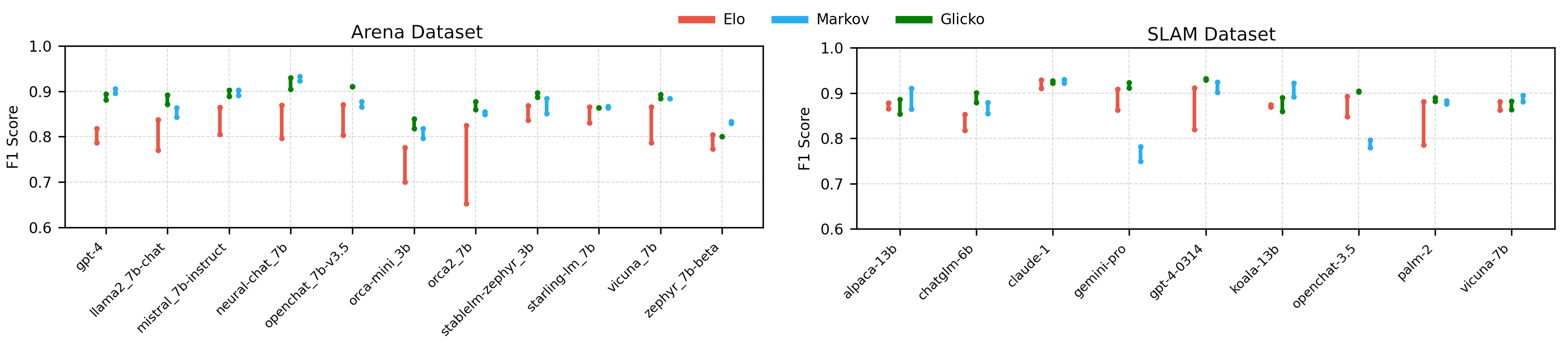
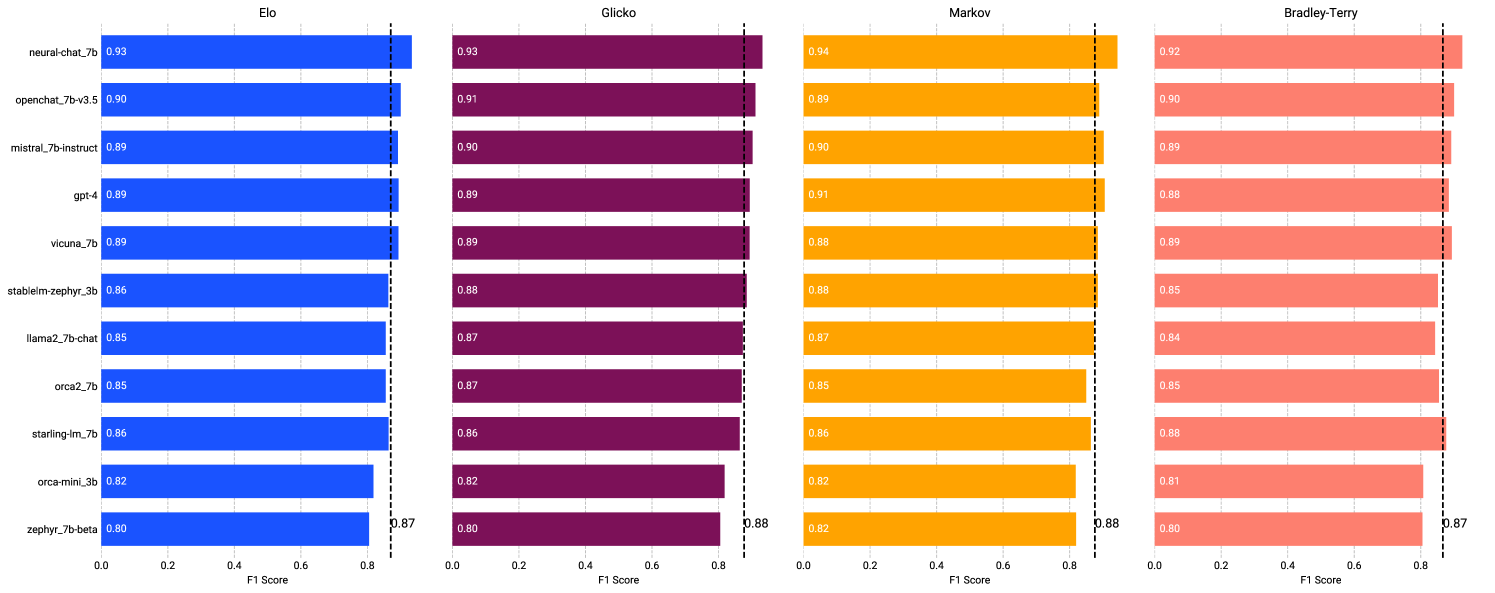
📊 实验亮点
论文通过实验分析了多种排序算法在LLM头对头比较中的表现,揭示了影响排序准确性和效率的关键因素。研究结果表明,不同的排序算法在不同的评估环境下表现各异,需要根据具体情况选择合适的算法。论文还提出了选择排序算法的指导,为实际应用提供了参考。
🎯 应用场景
该研究成果可应用于各种需要选择最佳LLM的场景,例如智能客服、文本生成、机器翻译等。通过更准确地评估LLM的性能,可以提高应用系统的性能和用户体验。此外,该研究还可以为LLM的开发和优化提供指导,促进LLM技术的进步。
📄 摘要(原文)
Deciding which large language model (LLM) to use is a complex challenge. Pairwise ranking has emerged as a new method for evaluating human preferences for LLMs. This approach entails humans evaluating pairs of model outputs based on a predefined criterion. By collecting these comparisons, a ranking can be constructed using methods such as Elo. However, applying these algorithms as constructed in the context of LLM evaluation introduces several challenges. In this paper, we explore the effectiveness of ranking systems for head-to-head comparisons of LLMs. We formally define a set of fundamental principles for effective ranking and conduct a series of extensive evaluations on the robustness of several ranking algorithms in the context of LLMs. Our analysis uncovers key insights into the factors that affect ranking accuracy and efficiency, offering guidelines for selecting the most appropriate methods based on specific evaluation contexts and resource constraints.