GRL-Prompt: Towards Knowledge Graph based Prompt Optimization via Reinforcement Learning
作者: Yuze Liu, Tingjie Liu, Tiehua Zhang, Youhua Xia, Jinze Wang, Zhishu Shen, Jiong Jin, Fei Richard Yu
分类: cs.CL, cs.AI
发布日期: 2024-11-19
💡 一句话要点
提出GRL-Prompt,利用强化学习和知识图谱优化大语言模型提示词。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示词工程 强化学习 知识图谱 大语言模型 自动优化
📋 核心要点
- 现有大语言模型(LLMs)的性能高度依赖于输入提示词,但手动提示词工程耗时且难以找到最优解。
- GRL-Prompt利用知识图谱编码用户查询与上下文示例的相关性,并使用强化学习自动构建最优提示词。
- 实验结果表明,GRL-Prompt在多个指标上优于现有方法,例如ROUGE和BLEU评分均有显著提升。
📝 摘要(中文)
本文提出了一种与大语言模型(LLMs)无关的提示词优化框架GRL-Prompt,旨在通过强化学习(RL)自动构建最优提示词。为了提供结构化的动作/状态表示以优化提示词,构建了一个知识图谱(KG),更好地编码用户查询和候选上下文示例之间的相关性。此外,设计了一个策略网络,通过以可奖励的顺序选择一组上下文示例来生成最优动作,从而构建提示词。同时,利用基于嵌入的奖励塑造来稳定RL训练过程。实验结果表明,GRL-Prompt优于最新的方法,在ROUGE-1上平均提高了0.10,ROUGE-2上提高了0.07,ROUGE-L上提高了0.07,BLEU上提高了0.05。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)中提示词工程的难题。现有方法主要依赖人工试错,效率低下且难以找到全局最优的提示词组合。这种手动方式不仅耗费大量人力,而且缺乏系统性和可解释性,阻碍了LLMs潜力的充分发挥。
核心思路:论文的核心思路是将提示词优化问题建模成一个强化学习(RL)任务。通过构建知识图谱(KG)来表示用户查询与候选上下文示例之间的关系,并利用RL智能体学习选择最优的上下文示例组合,从而自动生成高质量的提示词。这种方法旨在摆脱人工干预,实现提示词的自动优化。
技术框架:GRL-Prompt框架主要包含以下几个模块:1) 知识图谱构建模块:用于构建用户查询和候选上下文示例之间的知识图谱,捕捉它们之间的语义关系。2) 强化学习智能体:包含策略网络和奖励函数,策略网络负责选择上下文示例,奖励函数用于评估选择的质量。3) 提示词构建模块:根据RL智能体选择的上下文示例,构建最终的提示词。4) 奖励塑造模块:利用基于嵌入的奖励塑造技术,稳定强化学习的训练过程。
关键创新:该论文的关键创新在于将知识图谱和强化学习相结合,用于提示词的自动优化。与传统的基于规则或搜索的提示词工程方法相比,GRL-Prompt能够更有效地利用知识图谱中的信息,并通过强化学习自动探索最优的提示词组合。此外,该框架具有LLM无关性,可以应用于不同的LLM。
关键设计:知识图谱的构建方式,如何将用户查询和候选示例映射到图谱节点,以及如何定义节点之间的关系是关键设计之一。策略网络的设计,包括网络结构、激活函数和优化算法的选择,直接影响RL智能体的学习效果。奖励函数的设计,如何准确评估提示词的质量,并引导智能体学习,也是至关重要的。此外,基于嵌入的奖励塑造技术,如何选择合适的嵌入模型和奖励函数,对稳定训练过程至关重要。
🖼️ 关键图片

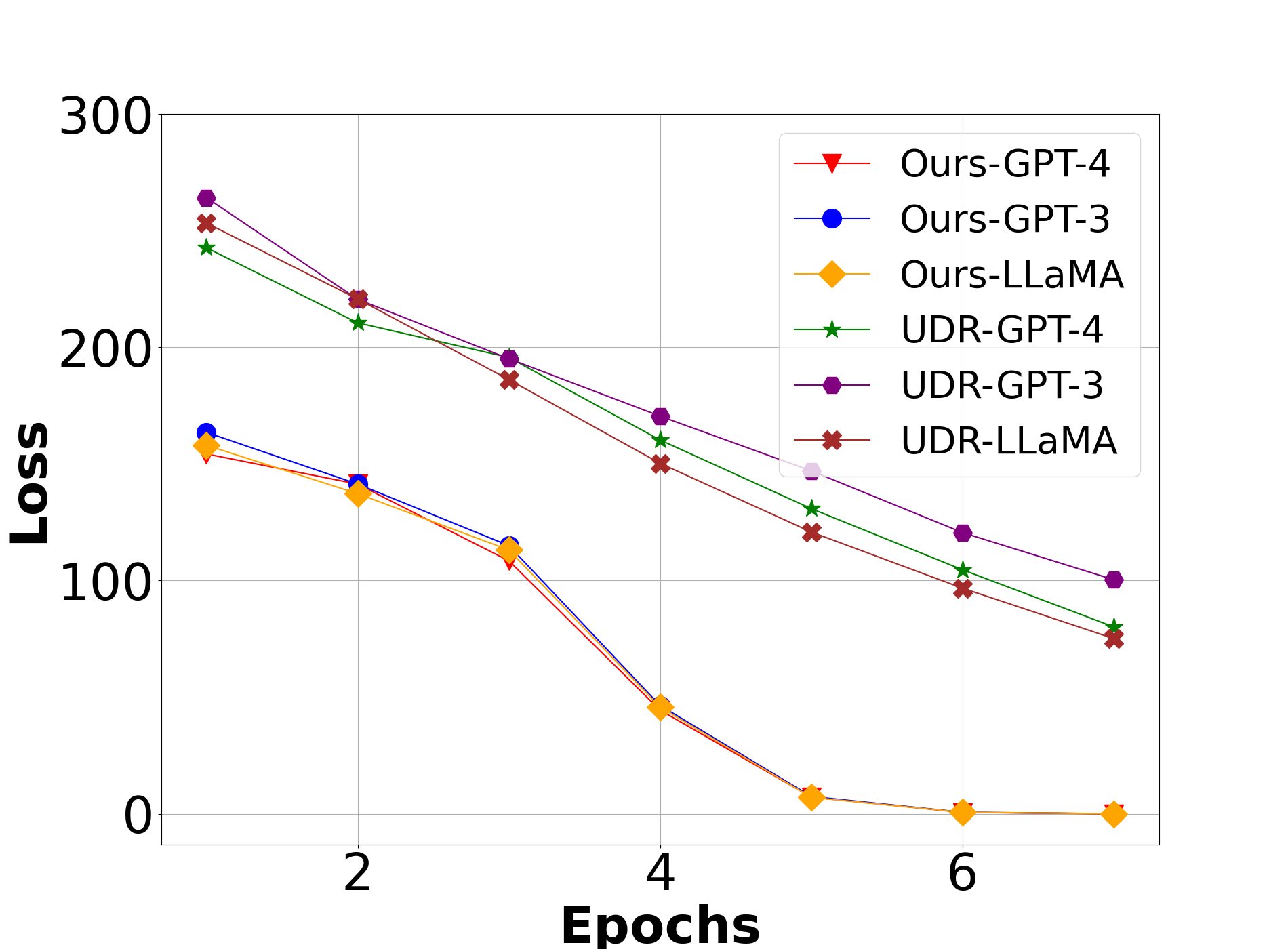

📊 实验亮点
实验结果表明,GRL-Prompt在文本摘要任务上取得了显著的性能提升。与现有的最佳方法相比,GRL-Prompt在ROUGE-1上平均提高了0.10,ROUGE-2上提高了0.07,ROUGE-L上提高了0.07,BLEU上提高了0.05。这些结果表明,GRL-Prompt能够有效地优化提示词,提高LLMs的性能。
🎯 应用场景
GRL-Prompt具有广泛的应用前景,可以应用于各种需要提示词工程的大语言模型任务,例如文本生成、问答系统、文本摘要等。该研究能够降低提示词工程的门槛,使非专业人士也能充分利用LLMs的能力。此外,自动提示词优化可以提高LLMs的性能和效率,从而推动LLMs在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive success in a wide range of natural language processing (NLP) tasks due to their extensive general knowledge of the world. Recent works discovered that the performance of LLMs is heavily dependent on the input prompt. However, prompt engineering is usually done manually in a trial-and-error fashion, which can be labor-intensive and challenging in order to find the optimal prompts. To address these problems and unleash the utmost potential of LLMs, we propose a novel LLMs-agnostic framework for prompt optimization, namely GRL-Prompt, which aims to automatically construct optimal prompts via reinforcement learning (RL) in an end-to-end manner. To provide structured action/state representation for optimizing prompts, we construct a knowledge graph (KG) that better encodes the correlation between the user query and candidate in-context examples. Furthermore, a policy network is formulated to generate the optimal action by selecting a set of in-context examples in a rewardable order to construct the prompt. Additionally, the embedding-based reward shaping is utilized to stabilize the RL training process. The experimental results show that GRL-Prompt outperforms recent state-of-the-art methods, achieving an average increase of 0.10 in ROUGE-1, 0.07 in ROUGE-2, 0.07 in ROUGE-L, and 0.05 in BLEU.