ACING: Actor-Critic for Instruction Learning in Black-Box LLMs
作者: Salma Kharrat, Fares Fourati, Marco Canini
分类: cs.CL, cs.AI, cs.LG, eess.SY, math.OC
发布日期: 2024-11-19 (更新: 2025-09-04)
备注: Accepted at EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
ACING:用于黑盒LLM指令学习的Actor-Critic方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令学习 黑盒LLM 强化学习 Actor-Critic 指令优化
📋 核心要点
- 现有指令优化方法在黑盒LLM场景下受限,无法访问模型参数和梯度,优化难度大。
- ACING采用Actor-Critic强化学习框架,将指令优化视为连续动作空间的无状态问题。
- 实验表明,ACING在多种任务上优于人工编写的提示和其他自动基线,提升显著。
📝 摘要(中文)
大型语言模型(LLM)在解决任务方面的有效性很大程度上取决于指令的质量,而指令的制作通常需要大量的人力。这突显了自动指令优化的必要性。然而,当处理黑盒LLM时,优化指令尤其具有挑战性,因为模型参数和梯度是不可访问的。我们引入了ACING,一个actor-critic强化学习框架,它将指令优化公式化为一个无状态的、连续动作的问题,从而能够仅使用黑盒反馈来探索无限的指令空间。ACING自动发现的提示在76%的指令归纳任务中优于人工编写的提示,在涵盖指令归纳、摘要和思维链推理的33个任务中,增益高达33个点,并且比最佳自动基线提高了10个点的中位数。大量的消融实验突出了其鲁棒性和效率。ACING的实现可在https://github.com/salmakh1/ACING 获得。
🔬 方法详解
问题定义:论文旨在解决黑盒大型语言模型(LLM)的指令优化问题。现有方法在黑盒场景下无法有效利用模型内部信息(如梯度),依赖大量人工设计或离散搜索,效率低下且难以泛化到不同任务。因此,如何在无法访问模型参数和梯度的情况下,自动优化LLM的指令,是一个重要的挑战。
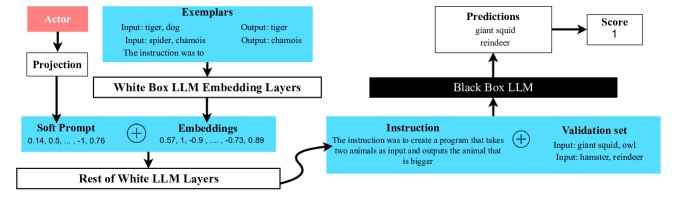
核心思路:ACING的核心思路是将指令优化问题建模为一个连续动作空间的强化学习问题。Actor网络负责生成指令(动作),Critic网络负责评估指令的质量(状态价值)。通过Actor-Critic算法,不断迭代优化指令,使其在黑盒LLM上获得更好的性能。这种方法避免了直接操作LLM的参数,仅依赖黑盒反馈,具有更好的通用性和可扩展性。
技术框架:ACING的整体框架包含以下几个主要模块:1) Actor网络:负责生成连续的指令向量。2) Critic网络:评估Actor生成的指令的质量,输出状态价值。3) 黑盒LLM:接收指令并执行任务,提供反馈信号。4) 强化学习算法:使用Actor-Critic算法,根据LLM的反馈信号,更新Actor和Critic网络的参数。整个流程是一个迭代优化的过程,Actor不断生成更好的指令,Critic提供更准确的评估,最终使LLM在任务上表现更佳。
关键创新:ACING的关键创新在于将指令优化问题建模为连续动作空间的强化学习问题,并采用Actor-Critic算法进行求解。与传统的离散搜索或人工设计方法相比,ACING能够更有效地探索指令空间,发现更优的指令。此外,ACING仅依赖黑盒反馈,无需访问LLM的内部参数,使其能够应用于各种黑盒LLM,具有更广泛的适用性。
关键设计:ACING的关键设计包括:1) 指令表示:使用连续向量表示指令,允许Actor网络生成更丰富的指令。2) 奖励函数:根据LLM的输出结果,设计合适的奖励函数,引导Actor网络生成更有效的指令。3) Actor-Critic算法:采用合适的Actor-Critic算法(如PPO),平衡探索和利用,稳定训练过程。4) 网络结构:Actor和Critic网络采用合适的神经网络结构(如Transformer),以捕捉指令和任务之间的复杂关系。
🖼️ 关键图片

📊 实验亮点
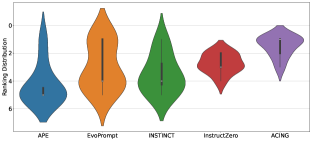
ACING在指令归纳任务中,76%的情况下优于人工编写的提示。在涵盖指令归纳、摘要和思维链推理的33个任务中,相比最佳自动基线,ACING的性能提升高达33个点,中位数提升为10个点。消融实验验证了ACING的鲁棒性和效率。
🎯 应用场景
ACING可应用于各种需要指令引导的大型语言模型任务,例如文本摘要、问题回答、代码生成等。它能够自动优化指令,提高LLM的性能,降低人工成本。该研究的潜在价值在于提升LLM的易用性和智能化水平,使其能够更好地服务于各行各业。未来,ACING可以扩展到多模态指令优化,进一步提升LLM的通用性和适应性。
📄 摘要(原文)
The effectiveness of Large Language Models (LLMs) in solving tasks depends significantly on the quality of their instructions, which often require substantial human effort to craft. This underscores the need for automated instruction optimization. However, optimizing instructions is particularly challenging when working with black-box LLMs, where model parameters and gradients are inaccessible. We introduce ACING, an actor-critic reinforcement learning framework that formulates instruction optimization as a stateless, continuous-action problem, enabling exploration of infinite instruction spaces using only black-box feedback. ACING automatically discovers prompts that outperform human-written prompts in 76% of instruction-induction tasks, with gains of up to 33 points and a 10-point median improvement over the best automatic baseline in 33 tasks spanning instruction-induction, summarization, and chain-of-thought reasoning. Extensive ablations highlight its robustness and efficiency. An implementation of ACING is available at https://github.com/salmakh1/ACING.