RedPajama: an Open Dataset for Training Large Language Models
作者: Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, Ce Zhang
分类: cs.CL, cs.LG
发布日期: 2024-11-19
备注: 38th Conference on Neural Information Processing Systems (NeurIPS 2024) Track on Datasets and Benchmarks
💡 一句话要点
RedPajama:发布大规模开放数据集,促进透明、高性能大语言模型的发展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 开放数据集 数据质量 透明性 可复现性 LLaMA 数据清洗
📋 核心要点
- 现有大语言模型在数据集构建和模型开发上缺乏透明度,阻碍了开源模型的发展,难以复现和改进。
- RedPajama项目旨在通过发布大规模、高质量的开放数据集,以及数据质量信号和元数据,促进透明和可复现的大语言模型研究。
- 通过对RedPajama数据集进行分析和消融实验,验证了其质量和有效性,并展示了如何利用质量信号来构建高质量的数据子集。
📝 摘要(中文)
大型语言模型正日益成为人工智能、科学和社会的基石技术,然而数据集构成和过滤的最佳策略仍然难以捉摸。许多表现最佳的模型在数据集管理和模型开发过程中缺乏透明度,这阻碍了完全开放的语言模型的发展。本文确定了三个与数据相关的核心挑战,这些挑战必须解决才能推进开源语言模型的发展。这些挑战包括:(1) 模型开发的透明度,包括数据管理过程;(2) 访问大量高质量数据;(3) 数据集管理和分析的工件和元数据的可用性。为了应对这些挑战,我们发布了 RedPajama-V1,这是 LLaMA 训练数据集的开放复现。此外,我们还发布了 RedPajama-V2,这是一个仅包含原始、未过滤文本数据以及质量信号和元数据的大规模网络数据集。RedPajama 数据集总共包含超过 100 万亿个 tokens,跨越多个领域,其质量信号有助于过滤数据,旨在激发众多新数据集的开发。迄今为止,这些数据集已被用于训练强大的语言模型,例如 Snowflake Arctic、Salesforce 的 XGen 和 AI2 的 OLMo。为了深入了解 RedPajama 的质量,我们使用高达 1.6B 参数的仅解码器语言模型进行了一系列分析和消融研究。我们的研究结果表明,可以有效地利用网络数据的质量信号来管理数据集的高质量子集,突显了 RedPajama 在大规模推进透明和高性能语言模型开发方面的潜力。
🔬 方法详解
问题定义:现有的大语言模型训练数据集往往不公开,导致研究人员难以了解数据质量、来源和处理方式,阻碍了模型的复现和改进。此外,获取大规模高质量的训练数据也是一个挑战,尤其对于资源有限的研究团队。
核心思路:RedPajama项目的核心思路是构建一个完全开放、可复现的大语言模型训练数据集,并提供详细的数据质量信息和元数据,从而促进透明和可信赖的大语言模型研究。通过开放数据,降低了研究门槛,鼓励更多研究者参与到模型改进和数据集优化的工作中。
技术框架:RedPajama项目主要包含两个数据集:RedPajama-V1和RedPajama-V2。RedPajama-V1是LLaMA训练数据集的开放复现版本,RedPajama-V2是一个大规模的、仅包含网络数据的原始数据集,包含质量信号和元数据。该项目还包括用于分析和评估数据集质量的工具和脚本。
关键创新:RedPajama项目的关键创新在于其完全开放的数据集和详细的元数据。这使得研究人员可以深入了解数据的来源、质量和处理方式,从而更好地理解模型的行为和性能。此外,该项目还提供了一系列用于评估数据质量的指标,例如文本重复率、语言质量等。
关键设计:RedPajama-V2数据集包含多种质量信号,例如基于语言模型的困惑度、文本重复率等。这些质量信号可以用于过滤和选择高质量的数据子集。此外,该项目还提供了一系列用于数据清洗和预处理的工具,例如去除HTML标签、过滤低质量文本等。研究人员可以根据自己的需求选择合适的参数和配置。
🖼️ 关键图片

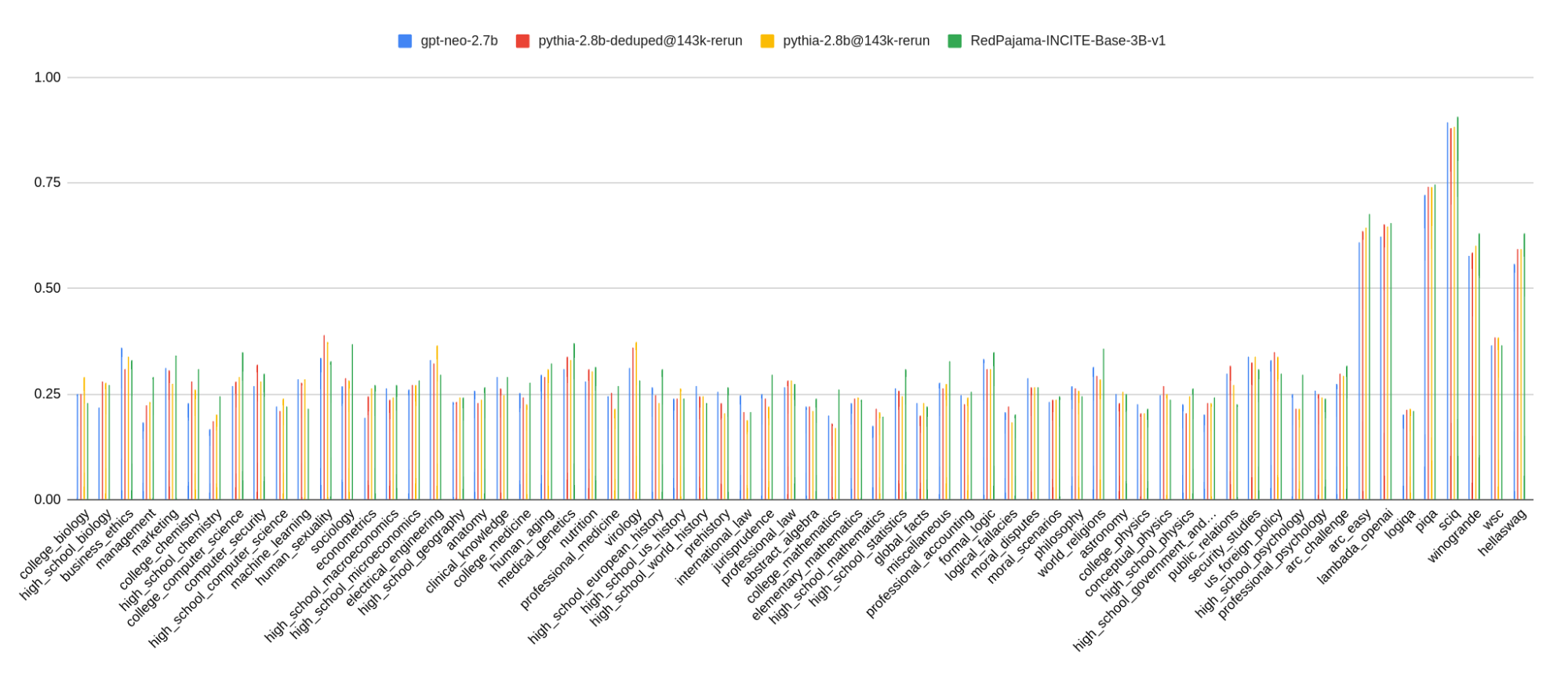
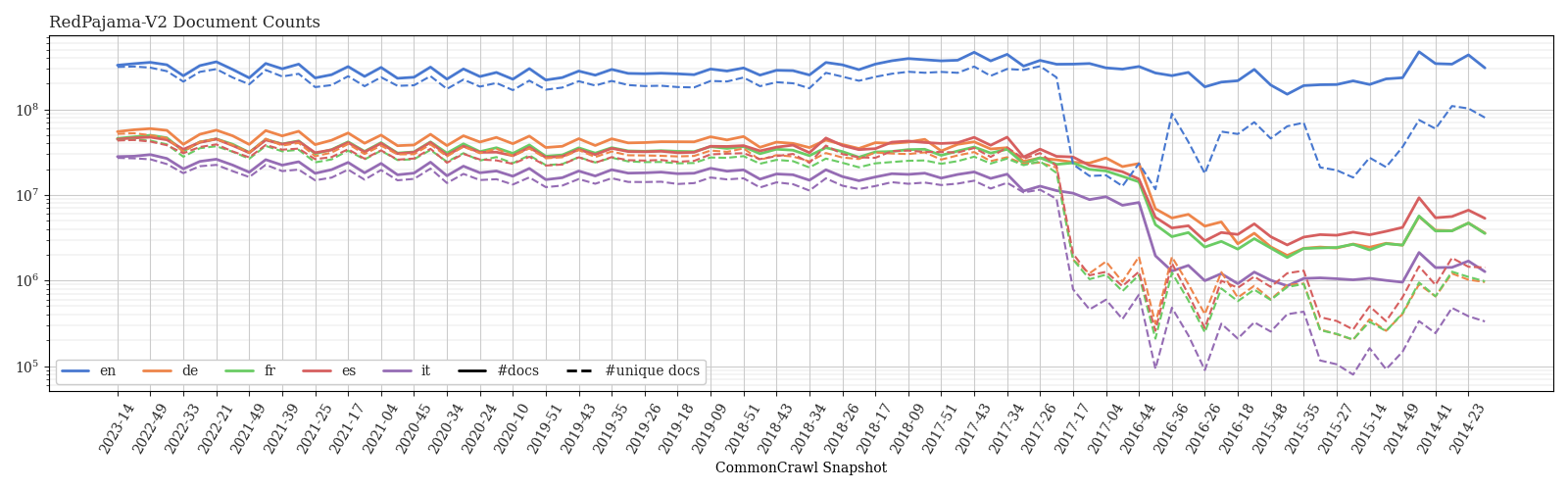
📊 实验亮点
论文通过对RedPajama数据集进行消融实验,验证了数据质量对模型性能的影响。实验结果表明,使用高质量的数据子集训练的模型,其性能明显优于使用低质量数据训练的模型。例如,通过过滤掉低质量文本,可以显著提高模型的困惑度和生成文本的流畅度。该研究还展示了如何利用质量信号来构建高质量的数据子集。
🎯 应用场景
RedPajama数据集可广泛应用于大语言模型的训练、评估和分析。它可以帮助研究人员构建更透明、可信赖的模型,并促进开源大语言模型的发展。此外,该数据集还可以用于研究数据质量对模型性能的影响,以及开发更有效的数据清洗和预处理方法。该数据集已被用于 Snowflake Arctic, Salesforce's XGen 和 AI2's OLMo 等生产级模型。
📄 摘要(原文)
Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.