Balancing Accuracy and Efficiency in Multi-Turn Intent Classification for LLM-Powered Dialog Systems in Production
作者: Junhua Liu, Yong Keat Tan, Bin Fu, Kwan Hui Lim
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-11-19
💡 一句话要点
针对LLM驱动的对话系统,提出Symbol Tuning和C-LARA以平衡准确率和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮意图分类 大型语言模型 数据增强 伪标签 符号调优 对话系统 低资源语言
📋 核心要点
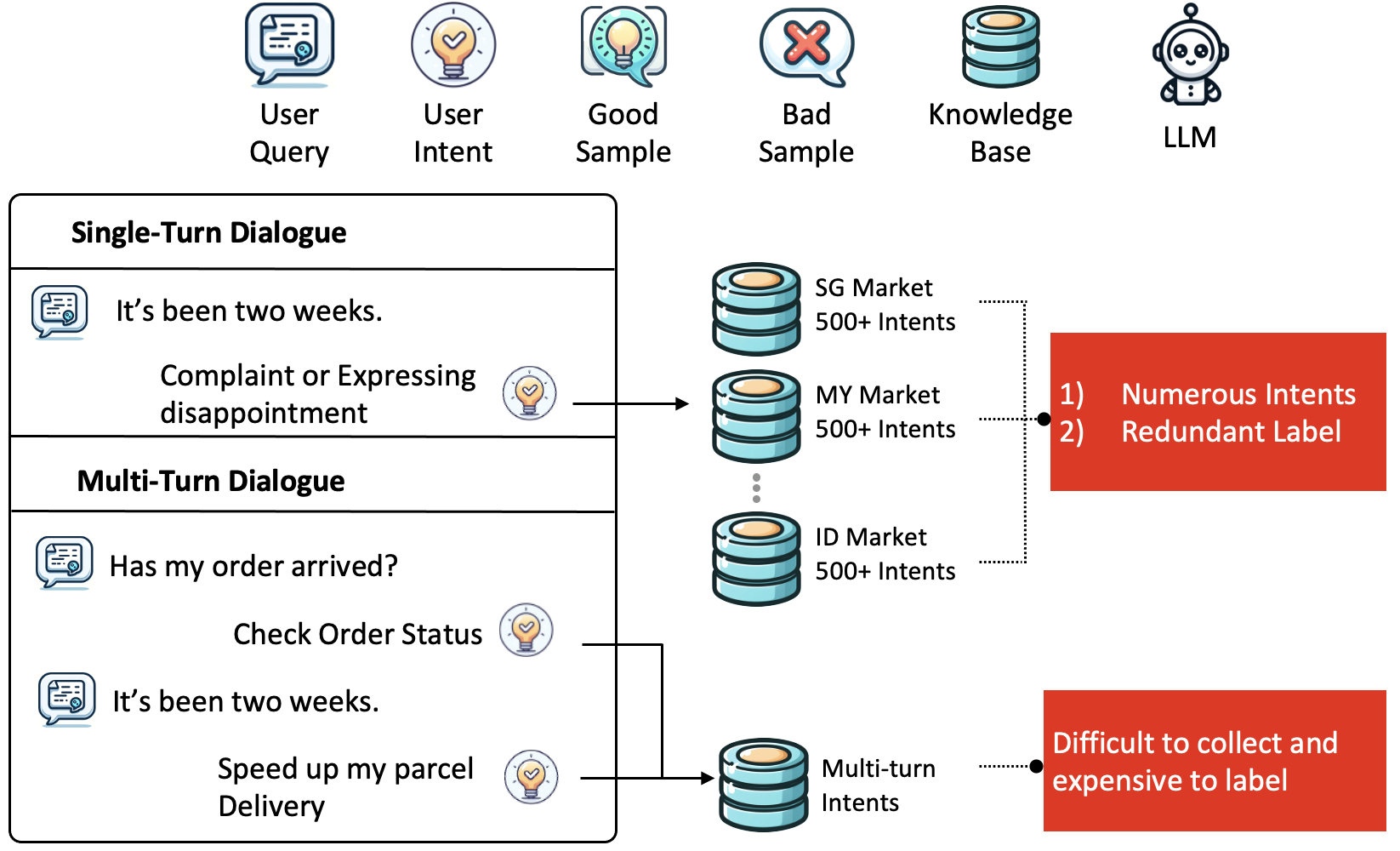
- 多轮意图分类面临数据集不足和上下文依赖复杂等挑战,现有方法难以兼顾准确性和效率。
- 论文提出Symbol Tuning简化意图标签,并设计C-LARA框架进行数据增强和伪标签,以提升模型性能。
- 实验表明,该方法在多语言数据集上显著提升了分类精度和资源效率,降低了标注成本。
📝 摘要(中文)
本文针对对话AI系统中多轮意图分类的准确性问题,以及数据集稀缺和上下文依赖复杂等挑战,提出了两种利用大型语言模型(LLM)的新方法,旨在提高可扩展性并降低生产对话系统的延迟。首先,引入了符号调优(Symbol Tuning),通过简化意图标签来降低任务复杂性,从而提高多轮对话中的性能。其次,提出了C-LARA(一致性感知、语言自适应检索增强)框架,该框架利用LLM进行数据增强和伪标签生成合成的多轮对话。这些丰富的数据集用于微调小型高效的模型,适合部署。在多语言对话数据集上进行的实验表明,分类精度和资源效率得到了显著提高。该方法将多轮意图分类精度提高了5.09%,降低了40%的标注成本,并实现了低资源多语言工业系统中的可扩展部署,突出了其在实际应用中的价值和影响。
🔬 方法详解
问题定义:论文旨在解决在生产环境中,LLM驱动的对话系统中多轮意图分类的准确性和效率问题。现有方法在处理复杂的多轮对话上下文时,往往面临准确率不足的问题,同时,由于标注数据的稀缺,模型的泛化能力受到限制。此外,直接使用大型LLM进行推理会带来较高的延迟和计算成本,不适合大规模部署。
核心思路:论文的核心思路是利用LLM的强大生成能力进行数据增强,并简化意图标签以降低任务的复杂度。通过生成高质量的伪标签数据,可以有效缓解数据稀缺的问题,提升模型的泛化能力。同时,通过简化意图标签,可以降低模型的学习难度,提高分类的准确率和效率。
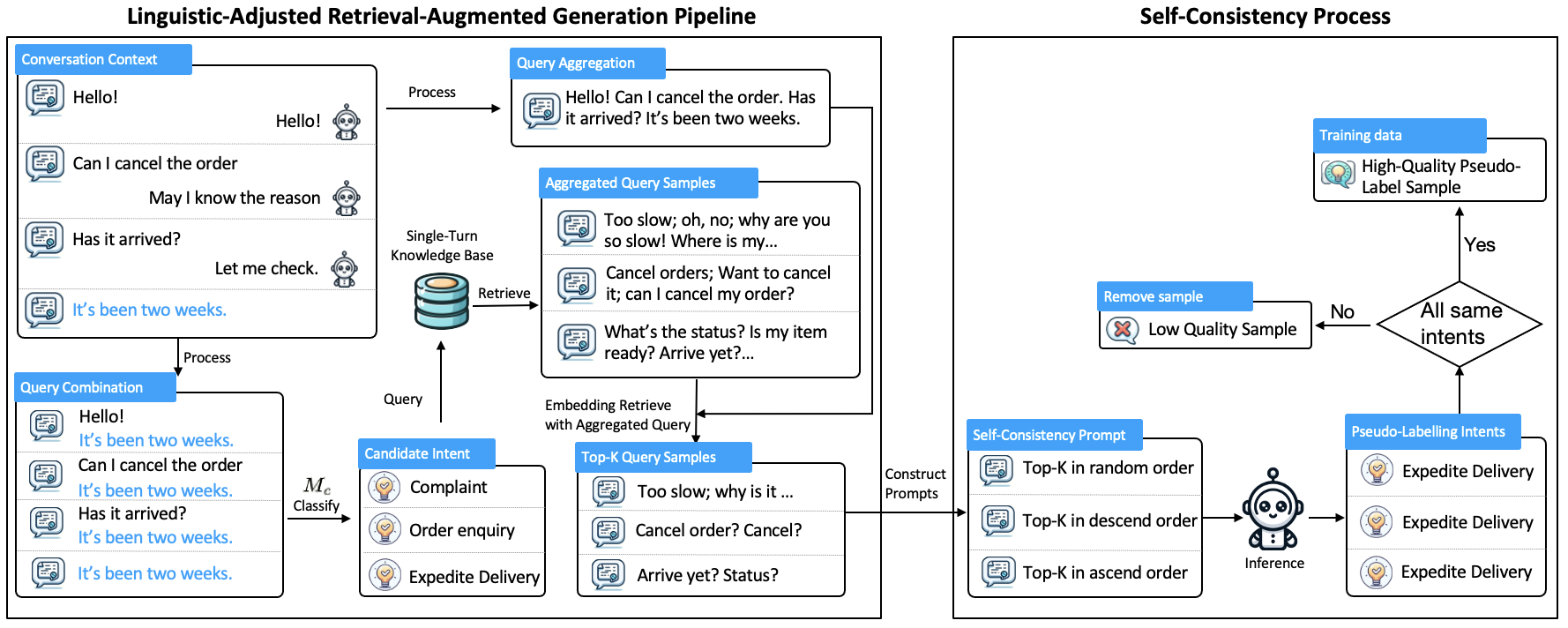
技术框架:整体框架包含两个主要部分:Symbol Tuning和C-LARA。Symbol Tuning负责简化意图标签,将复杂的意图标签映射到更简单的符号表示。C-LARA框架则包含三个阶段:1) 数据增强阶段,利用LLM生成多样化的多轮对话数据;2) 伪标签生成阶段,利用LLM对生成的数据进行意图标注;3) 模型微调阶段,使用增强的数据集和伪标签微调小型高效的模型。
关键创新:论文的关键创新在于C-LARA框架,它是一种一致性感知、语言自适应的检索增强方法。C-LARA利用LLM的上下文理解能力,生成与原始对话上下文一致的对话数据,并根据不同语言的特点进行自适应调整,从而保证生成数据的质量。此外,Symbol Tuning通过简化意图标签,有效降低了任务的复杂度,提高了模型的学习效率。
关键设计:在C-LARA框架中,LLM的选择至关重要,论文使用了具有强大生成能力的LLM,例如GPT-3。在数据增强阶段,采用了多种采样策略,以保证生成数据的多样性。在伪标签生成阶段,使用了基于一致性的过滤方法,筛选出高质量的伪标签数据。在模型微调阶段,使用了交叉熵损失函数,并采用了学习率衰减等优化策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多语言对话数据集上取得了显著的性能提升。具体而言,多轮意图分类精度提高了5.09%,标注成本降低了40%。与现有基线方法相比,该方法在准确率和效率方面均表现出优势,证明了其在实际应用中的可行性和有效性。
🎯 应用场景
该研究成果可广泛应用于各种LLM驱动的对话系统中,例如智能客服、虚拟助手、任务型对话系统等。通过提高多轮意图分类的准确性和效率,可以提升用户体验,降低运营成本。此外,该方法在低资源多语言环境下的可扩展性,使其在国际化应用中具有重要价值。未来,可以进一步探索该方法在其他自然语言处理任务中的应用。
📄 摘要(原文)
Accurate multi-turn intent classification is essential for advancing conversational AI systems. However, challenges such as the scarcity of comprehensive datasets and the complexity of contextual dependencies across dialogue turns hinder progress. This paper presents two novel approaches leveraging Large Language Models (LLMs) to enhance scalability and reduce latency in production dialogue systems. First, we introduce Symbol Tuning, which simplifies intent labels to reduce task complexity and improve performance in multi-turn dialogues. Second, we propose C-LARA (Consistency-aware, Linguistics Adaptive Retrieval Augmentation), a framework that employs LLMs for data augmentation and pseudo-labeling to generate synthetic multi-turn dialogues. These enriched datasets are used to fine-tune a small, efficient model suitable for deployment. Experiments conducted on multilingual dialogue datasets demonstrate significant improvements in classification accuracy and resource efficiency. Our methods enhance multi-turn intent classification accuracy by 5.09%, reduce annotation costs by 40%, and enable scalable deployment in low-resource multilingual industrial systems, highlighting their practicality and impact.