Evaluating Tokenizer Performance of Large Language Models Across Official Indian Languages
作者: S. Tamang, D. J. Bora
分类: cs.CL, cs.AI
发布日期: 2024-11-19 (更新: 2024-11-26)
💡 一句话要点
评估大型语言模型在印度官方语言上的分词器性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 分词器 印度语言 归一化序列长度 多语言处理
📋 核心要点
- 多语言LLM在印度语言上的分词效率不足,影响模型性能,需要更优的分词策略。
- 论文核心在于对比12个LLM在22种印度官方语言上的分词器性能,使用NSL作为评估指标。
- 实验发现SUTRA分词器在多种印度语言上表现优异,超越了其他模型,包括一些专门的印度语言模型。
📝 摘要(中文)
本文全面评估了12个大型语言模型(LLM)的分词器在印度所有22种官方语言上的性能,这些LLM基于Transformer架构,分词在预处理和微调阶段起着关键作用。研究重点比较了这些分词器的效率,采用归一化序列长度(NSL)作为关键指标。结果表明,SUTRA分词器在14种语言上优于所有其他模型,包括几种特定于印度语言的模型。值得注意的是,SUTRA分词器在处理印度语言方面表现出色,GPT-4o在处理印度语言方面优于其前身GPT-4,而Project Indus在某些语言中的性能有限。这项研究强调了为多语言和以印度为中心的模型开发有针对性的分词策略的重要性,为未来改进分词器设计以增强语言覆盖范围和模型效率奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理印度官方语言时,由于分词器效率低下而导致的模型性能瓶颈问题。现有方法,包括通用分词器和一些针对印度语言的分词器,在处理所有22种印度官方语言时,表现参差不齐,无法充分优化模型性能。
核心思路:论文的核心思路是通过对现有主流LLM所使用的分词器在所有印度官方语言上进行全面的性能评估,找出在不同语言上表现最佳的分词器。通过比较归一化序列长度(NSL)这一指标,量化分词器的效率,从而为后续开发更高效的印度语言分词器提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择12个具有代表性的大型语言模型,涵盖通用模型和特定于印度语言的模型;2) 收集并准备22种印度官方语言的文本数据;3) 使用每个模型的tokenizer对文本数据进行分词;4) 计算每个tokenizer在每种语言上的归一化序列长度(NSL);5) 对比分析不同tokenizer在不同语言上的NSL值,评估其性能优劣。
关键创新:该研究的关键创新在于对大量LLM的分词器在所有印度官方语言上进行了系统性的评估,并以NSL作为统一的评估指标。以往的研究可能只关注少数几种语言或少数几个模型,而本文的覆盖范围更广,结论更具普适性。此外,发现SUTRA tokenizer在多种印度语言上表现优异,为后续研究提供了新的方向。
关键设计:论文的关键设计在于选择了归一化序列长度(NSL)作为评估分词器性能的指标。NSL定义为分词后的token数量除以原始文本的字符数量。NSL越小,表示分词器效率越高,能够用更少的token表示相同的文本信息。此外,论文还仔细选择了具有代表性的LLM,并确保了用于评估的文本数据的质量和多样性。
🖼️ 关键图片


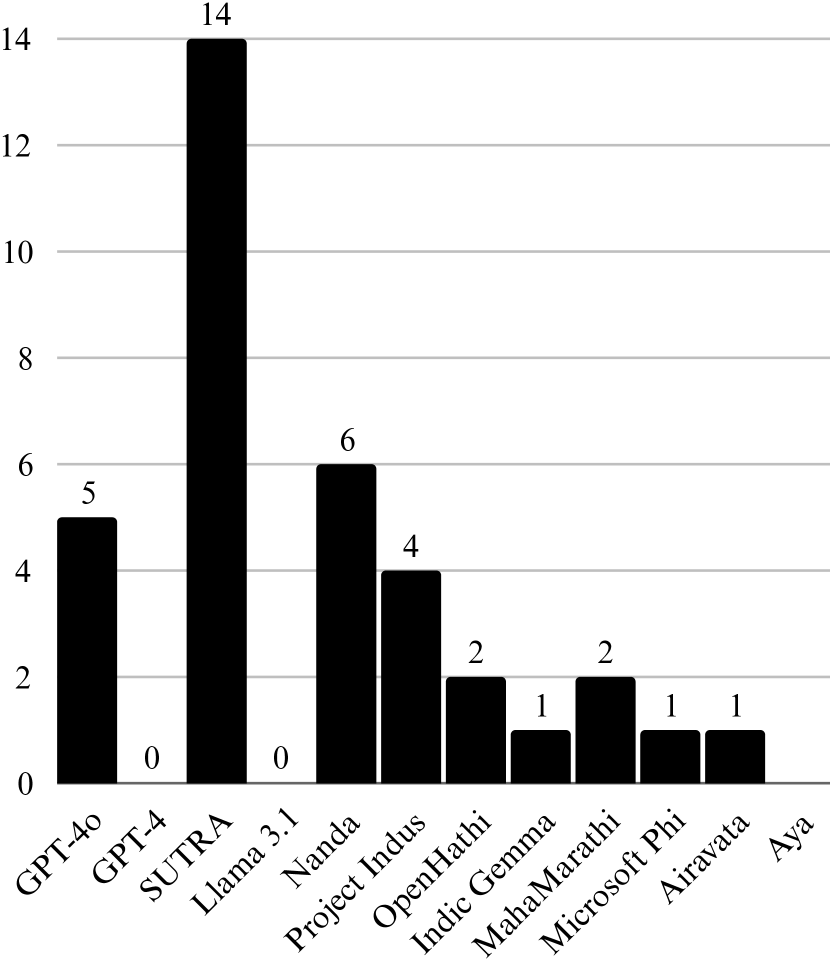
📊 实验亮点
实验结果表明,SUTRA tokenizer在14种印度官方语言上表现优于其他tokenizer,包括一些专门为印度语言设计的tokenizer。GPT-4o在处理印度语言方面也比其前身GPT-4有所提升。这些发现突出了针对特定语言优化tokenizer的重要性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于提升多语言大型语言模型在印度语言上的性能,例如机器翻译、文本摘要、问答系统等。通过选择或优化适合特定印度语言的分词器,可以显著提高模型的效率和准确性。此外,该研究也为未来开发更高效的印度语言分词器提供了重要的参考依据,促进了印度语言自然语言处理技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) based on transformer architectures have revolutionized a variety of domains, with tokenization playing a pivotal role in their pre-processing and fine-tuning stages. In multilingual models, particularly those tailored for Indic languages, effective tokenization is crucial for optimizing performance. This paper presents a comprehensive evaluation of tokenizers used by 12 LLMs across all 22 official languages of India, with a focus on comparing the efficiency of their tokenization processes. We employed the Normalized Sequence Length (NSL) as a key metric in our analysis. Our findings reveal that the SUTRA tokenizer outperforms all other models, including several Indic-specific models, excelling in 14 languages. Notable insights include the SUTRA tokenizer's superior handling of Indic languages, GPT-4o's advancement over its predecessor GPT-4 in processing Indian languages, and the limited performance of Project Indus in certain languages. This study underscores the critical importance of developing targeted tokenization strategies for multilingual and Indic-centric models, laying the groundwork for future improvements in tokenizer design to enhance linguistic coverage and model efficiency.