Testing Uncertainty of Large Language Models for Physics Knowledge and Reasoning
作者: Elizaveta Reganova, Peter Steinbach
分类: cs.CL, cs.LG
发布日期: 2024-11-18
💡 一句话要点
评估大语言模型在物理知识和推理中的不确定性,揭示准确率与置信度的关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性评估 物理知识 逻辑推理 知识检索
📋 核心要点
- 大型语言模型容易产生“幻觉”,难以评估其性能,尤其是在需要专业知识的领域。
- 该研究通过分析LLM在物理问卷上的表现,评估其预测的确定性与准确性的相关性。
- 实验发现,模型在确定时通常更准确,但这种关系并非普遍成立,且逻辑推理任务中不确定性更高。
📝 摘要(中文)
近年来,大型语言模型(LLMs)因其在各个领域回答问题的能力而广受欢迎。然而,这些模型倾向于“幻觉”,这使得评估它们的性能具有挑战性。一个主要的挑战是确定如何评估模型预测的确定性以及它与准确性的相关性。本文介绍了一种分析方法,用于评估流行的开源LLM以及gpt-3.5 Turbo在多项选择物理问卷上的性能。我们重点关注与物理相关主题中答案准确性和变异性之间的关系。我们的研究结果表明,大多数模型在确定时会提供准确的回复,但这远非普遍行为。准确性和不确定性之间的关系呈现出广泛的水平钟形分布。我们报告了当问题需要LLM代理进行更多逻辑推理时,准确性和不确定性之间的不对称性如何加剧,而对于知识检索任务,这种关系仍然很明显。
🔬 方法详解
问题定义:论文旨在解决如何评估大型语言模型(LLMs)在物理知识和推理方面的可靠性问题。现有方法难以有效衡量LLM的“幻觉”现象,无法准确判断模型预测的置信度与实际准确率之间的关系。尤其是在涉及逻辑推理的物理问题上,LLM的可靠性评估面临更大挑战。
核心思路:论文的核心思路是通过分析LLM在多项选择物理问卷上的表现,考察其答案的准确性与变异性之间的关系。通过量化模型预测的不确定性,并将其与实际准确率进行对比,从而揭示模型在不同类型问题上的可靠性特征。这种方法旨在建立一种评估LLM在特定领域知识和推理能力的新框架。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择或构建多项选择物理问卷,涵盖知识检索和逻辑推理两种类型的问题。2) 使用多个流行的开源LLM以及GPT-3.5 Turbo对问卷进行回答。3) 针对每个问题,多次运行LLM以获得多个答案,并计算答案的变异性(例如,不同答案出现的频率)。4) 将答案的变异性作为不确定性的度量,并分析其与答案准确率之间的关系。5) 绘制准确率与不确定性之间的分布图,并分析其形状和特征。
关键创新:该研究的关键创新在于提出了一种基于答案变异性的LLM不确定性评估方法。与传统的置信度评分不同,该方法直接考察模型在多次运行中答案的一致性,从而更准确地反映模型对自身预测的信心程度。此外,该研究还区分了知识检索和逻辑推理两种类型的问题,并分析了LLM在这两种问题上的不同表现。
关键设计:论文的关键设计包括:1) 物理问卷的设计,需要确保问题既涵盖基础知识,又包含一定的逻辑推理难度。2) LLM运行次数的选择,需要在计算资源和结果可靠性之间进行权衡。3) 不确定性度量的选择,例如可以使用答案熵或方差来量化答案的变异性。4) 准确率与不确定性分布图的绘制和分析,需要选择合适的统计方法来揭示二者之间的关系。
🖼️ 关键图片
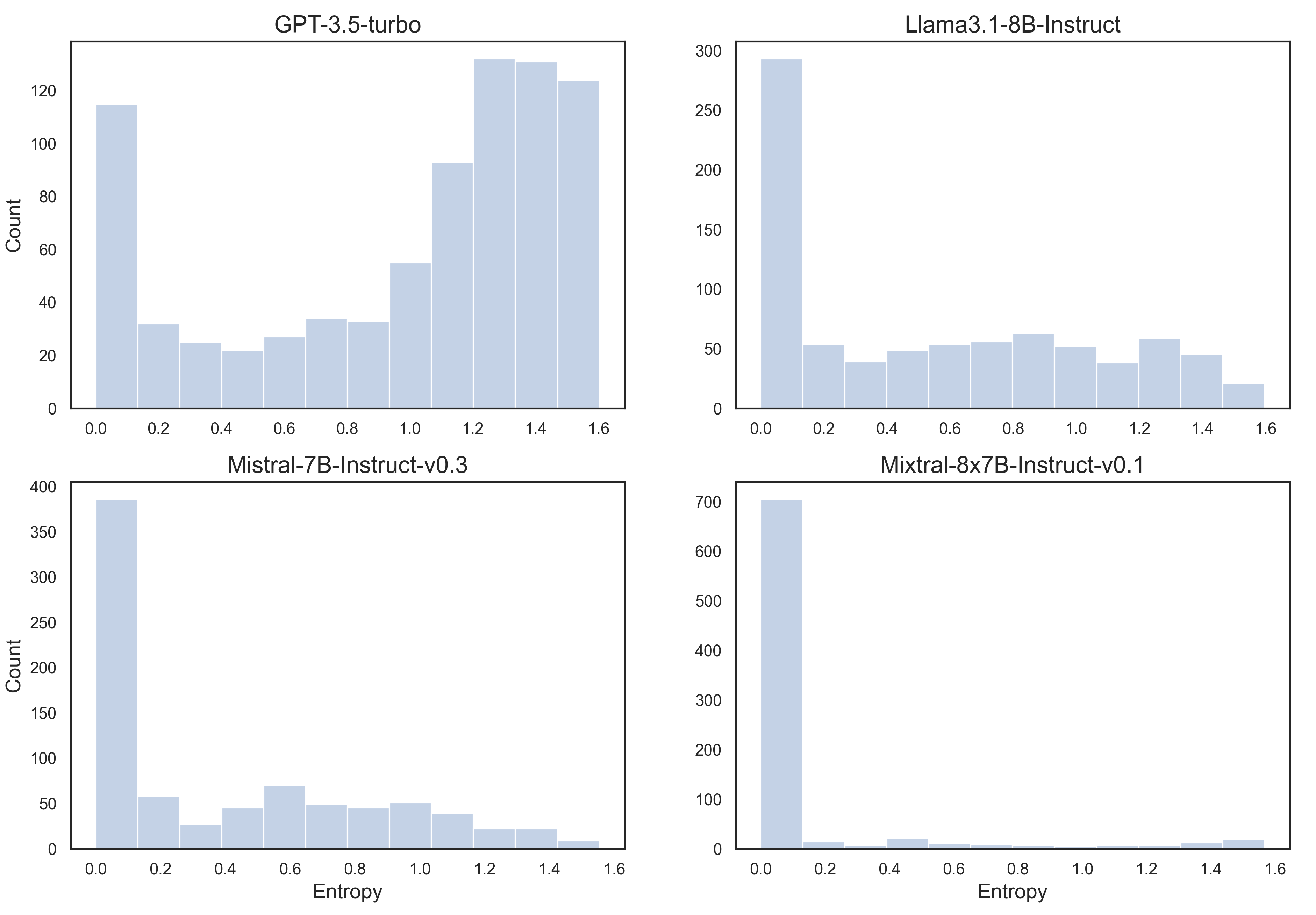
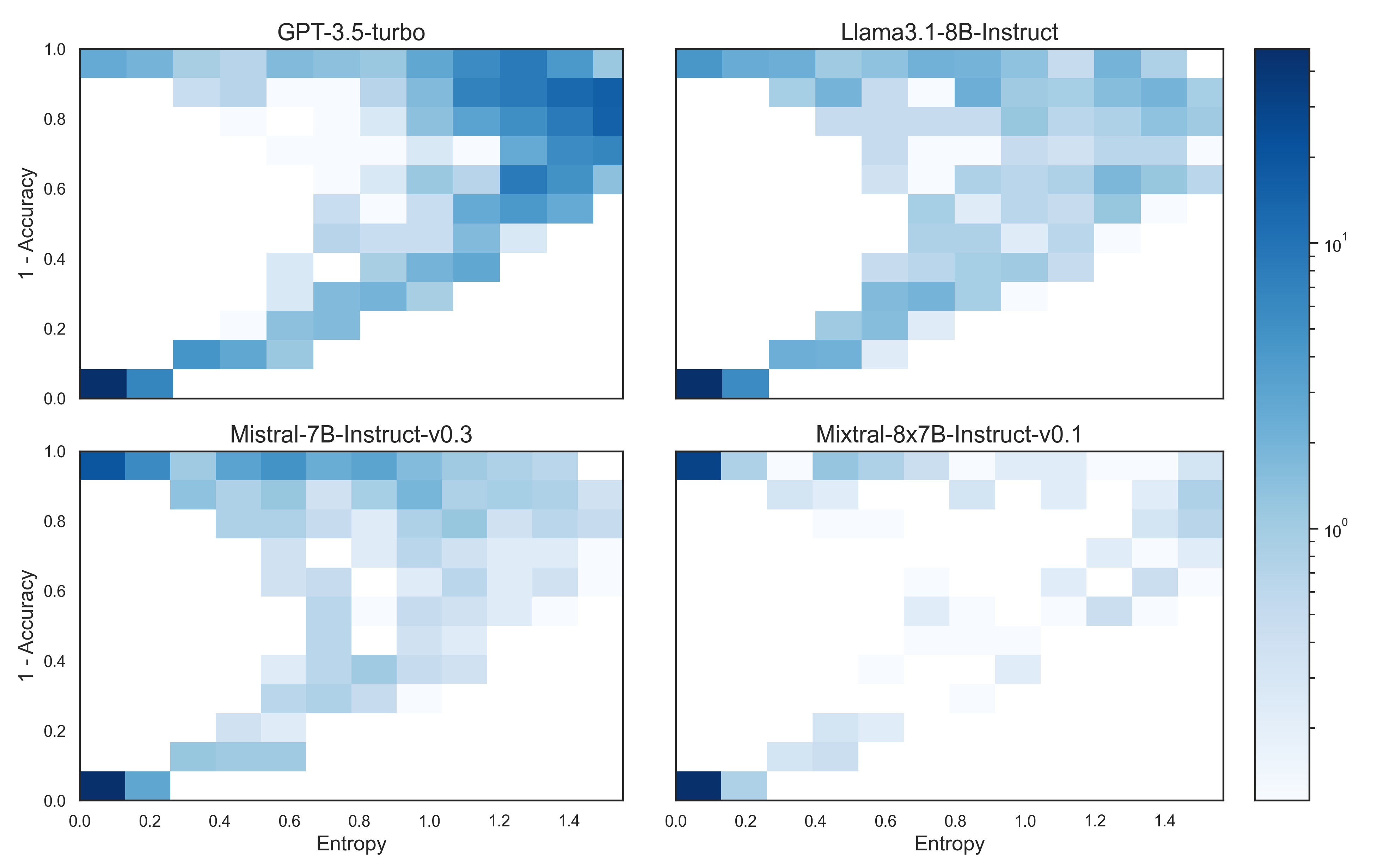
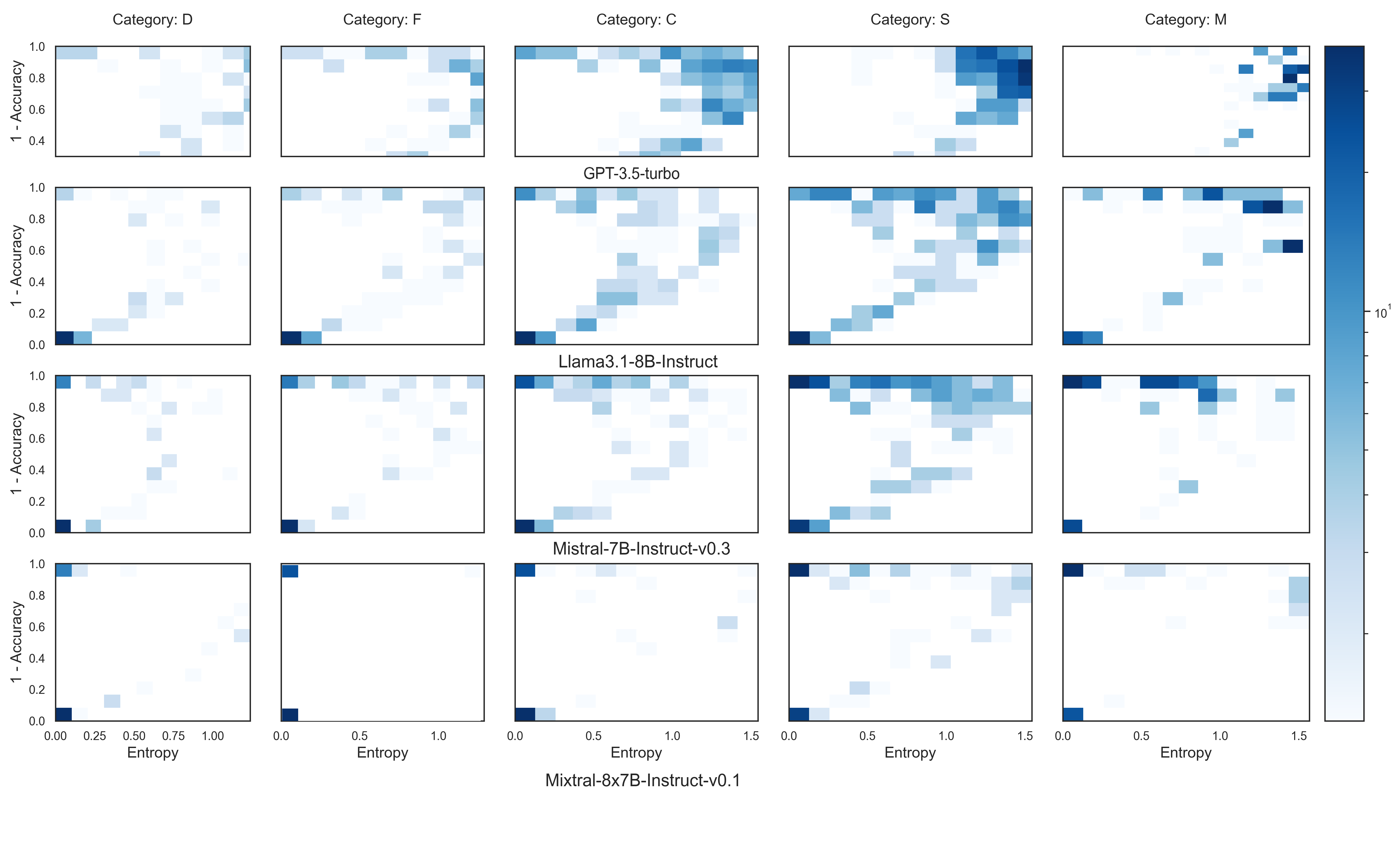
📊 实验亮点
实验结果表明,大多数模型在确定时会提供准确的回复,但这种关系并非普遍成立。准确性和不确定性之间的关系呈现出广泛的水平钟形分布。当问题需要LLM进行更多逻辑推理时,准确性和不确定性之间的不对称性会加剧,而对于知识检索任务,这种关系仍然相对明显。这些发现揭示了LLM在不同类型问题上的可靠性差异。
🎯 应用场景
该研究成果可应用于评估和改进LLM在科学教育、智能辅导、科研辅助等领域的应用。通过了解LLM在特定领域的知识掌握程度和推理能力,可以更好地利用LLM辅助教学和科研工作,并针对LLM的不足之处进行改进,提高其可靠性和实用性。此外,该研究方法也可推广到其他领域,为评估LLM在各个领域的应用提供参考。
📄 摘要(原文)
Large Language Models (LLMs) have gained significant popularity in recent years for their ability to answer questions in various fields. However, these models have a tendency to "hallucinate" their responses, making it challenging to evaluate their performance. A major challenge is determining how to assess the certainty of a model's predictions and how it correlates with accuracy. In this work, we introduce an analysis for evaluating the performance of popular open-source LLMs, as well as gpt-3.5 Turbo, on multiple choice physics questionnaires. We focus on the relationship between answer accuracy and variability in topics related to physics. Our findings suggest that most models provide accurate replies in cases where they are certain, but this is by far not a general behavior. The relationship between accuracy and uncertainty exposes a broad horizontal bell-shaped distribution. We report how the asymmetry between accuracy and uncertainty intensifies as the questions demand more logical reasoning of the LLM agent, while the same relationship remains sharp for knowledge retrieval tasks.