Benchmarking pre-trained text embedding models in aligning built asset information
作者: Mehrzad Shahinmoghadam, Ali Motamedi
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2024-11-18
💡 一句话要点
构建资产信息对齐基准,评估预训练文本嵌入模型在领域知识对齐中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 预训练模型 构建资产信息 领域知识对齐 基准测试 数据分类 BIM
📋 核心要点
- 现有构建资产信息映射方法依赖人工,效率低且易出错,缺乏自动化手段。
- 利用预训练文本嵌入模型,学习构建资产数据的语义表示,实现自动对齐。
- 构建了包含聚类、检索和重排序任务的基准数据集,评估模型性能,并开源资源。
📝 摘要(中文)
准确地将构建资产信息映射到既定的数据分类系统和分类法,对于有效的资产管理至关重要,无论是项目移交时的合规性还是临时数据集成场景。由于构建资产数据的复杂性,主要由技术文本元素组成,这一过程在很大程度上仍然是手动的,并且依赖于领域专家的输入。情境文本表示学习(文本嵌入)的最新突破,特别是通过预训练的大型语言模型,提供了有希望的方法,可以促进构建资产数据的交叉映射自动化。然而,尚未进行全面的评估来评估这些模型有效表示特定于构建资产技术术语的复杂语义的能力。本研究提出了最先进的文本嵌入模型的比较基准,以评估它们在将构建资产信息与领域特定技术概念对齐方面的有效性。我们提出的数据集来自两个著名的构建资产数据分类词典。我们在六个提出的数据集上进行的基准测试结果,涵盖了聚类、检索和重排序三个任务,突出了未来对领域自适应技术进行研究的必要性。基准测试资源以开源库的形式发布,该库将被维护和扩展,以支持该领域未来的评估。
🔬 方法详解
问题定义:论文旨在解决构建资产信息与领域特定技术概念对齐的问题。现有方法主要依赖人工,耗时且容易出错,缺乏自动化和智能化的解决方案。现有方法无法有效捕捉构建资产领域特有的复杂语义信息,导致对齐效果不佳。
核心思路:论文的核心思路是利用预训练的文本嵌入模型,将构建资产信息和领域概念映射到同一语义空间,通过计算向量相似度来实现自动对齐。通过对不同模型的性能进行基准测试,找到最适合该任务的模型,并为未来的领域自适应研究提供参考。
技术框架:论文构建了一个包含数据准备、模型选择、任务定义和评估指标的完整基准测试框架。首先,从两个著名的构建资产数据分类词典中提取数据,构建了六个数据集。然后,选择了多个最先进的文本嵌入模型进行评估。最后,定义了聚类、检索和重排序三个任务,并使用相应的评估指标来衡量模型的性能。
关键创新:论文的关键创新在于构建了一个专门用于评估文本嵌入模型在构建资产信息对齐任务上的性能的基准数据集。该数据集涵盖了不同的任务类型和数据规模,可以全面评估模型的性能。此外,论文还对多个最先进的文本嵌入模型进行了比较分析,为未来的研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) 数据集的构建,确保数据质量和多样性;2) 任务的定义,涵盖了不同的应用场景;3) 评估指标的选择,能够准确反映模型的性能;4) 模型的选择,涵盖了不同类型的文本嵌入模型。
🖼️ 关键图片

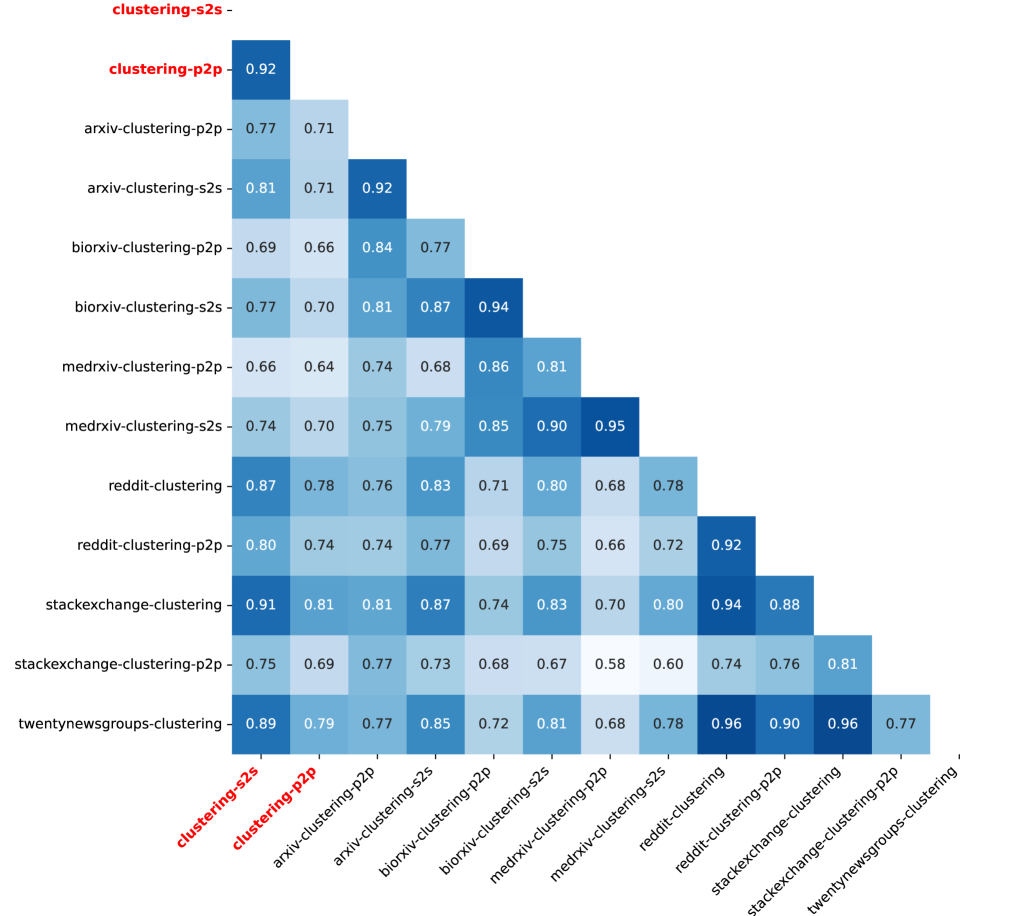
📊 实验亮点
论文构建了六个数据集,涵盖聚类、检索和重排序三个任务,并对多个预训练文本嵌入模型进行了基准测试。实验结果表明,现有模型在构建资产信息对齐任务上的性能仍有提升空间,需要进一步研究领域自适应技术。该基准测试资源已开源,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于建筑信息模型(BIM)、资产管理系统、智能建造等领域。通过自动对齐构建资产信息,可以提高数据质量、减少人工成本、提升工作效率,并为智能决策提供支持。未来,该研究可扩展到其他领域,如医疗、金融等,实现跨领域知识的自动对齐。
📄 摘要(原文)
Accurate mapping of the built asset information to established data classification systems and taxonomies is crucial for effective asset management, whether for compliance at project handover or ad-hoc data integration scenarios. Due to the complex nature of built asset data, which predominantly comprises technical text elements, this process remains largely manual and reliant on domain expert input. Recent breakthroughs in contextual text representation learning (text embedding), particularly through pre-trained large language models, offer promising approaches that can facilitate the automation of cross-mapping of the built asset data. However, no comprehensive evaluation has yet been conducted to assess these models' ability to effectively represent the complex semantics specific to built asset technical terminology. This study presents a comparative benchmark of state-of-the-art text embedding models to evaluate their effectiveness in aligning built asset information with domain-specific technical concepts. Our proposed datasets are derived from two renowned built asset data classification dictionaries. The results of our benchmarking across six proposed datasets, covering three tasks of clustering, retrieval, and reranking, highlight the need for future research on domain adaptation techniques. The benchmarking resources are published as an open-source library, which will be maintained and extended to support future evaluations in this field.