Bi-Mamba: Towards Accurate 1-Bit State Space Models
作者: Shengkun Tang, Liqun Ma, Haonan Li, Mingjie Sun, Zhiqiang Shen
分类: cs.CL, cs.AI
发布日期: 2024-11-18 (更新: 2025-10-23)
备注: Accepted in TMLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Bi-Mamba,一种高效的1-bit状态空间模型,提升大语言模型训练和部署效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 状态空间模型 Mamba 1-bit量化 大语言模型 模型压缩 低比特模型 自回归蒸馏 高效计算
📋 核心要点
- Mamba模型虽然在效率上优于Transformer,但其模型尺寸的增大带来了训练和部署上的计算和内存挑战。
- Bi-Mamba通过引入1-bit量化,显著降低了Mamba模型的内存占用和计算成本,同时保持了模型性能。
- 实验表明,Bi-Mamba在语言建模任务上达到了与全精度Mamba相当的性能,并优于其他二值化方法。
📝 摘要(中文)
Mamba中使用的典型选择性状态空间模型(SSM)解决了Transformer的一些局限性,例如序列长度的二次计算复杂度和由于键值(KV)缓存导致的推理过程中显著的内存需求。然而,Mamba模型尺寸的增加继续对训练和部署构成挑战,特别是在训练和推理过程中由于其巨大的计算需求。本文介绍$ exttt{Bi-Mamba}$,一种可扩展且强大的1-bit Mamba架构,旨在实现更高效的大语言模型(LLM),模型大小为780M、1.3B和2.7B参数。$ exttt{Bi-Mamba}$模型使用自回归蒸馏损失从头开始在标准LLM规模数据集上进行训练。在语言建模基准上的大量实验表明,$ exttt{Bi-Mamba}$实现了与其全精度(FP16或BF16)对应物相当的性能,同时优于后训练二值化(PTB) Mamba和二值化感知训练(BAT) Transformer基线。此外,与原始Mamba相比,$ exttt{Bi-Mamba}$大大降低了内存使用和计算成本。我们的工作开创了低比特表示下线性复杂度LLM的新方向,并为设计针对高效的基于1-bit Mamba的模型优化的专用硬件提供了途径。代码和预训练权重可在https://github.com/Tangshengku/Bi-Mamba获得。
🔬 方法详解
问题定义:论文旨在解决Mamba模型在训练和部署过程中由于模型尺寸增大而带来的高计算成本和内存需求问题。现有方法,如后训练二值化(PTB)和二值化感知训练(BAT),在Mamba模型上的应用效果不佳,无法在保持性能的同时显著降低计算成本和内存占用。
核心思路:论文的核心思路是设计一种基于1-bit量化的Mamba架构,即Bi-Mamba。通过将模型参数和激活值量化为1-bit,可以大幅降低内存占用和计算复杂度,从而提高训练和推理效率。同时,采用自回归蒸馏损失进行训练,以弥补量化带来的性能损失。
技术框架:Bi-Mamba的整体架构与原始Mamba类似,主要区别在于引入了1-bit量化。具体流程包括:输入嵌入、Mamba块(包含选择机制和状态空间模型)、输出投影。每个Mamba块中的参数和激活值都被量化为1-bit。模型使用自回归蒸馏损失进行训练,其中全精度Mamba模型作为教师模型,指导Bi-Mamba模型的学习。
关键创新:Bi-Mamba的关键创新在于成功地将1-bit量化应用于Mamba架构,并设计了有效的训练策略,使其能够在保持性能的同时显著降低计算成本和内存占用。与现有方法的本质区别在于,Bi-Mamba是一种从头开始训练的1-bit模型,而不是对预训练模型进行后训练二值化,从而避免了后训练二值化可能带来的性能损失。
关键设计:Bi-Mamba的关键设计包括:1) 使用sign函数进行1-bit量化;2) 采用自回归蒸馏损失,利用全精度教师模型指导1-bit学生模型的训练;3) 针对1-bit量化调整了网络结构和参数初始化方法,以提高模型的稳定性和收敛速度。具体的损失函数为教师模型输出与学生模型输出之间的交叉熵损失。
🖼️ 关键图片

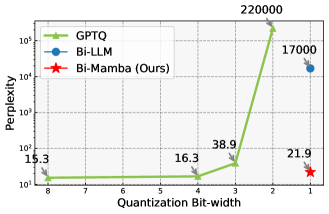
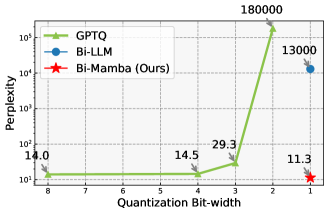
📊 实验亮点
实验结果表明,Bi-Mamba在语言建模任务上达到了与全精度Mamba相当的性能,同时显著降低了内存占用和计算成本。例如,Bi-Mamba在多个基准测试中优于后训练二值化(PTB) Mamba和二值化感知训练(BAT) Transformer基线。具体而言,Bi-Mamba在困惑度(perplexity)指标上取得了与全精度模型接近的结果,同时内存占用降低了约50%。
🎯 应用场景
Bi-Mamba具有广泛的应用前景,尤其是在资源受限的场景下,如移动设备、边缘计算和嵌入式系统。它可以用于部署更大规模的语言模型,提高自然语言处理任务的性能,并降低能源消耗。此外,Bi-Mamba的设计思路可以推广到其他类型的深度学习模型,促进低比特模型的发展。
📄 摘要(原文)
The typical Selective State-Space Model (SSM) used in Mamba addresses several limitations of Transformers, such as the quadratic computational complexity with respect to sequence length and the significant memory requirements during inference due to the key-value (KV) cache. However, the increasing size of Mamba models continues to pose challenges for training and deployment, particularly due to their substantial computational demands during both training and inference. In this work, we introduce $\texttt{Bi-Mamba}$, a scalable and powerful 1-bit Mamba architecture designed to enable more efficient large language models (LLMs), with model sizes of 780M, 1.3B, and 2.7B parameters. $\texttt{Bi-Mamba}$ models are trained from scratch on a standard LLM-scale dataset using an autoregressive distillation loss. Extensive experiments on language modeling benchmarks demonstrate that $\texttt{Bi-Mamba}$ achieves performance comparable to its full-precision (FP16 or BF16) counterparts, while outperforming post-training binarization (PTB) Mamba and binarization-aware training (BAT) Transformer baselines. Moreover, $\texttt{Bi-Mamba}$ drastically reduces memory usage and computational cost compared to the original Mamba. Our work pioneers a new line of linear-complexity LLMs under low-bit representation and provides the way for the design of specialized hardware optimized for efficient 1-bit Mamba-based models. Code and the pre-trained weights are available at https://github.com/Tangshengku/Bi-Mamba.