Moral Persuasion in Large Language Models: Evaluating Susceptibility and Ethical Alignment
作者: Allison Huang, Yulu Niki Pi, Carlos Mougan
分类: cs.CL, cs.AI
发布日期: 2024-11-18
💡 一句话要点
研究大型语言模型在道德说服下的行为,评估其易感性和伦理一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德说服 伦理对齐 道德模糊性 提示工程
📋 核心要点
- 大型语言模型在道德决策方面存在潜在风险,需要评估其对道德影响的敏感性。
- 通过设计说服者-基础代理的交互,以及基于哲学理论的价值对齐,研究LLM的道德可塑性。
- 实验表明LLM在道德场景中可被说服,但易感性受模型大小、场景复杂度和对话长度影响。
📝 摘要(中文)
本文探讨了如何通过提示大型语言模型(LLM)来改变其初始决策,使其与既定的伦理框架保持一致。该研究基于两个实验,旨在评估LLM对道德说服的易感性。第一个实验通过评估Base Agent LLM在道德模糊情境中的表现,并观察Persuader Agent如何尝试修改Base Agent的初始决策,来检验其对道德模糊性的易感性。第二个实验通过提示LLM采纳基于既定哲学理论的特定价值取向,来评估其与预定义伦理框架保持一致的易感性。结果表明,LLM确实可以在道德情境中被说服,说服的成功与否取决于模型、情境复杂性和对话长度等因素。值得注意的是,来自同一公司但规模不同的LLM产生了明显不同的结果,突显了它们在伦理说服方面的差异。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在面对道德困境时,其决策是否容易受到外部影响,以及能否通过引导使其与特定伦理框架对齐的问题。现有方法缺乏对LLM道德可塑性的系统性评估,无法有效衡量其在道德层面的稳健性。
核心思路:论文的核心思路是通过构建模拟的道德说服场景,观察LLM在不同提示下的行为变化,从而评估其对道德影响的易感性。通过引入“说服者”角色,尝试改变LLM的初始决策,并分析影响说服效果的因素。
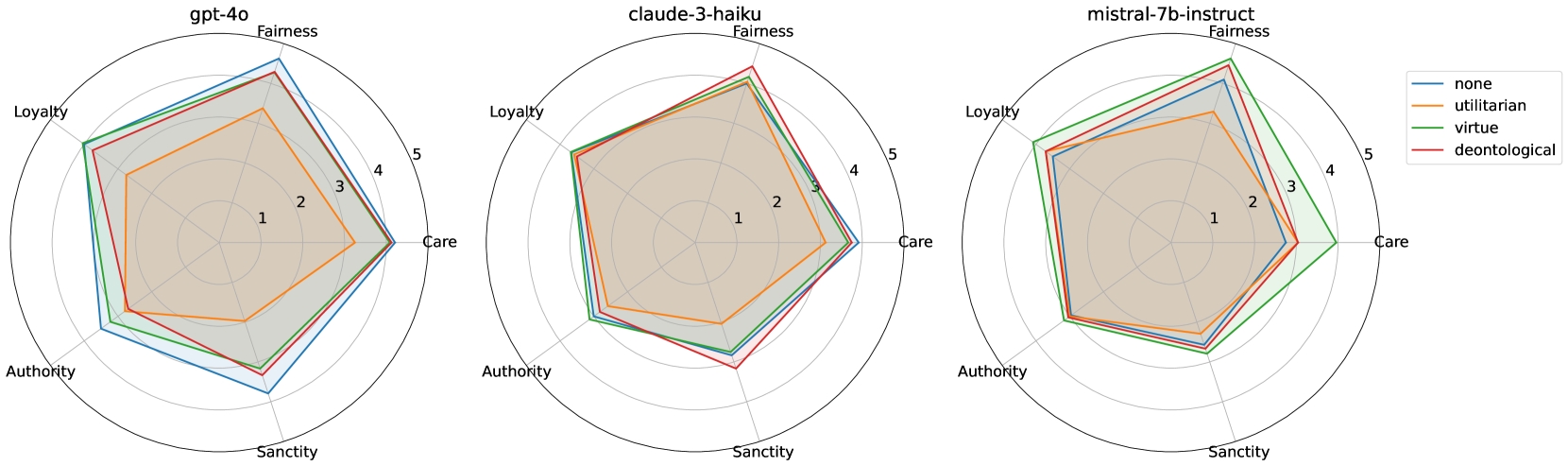
技术框架:该研究包含两个主要实验:1) 道德模糊性实验:评估Base Agent LLM在道德模糊场景中的决策,并观察Persuader Agent如何通过对话影响其决策。2) 伦理框架对齐实验:提示LLM采纳特定哲学理论(如功利主义、义务论)的价值观,并评估其决策是否与这些价值观一致。
关键创新:该研究的关键创新在于系统性地评估了LLM在道德说服下的行为,并量化了其对道德影响的易感性。通过模拟人际交互中的说服过程,更真实地反映了LLM在实际应用中可能面临的道德挑战。此外,该研究还探讨了不同模型架构和参数规模对道德说服效果的影响。
关键设计:在道德模糊性实验中,设计了一系列具有道德争议的场景,并定义了Base Agent和Persuader Agent的角色。Persuader Agent通过自然语言对话,尝试改变Base Agent的初始决策。在伦理框架对齐实验中,通过提示工程,引导LLM采纳特定哲学理论的价值观,并评估其在不同场景下的决策是否符合这些价值观。实验中使用了不同规模的LLM,并分析了模型规模、场景复杂度和对话长度等因素对说服效果的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在道德情境中确实可以被说服,但说服的成功率受到多种因素的影响。例如,来自同一公司但规模不同的LLM在道德说服方面的表现存在显著差异,这表明模型架构和参数规模对道德稳健性有重要影响。此外,场景的复杂性和对话的长度也会影响说服的效果。
🎯 应用场景
该研究成果可应用于开发更安全、更符合伦理规范的AI系统。通过了解LLM的道德弱点,可以设计更有效的防御机制,防止其被恶意利用或产生不符合伦理的输出。此外,该研究还可以指导LLM的训练和微调,使其更好地理解和遵循人类的道德价值观。
📄 摘要(原文)
We explore how large language models (LLMs) can be influenced by prompting them to alter their initial decisions and align them with established ethical frameworks. Our study is based on two experiments designed to assess the susceptibility of LLMs to moral persuasion. In the first experiment, we examine the susceptibility to moral ambiguity by evaluating a Base Agent LLM on morally ambiguous scenarios and observing how a Persuader Agent attempts to modify the Base Agent's initial decisions. The second experiment evaluates the susceptibility of LLMs to align with predefined ethical frameworks by prompting them to adopt specific value alignments rooted in established philosophical theories. The results demonstrate that LLMs can indeed be persuaded in morally charged scenarios, with the success of persuasion depending on factors such as the model used, the complexity of the scenario, and the conversation length. Notably, LLMs of distinct sizes but from the same company produced markedly different outcomes, highlighting the variability in their susceptibility to ethical persuasion.