FedCoLLM: A Parameter-Efficient Federated Co-tuning Framework for Large and Small Language Models
作者: Tao Fan, Yan Kang, Guoqiang Ma, Lixin Fan, Kai Chen, Qiang Yang
分类: cs.CL, cs.AI
发布日期: 2024-11-18
💡 一句话要点
FedCoLLM:面向大小语言模型的参数高效联邦协同调优框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 协同调优 大型语言模型 小型语言模型 参数高效 适配器 知识迁移
📋 核心要点
- 现有方法难以实现服务器端LLM与客户端SLM之间的同步互增强,限制了LLM在特定领域的应用。
- FedCoLLM通过轻量级适配器,在保护数据隐私的前提下,实现LLM知识向SLM的迁移,并利用SLM的领域知识反哺LLM。
- 实验结果表明,FedCoLLM显著提升了客户端SLM的性能,同时使LLM获得了与直接微调相当的性能。
📝 摘要(中文)
为了充分利用大型语言模型(LLM)的能力,通常需要将其适配到特定领域任务或用领域知识进行增强。然而,服务器端的LLM与客户端的小型语言模型(SLM)之间实现同步互增强仍然存在差距。为了解决这个问题,我们提出了FedCoLLM,一种新颖的、参数高效的联邦框架,旨在协同调优LLM和SLM。该方法旨在自适应地将服务器端LLM的知识转移到客户端的SLM,同时利用客户端的领域见解来丰富LLM。为了实现这一目标,FedCoLLM利用轻量级适配器与SLM结合,以尊重数据隐私的方式促进服务器和客户端之间的知识交换,同时最大限度地减少计算和通信开销。我们使用各种公共LLM和SLM,在各种NLP文本生成任务中对FedCoLLM进行了评估,结果表明,在LLM的帮助下,客户端SLM的性能得到了显著提高。同时,通过FedCoLLM增强的LLM实现了与直接在客户端数据上进行微调相当的性能。
🔬 方法详解
问题定义:现有方法无法有效利用联邦学习框架,实现服务器端大型语言模型(LLM)与客户端小型语言模型(SLM)之间的知识互通和协同增强。直接微调LLM成本高昂,且存在数据隐私泄露的风险。客户端SLM能力有限,难以充分利用本地数据。
核心思路:FedCoLLM的核心思路是利用参数高效的适配器(Adapter)来连接LLM和SLM,通过联邦学习的方式,在保护数据隐私的前提下,实现知识的迁移和融合。LLM将通用知识传递给SLM,SLM则将领域知识反馈给LLM。这种协同调优的方式能够提升LLM和SLM的性能。
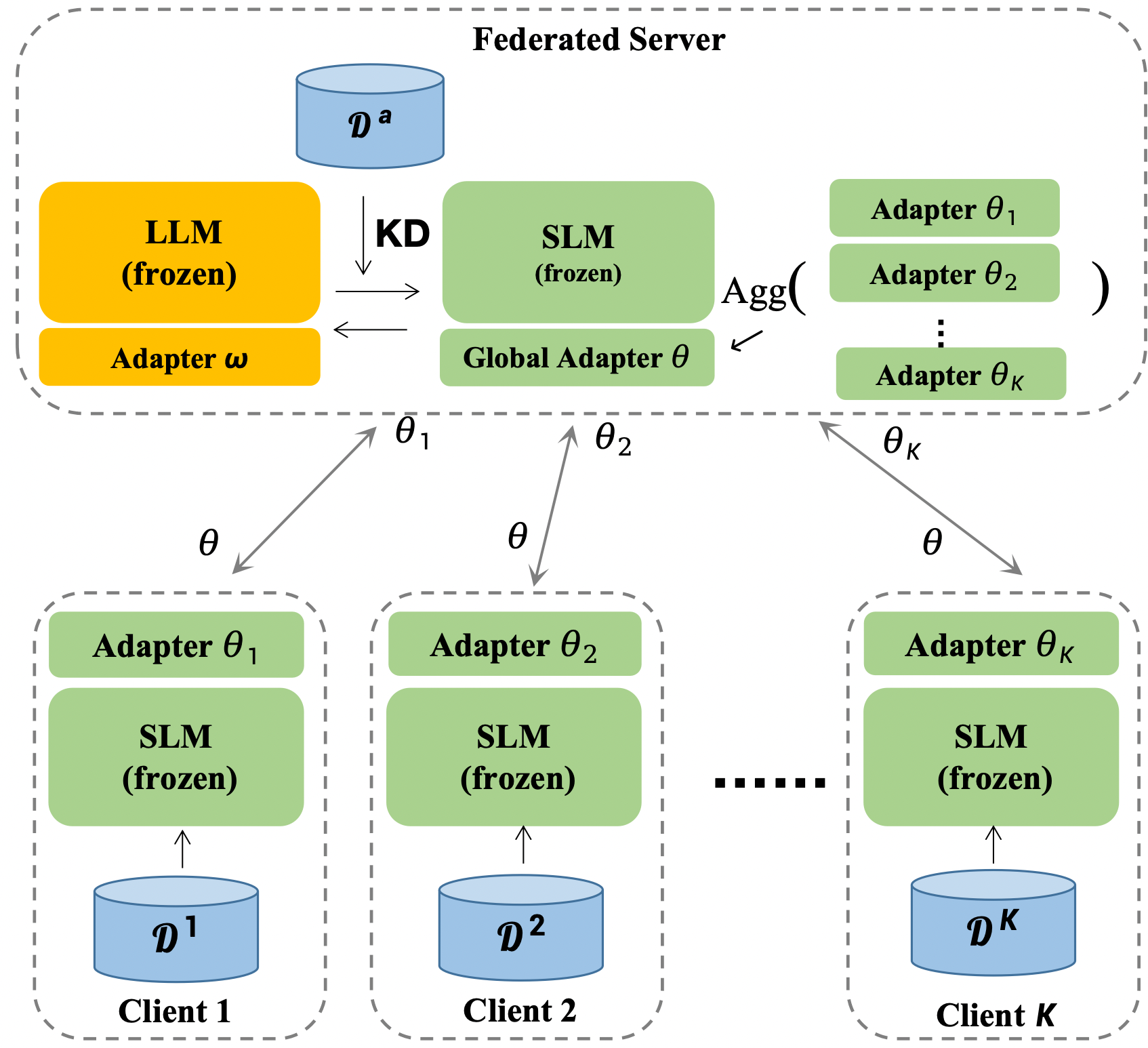
技术框架:FedCoLLM框架包含服务器端LLM和多个客户端SLM。每个客户端在本地数据上训练SLM的适配器,并将适配器的参数上传到服务器。服务器聚合所有客户端上传的适配器参数,更新LLM的适配器。然后,服务器将更新后的LLM适配器参数发送回客户端。客户端使用更新后的LLM适配器参数来指导SLM的训练。这个过程迭代进行,直到LLM和SLM的性能都达到预期。
关键创新:FedCoLLM的关键创新在于提出了一个参数高效的联邦协同调优框架,该框架能够同时提升LLM和SLM的性能。通过使用轻量级适配器,降低了计算和通信开销,同时保护了数据隐私。此外,FedCoLLM实现了LLM和SLM之间的双向知识迁移,使得LLM能够更好地适应特定领域,SLM能够获得更强的泛化能力。
关键设计:FedCoLLM的关键设计包括:1) 使用轻量级适配器来连接LLM和SLM,适配器通常是几层全连接网络,参数量远小于LLM本身;2) 使用联邦平均算法(FedAvg)来聚合客户端上传的适配器参数;3) 设计合适的损失函数,鼓励LLM将知识传递给SLM,并鼓励SLM将领域知识反馈给LLM。具体的损失函数形式未知,需要查阅论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FedCoLLM能够显著提升客户端SLM的性能,在多个NLP文本生成任务上取得了显著的提升。同时,通过FedCoLLM增强的LLM实现了与直接在客户端数据上进行微调相当的性能,证明了该框架的有效性。具体的性能提升数据未知,需要查阅论文原文。
🎯 应用场景
FedCoLLM可应用于各种需要领域知识增强的自然语言处理任务,例如医疗问答、金融文本分析、法律文档处理等。该框架能够有效利用分散在各个客户端的领域数据,提升LLM在特定领域的性能,同时保护用户数据隐私。未来,FedCoLLM有望成为构建领域专用LLM的重要技术手段。
📄 摘要(原文)
By adapting Large Language Models (LLMs) to domain-specific tasks or enriching them with domain-specific knowledge, we can fully harness the capabilities of LLMs. Nonetheless, a gap persists in achieving simultaneous mutual enhancement between the server's LLM and the downstream clients' Small Language Models (SLMs). To address this, we propose FedCoLLM, a novel and parameter-efficient federated framework designed for co-tuning LLMs and SLMs. This approach is aimed at adaptively transferring server-side LLMs knowledge to clients' SLMs while simultaneously enriching the LLMs with domain insights from the clients. To accomplish this, FedCoLLM utilizes lightweight adapters in conjunction with SLMs, facilitating knowledge exchange between server and clients in a manner that respects data privacy while also minimizing computational and communication overhead. Our evaluation of FedCoLLM, utilizing various public LLMs and SLMs across a range of NLP text generation tasks, reveals that the performance of clients' SLMs experiences notable improvements with the assistance of the LLMs. Simultaneously, the LLMs enhanced via FedCoLLM achieves comparable performance to that obtained through direct fine-tuning on clients' data.