Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text
作者: Xiaoliang Luo, Michael Ramscar, Bradley C. Love
分类: cs.CL, q-bio.NC
发布日期: 2024-11-17
💡 一句话要点
大型语言模型在正向和反向科学文本上表现相当,质疑类人处理假设
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Transformer架构 反向文本 语言理解 神经科学 模式识别 通用性 鲁棒性
📋 核心要点
- 大型语言模型在语言任务中表现出色,引发了关于其是否模拟人类语言处理机制的讨论。
- 该研究提出LLM的成功源于Transformer架构的灵活性,而非模拟人类语言处理。
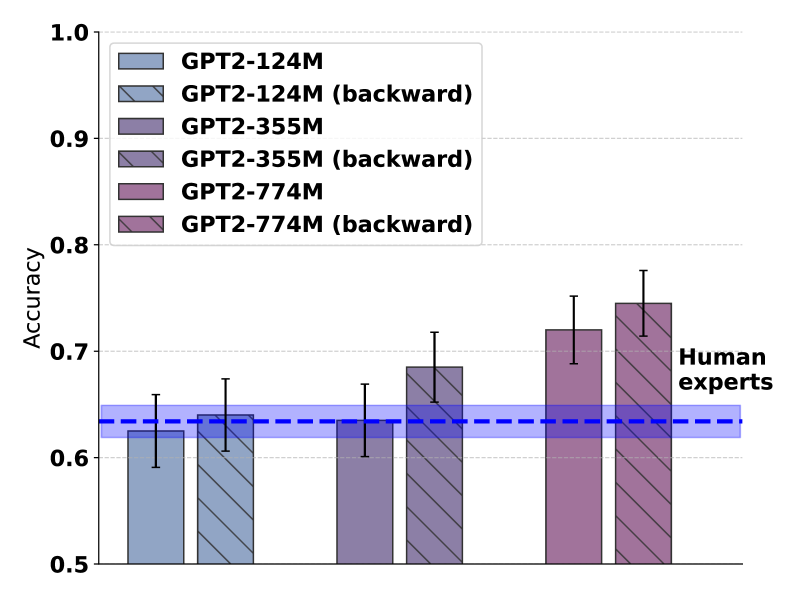
- 实验表明,LLM在正向和反向科学文本上表现相当,超越人类专家,支持了Transformer的通用性。
📝 摘要(中文)
大型语言模型(LLM)的卓越性能使其被认为是人类语言处理的模型。然而,我们认为LLM的成功源于Transformer学习架构的灵活性。为了验证这一猜想,我们训练了LLM处理正向或反向格式的科学文本。尽管反向文本与人类语言的结构不一致,但我们发现LLM在这两种格式的神经科学基准测试中表现同样出色,超越了人类专家的表现。我们的结果与Transformer在天气预测和蛋白质设计等不同领域的成功相一致。这种广泛的成功归因于LLM从任何充分结构化的输入中提取预测模式的能力。鉴于其通用性,我们建议在将LLM在语言任务中的成功解释为人类机制的证据时应谨慎。
🔬 方法详解
问题定义:论文旨在探讨大型语言模型(LLM)在处理非自然语言结构(即反向文本)时的性能,从而评估其是否真正模拟了人类语言处理机制。现有观点倾向于将LLM的成功归因于其学习人类语言模式的能力,但该研究质疑这种观点,认为LLM的成功可能源于Transformer架构的通用性,而非特定于人类语言的特性。
核心思路:核心思路是通过训练LLM处理正向和反向的科学文本,并比较其在神经科学基准测试中的表现。如果LLM在两种文本格式上表现相当,则表明其学习能力并非依赖于人类语言的自然结构,而是能够从任何具有足够结构化的输入中提取模式。这种设计旨在验证LLM的成功是否源于Transformer架构的灵活性,而非模拟人类语言处理。
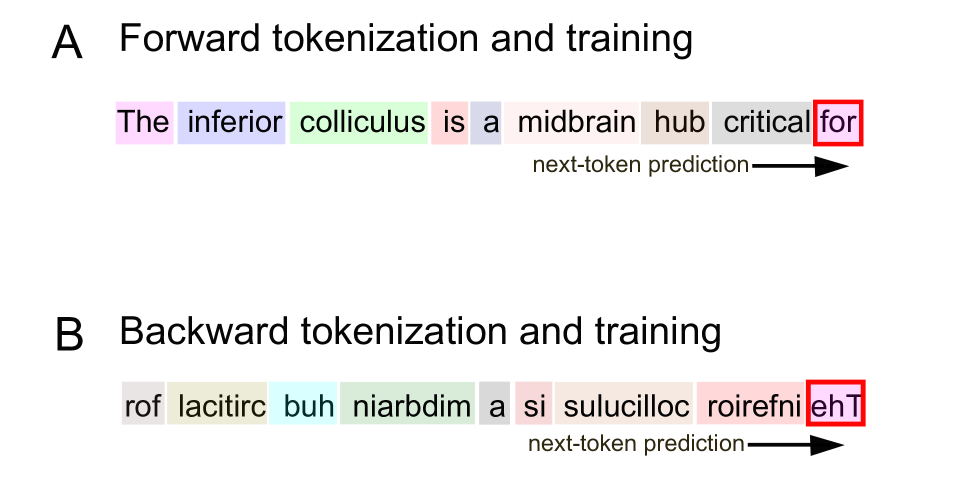
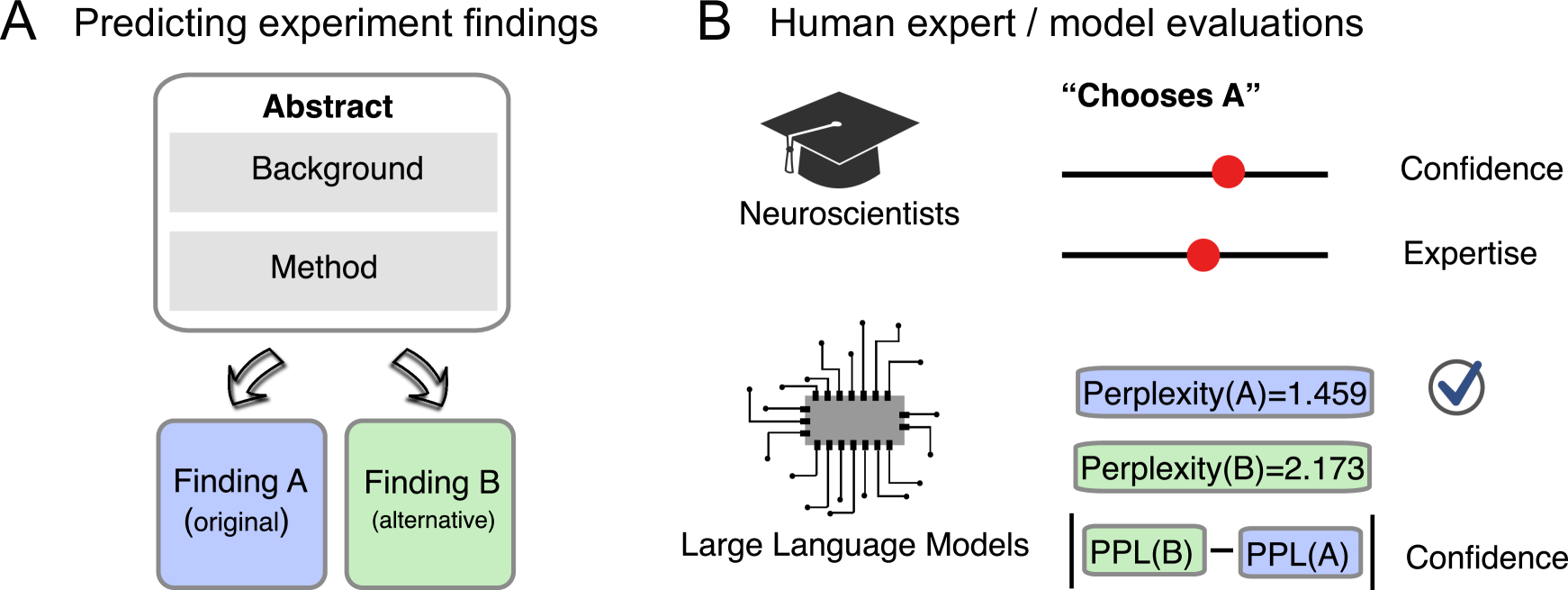
技术框架:该研究的技术框架主要包括以下几个步骤:1) 准备正向和反向的科学文本数据集;2) 使用Transformer架构训练LLM分别处理这两种数据集;3) 在神经科学基准测试中评估LLM在两种文本格式上的性能;4) 比较LLM和人类专家在两种文本格式上的表现。整体流程旨在通过对比实验,验证LLM在处理非自然语言结构时的能力。
关键创新:该研究的关键创新在于使用反向文本作为评估LLM语言理解能力的挑战。与传统的语言模型评估方法不同,该研究通过引入非自然语言结构,挑战了LLM必须模拟人类语言处理机制才能取得成功的观点。这种方法能够更有效地评估LLM的通用性和灵活性。
关键设计:论文的关键设计包括:1) 选择科学文本作为训练数据,因为科学文本具有较强的结构性和逻辑性;2) 使用神经科学基准测试作为评估指标,因为神经科学领域对语言理解有较高的要求;3) 对比LLM和人类专家在两种文本格式上的表现,从而更全面地评估LLM的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在正向和反向科学文本上的神经科学基准测试中表现相当,并且超越了人类专家的表现。这一结果有力地支持了LLM的成功源于Transformer架构的灵活性,而非模拟人类语言处理机制的观点。具体性能数据未知,但强调了LLM在非自然语言结构上的卓越表现。
🎯 应用场景
该研究的成果可应用于评估和改进大型语言模型的通用性和鲁棒性。通过使用非自然语言结构进行训练和测试,可以更好地了解LLM的学习机制,并开发出更具适应性的模型。此外,该研究也提醒人们在将LLM应用于语言任务时,应谨慎解释其成功,避免过度解读为模拟人类语言处理。
📄 摘要(原文)
The impressive performance of large language models (LLMs) has led to their consideration as models of human language processing. Instead, we suggest that the success of LLMs arises from the flexibility of the transformer learning architecture. To evaluate this conjecture, we trained LLMs on scientific texts that were either in a forward or backward format. Despite backward text being inconsistent with the structure of human languages, we found that LLMs performed equally well in either format on a neuroscience benchmark, eclipsing human expert performance for both forward and backward orders. Our results are consistent with the success of transformers across diverse domains, such as weather prediction and protein design. This widespread success is attributable to LLM's ability to extract predictive patterns from any sufficiently structured input. Given their generality, we suggest caution in interpreting LLM's success in linguistic tasks as evidence for human-like mechanisms.