BianCang: A Traditional Chinese Medicine Large Language Model
作者: Sibo Wei, Xueping Peng, Yi-Fei Wang, Tao Shen, Jiasheng Si, Weiyu Zhang, Fa Zhu, Athanasios V. Vasilakos, Wenpeng Lu, Xiaoming Wu, Yinglong Wang
分类: cs.CL, cs.AI
发布日期: 2024-11-17 (更新: 2025-09-30)
期刊: IEEE Journal of Biomedical and Health Informatics (Early Access), 2025, 1-12
DOI: 10.1109/JBHI.2025.3612415
🔗 代码/项目: GITHUB
💡 一句话要点
提出BianCang:一个面向中医领域的大语言模型,提升中医诊断和辨证能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中医大语言模型 领域知识注入 指令微调 中医诊断 中医辨证
📋 核心要点
- 现有医学大语言模型在中医诊断和辨证方面表现不佳,主要原因是中医理论与现代医学差异大,且缺乏高质量的专业语料。
- BianCang通过两阶段训练解决上述问题:首先注入中医领域知识,然后通过针对性训练提升诊断和辨证能力。
- 实验结果表明,BianCang在11个测试集、4个任务上表现出色,证明了其有效性,并为未来研究提供了有价值的参考。
📝 摘要(中文)
大型语言模型(LLMs)的激增推动了包括传统中医(TCM)在内的医学应用的显著进步。然而,由于中医与现代医学理论之间存在巨大差异,以及缺乏专业、高质量的语料库,当前的医学LLM在TCM诊断和辨证方面存在困难。为此,本文提出了BianCang,一个TCM专用LLM,它使用两阶段训练过程,首先注入领域特定知识,然后通过有针对性的刺激来调整它,以增强诊断和辨证能力。具体来说,我们构建了预训练语料库、基于真实医院记录的指令对齐数据集,以及源自《中华人民共和国药典》的ChP-TCM数据集。我们编译了广泛的TCM和医学语料库,用于持续预训练和监督微调,构建了一个全面的数据集来完善模型对TCM的理解。在涉及31个模型和4个任务的11个测试集上的评估证明了BianCang的有效性,为未来的研究提供了宝贵的见解。代码、数据集和模型可在https://github.com/QLU-NLP/BianCang上找到。
🔬 方法详解
问题定义:现有医学大语言模型难以胜任中医诊断和辨证任务,主要痛点在于:一是中医理论体系与现代医学差异巨大,导致通用医学模型难以理解中医的独特概念和逻辑;二是缺乏高质量、大规模的中医领域语料库,限制了模型学习中医知识的能力。
核心思路:BianCang的核心思路是构建一个专门面向中医领域的大语言模型,通过领域知识注入和针对性训练,使其能够更好地理解和应用中医理论。具体而言,模型首先通过预训练学习大量中医知识,然后通过指令微调,使其能够根据具体病例进行诊断和辨证。
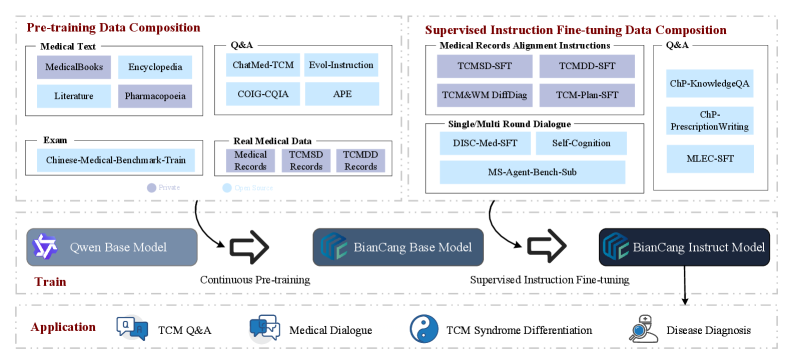
技术框架:BianCang的训练过程分为两个阶段:1) 领域知识注入:利用构建的大规模中医和医学语料库进行持续预训练,使模型掌握丰富的中医知识。语料库包括预训练语料、指令对齐数据集(基于真实医院记录)和ChP-TCM数据集(源自《中华人民共和国药典》)。2) 针对性训练:通过监督微调,利用指令对齐数据集,使模型能够根据具体病例进行诊断和辨证。
关键创新:BianCang的关键创新在于构建了高质量的中医领域语料库,并设计了两阶段训练策略,有效提升了模型在中医诊断和辨证方面的能力。与通用医学模型相比,BianCang更专注于中医领域,能够更好地理解和应用中医理论。
关键设计:论文中提到构建了预训练语料库、指令对齐数据集和ChP-TCM数据集,但未详细说明具体的数据规模、格式和构建方法。同样,论文也未详细描述预训练和微调阶段的具体参数设置、损失函数和网络结构等技术细节,这些细节属于未知信息。
🖼️ 关键图片

📊 实验亮点
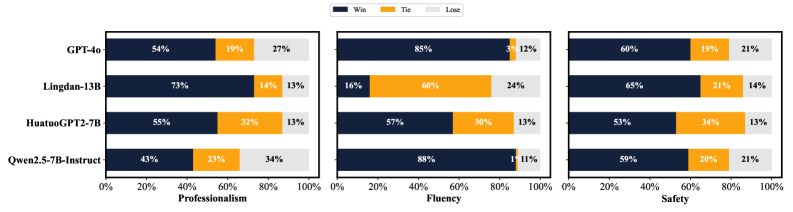
BianCang在11个测试集上进行了评估,涉及31个模型和4个任务,实验结果证明了BianCang的有效性。具体的性能数据、对比基线和提升幅度等详细信息未在摘要中给出,需要在论文正文中查找。
🎯 应用场景
BianCang可应用于辅助中医医生进行诊断和辨证,提高诊断效率和准确性。此外,还可用于中医知识的普及和教育,帮助更多人了解和学习中医。未来,BianCang有望成为中医智能化发展的重要组成部分,推动中医现代化。
📄 摘要(原文)
The surge of large language models (LLMs) has driven significant progress in medical applications, including traditional Chinese medicine (TCM). However, current medical LLMs struggle with TCM diagnosis and syndrome differentiation due to substantial differences between TCM and modern medical theory, and the scarcity of specialized, high-quality corpora. To this end, in this paper we propose BianCang, a TCM-specific LLM, using a two-stage training process that first injects domain-specific knowledge and then aligns it through targeted stimulation to enhance diagnostic and differentiation capabilities. Specifically, we constructed pre-training corpora, instruction-aligned datasets based on real hospital records, and the ChP-TCM dataset derived from the Pharmacopoeia of the People's Republic of China. We compiled extensive TCM and medical corpora for continual pre-training and supervised fine-tuning, building a comprehensive dataset to refine the model's understanding of TCM. Evaluations across 11 test sets involving 31 models and 4 tasks demonstrate the effectiveness of BianCang, offering valuable insights for future research. Code, datasets, and models are available on https://github.com/QLU-NLP/BianCang.