Understanding Multimodal LLMs: the Mechanistic Interpretability of Llava in Visual Question Answering
作者: Zeping Yu, Sophia Ananiadou
分类: cs.CL
发布日期: 2024-11-17 (更新: 2025-01-11)
备注: preprint
🔗 代码/项目: GITHUB
💡 一句话要点
通过机制可解释性分析,理解LLaVA在视觉问答中的工作原理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉问答 机制可解释性 大语言模型 LLaVA 视觉幻觉 嵌入空间 上下文学习
📋 核心要点
- 多模态大语言模型(MLLMs)的内部机制尚不明确,阻碍了模型优化和可靠性提升。
- 本研究通过机制可解释性方法,深入分析LLaVA在视觉问答任务中的工作原理。
- 研究揭示了VQA与文本QA的相似机制,并开发工具辅助理解视觉幻觉,提升可解释性。
📝 摘要(中文)
理解大型语言模型(LLMs)背后的机制对于设计改进的模型和策略至关重要。虽然最近的研究已经对文本LLMs的机制产生了有价值的见解,但多模态大型语言模型(MLLMs)的机制仍未被充分探索。在本文中,我们应用机制可解释性方法来分析第一个MLLM,LLaVA中的视觉问答(VQA)机制。我们比较了颜色回答任务中VQA和文本QA(TQA)之间的机制,发现:a)VQA表现出类似于TQA中观察到的上下文学习机制;b)当将视觉嵌入投影到嵌入空间时,视觉特征表现出显著的可解释性;c)LLaVA在视觉指令调整期间增强了相应文本LLM Vicuna的现有能力。基于这些发现,我们开发了一个可解释性工具,以帮助用户和研究人员识别对最终预测重要的视觉位置,从而帮助理解视觉幻觉。与现有的可解释性方法相比,我们的方法展示了更快、更有效的结果。
🔬 方法详解
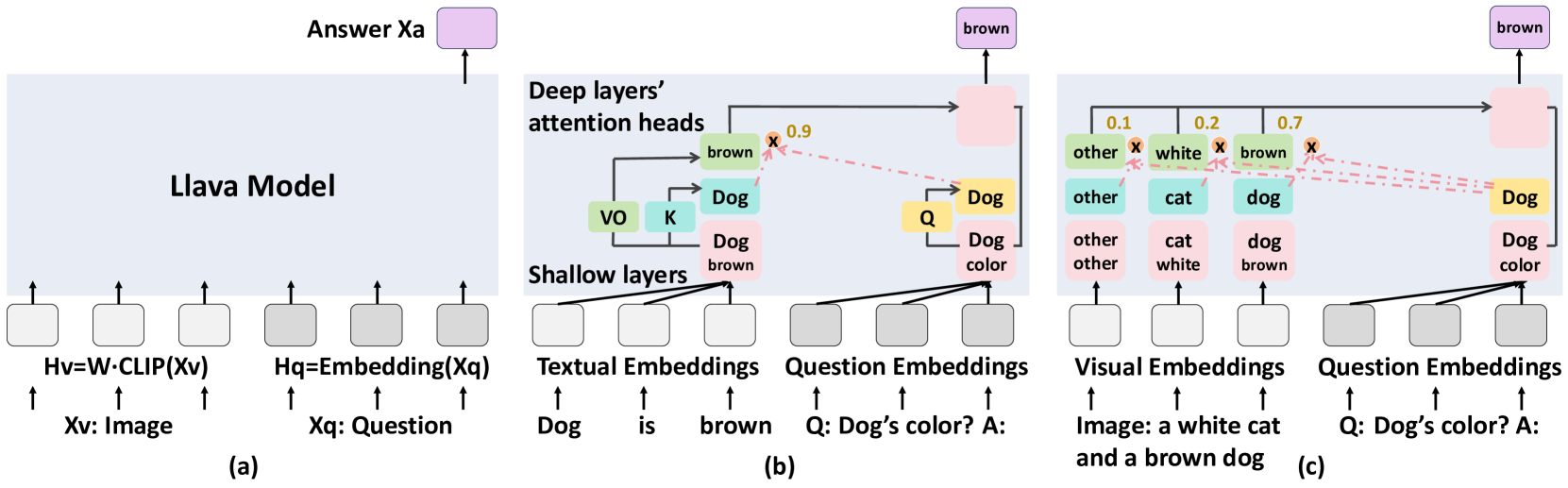
问题定义:论文旨在理解多模态大语言模型LLaVA在视觉问答任务中的工作机制。现有方法对MLLM的内部运作缺乏深入理解,难以解释模型的决策过程,尤其是在视觉幻觉等问题上。
核心思路:论文采用机制可解释性方法,通过分析模型内部的激活和嵌入,揭示VQA任务中视觉信息处理的关键环节。核心在于将视觉特征投影到文本嵌入空间,从而分析视觉信息对最终答案的影响。
技术框架:整体框架包括:1) 选择LLaVA模型进行分析;2) 设计颜色回答等特定VQA任务;3) 将视觉嵌入投影到文本嵌入空间;4) 分析激活模式和重要视觉区域;5) 开发可解释性工具,用于识别影响预测的关键视觉位置。
关键创新:该研究将机制可解释性方法应用于MLLM,并揭示了VQA中类似于文本QA的上下文学习机制。通过分析视觉嵌入,实现了对视觉信息的有效解释,并开发了辅助理解视觉幻觉的工具。这是对MLLM可解释性研究的重要一步。
关键设计:研究中,视觉嵌入的投影方式、激活模式的分析方法、以及可解释性工具的设计是关键。具体参数设置和网络结构细节可能参考LLaVA的原始论文,但本研究的重点在于如何利用这些信息进行可解释性分析。
🖼️ 关键图片


📊 实验亮点
研究发现VQA表现出类似于文本QA的上下文学习机制,视觉特征在投影到嵌入空间时具有显著的可解释性。LLaVA在视觉指令调整期间增强了Vicuna的现有能力。开发的可解释性工具能够快速有效地识别对最终预测重要的视觉位置,优于现有方法。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的可解释性和可靠性。通过理解模型如何处理视觉信息,可以改进模型设计,减少视觉幻觉等问题。此外,该研究开发的可解释性工具可以帮助用户和研究人员更好地理解模型的决策过程,从而提高模型在实际应用中的可信度。
📄 摘要(原文)
Understanding the mechanisms behind Large Language Models (LLMs) is crucial for designing improved models and strategies. While recent studies have yielded valuable insights into the mechanisms of textual LLMs, the mechanisms of Multi-modal Large Language Models (MLLMs) remain underexplored. In this paper, we apply mechanistic interpretability methods to analyze the visual question answering (VQA) mechanisms in the first MLLM, Llava. We compare the mechanisms between VQA and textual QA (TQA) in color answering tasks and find that: a) VQA exhibits a mechanism similar to the in-context learning mechanism observed in TQA; b) the visual features exhibit significant interpretability when projecting the visual embeddings into the embedding space; and c) Llava enhances the existing capabilities of the corresponding textual LLM Vicuna during visual instruction tuning. Based on these findings, we develop an interpretability tool to help users and researchers identify important visual locations for final predictions, aiding in the understanding of visual hallucination. Our method demonstrates faster and more effective results compared to existing interpretability approaches. Code: \url{https://github.com/zepingyu0512/llava-mechanism}