Empowering Meta-Analysis: Leveraging Large Language Models for Scientific Synthesis
作者: Jawad Ibn Ahad, Rafeed Mohammad Sultan, Abraham Kaikobad, Fuad Rahman, Mohammad Ruhul Amin, Nabeel Mohammed, Shafin Rahman
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-11-16
备注: Accepted in 2024 IEEE International Conference on Big Data (IEEE BigData)
💡 一句话要点
利用大型语言模型赋能元分析,实现科学文献的自动化综合
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 元分析 大型语言模型 检索增强生成 科学文献 自动化 微调 逆余弦距离
📋 核心要点
- 现有元分析方法依赖手工操作,面临耗时、易出错等挑战,难以有效处理海量科学文献。
- 该论文提出一种基于微调大型语言模型(LLM)的自动化元分析方法,结合检索增强生成(RAG)提升效率。
- 实验结果表明,微调后的LLM在生成相关元分析摘要方面表现出色,相关性达到87.6%,不相关性显著降低。
📝 摘要(中文)
本研究探讨了利用大型语言模型(LLM)自动化科学文献中的元分析。元分析是一种稳健的统计方法,它综合多个研究的支持文章的发现,以提供全面的理解。元分析文章对多个文章进行结构化分析。然而,手工进行元分析既费力又耗时,并且容易出现人为错误,因此需要自动化的流程来简化该过程。我们的研究引入了一种新颖的方法,该方法在广泛的科学数据集上微调LLM,以应对大数据处理和结构化数据提取方面的挑战。通过集成检索增强生成(RAG)来自动化和优化元分析过程。通过提示工程和一种新的损失指标——逆余弦距离(ICD)进行定制,该指标专为在大型上下文数据集上进行微调而设计,LLM可以高效地生成结构化的元分析内容。然后,人工评估会评估相关性,并提供有关模型在关键指标中的性能的信息。这项研究表明,微调后的模型优于未微调的模型,其中微调后的LLM生成了87.6%的相关元分析摘要。根据人工评估,上下文的相关性表明不相关性从4.56%降低到1.9%。这些实验是在低资源环境中进行的,突显了该研究对提高元分析自动化效率和可靠性的贡献。
🔬 方法详解
问题定义:论文旨在解决科学文献元分析过程中手工操作的低效和易错问题。现有方法难以有效处理大规模数据,且人工提取和综合信息耗时费力,阻碍了科学研究的进展。
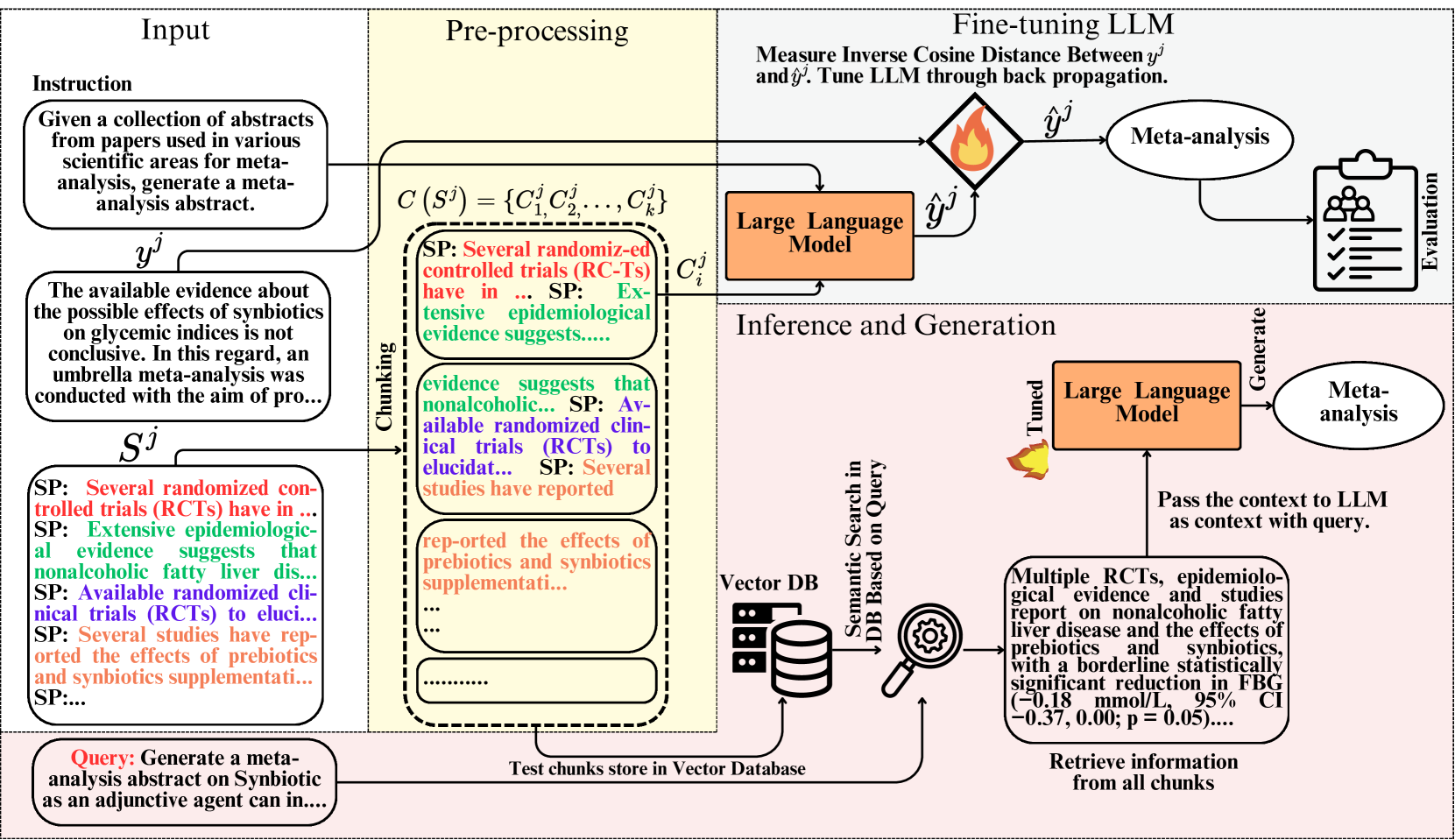
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,结合检索增强生成(RAG)框架,实现元分析的自动化。通过在科学数据集上微调LLM,使其能够理解和提取关键信息,并生成结构化的元分析内容。
技术框架:该方法的技术框架主要包括以下几个阶段:1) 数据准备:构建包含大量科学文献的数据集,用于LLM的微调。2) 模型微调:在科学数据集上微调LLM,使其适应元分析任务。3) 检索增强生成(RAG):利用RAG框架,从相关文献中检索信息,并将其作为LLM生成元分析内容的上下文。4) 提示工程:设计合适的提示,引导LLM生成高质量的元分析内容。5) 人工评估:对生成的元分析内容进行人工评估,评估其相关性和准确性。
关键创新:该论文的关键创新在于:1) 将大型语言模型应用于元分析任务,实现了自动化。2) 提出了逆余弦距离(ICD)损失函数,用于在大型上下文数据集上微调LLM,提升了模型的性能。3) 结合检索增强生成(RAG)框架,提高了生成元分析内容的相关性。
关键设计:论文的关键设计包括:1) 逆余弦距离(ICD)损失函数:该损失函数旨在优化LLM在大型上下文数据集上的微调,通过最小化预测向量和目标向量之间的余弦距离的倒数,鼓励模型学习更准确的表示。2) 提示工程:通过精心设计的提示,引导LLM生成结构化的元分析内容,例如摘要、结论等。3) 模型选择:选择合适的预训练LLM,并根据元分析任务的特点进行微调。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过微调的LLM在生成相关元分析摘要方面显著优于未微调的模型,相关性从基线的未知水平提升至87.6%。同时,人工评估显示,生成内容的不相关性从4.56%降低至1.9%,表明该方法能够有效提高元分析的质量和效率。
🎯 应用场景
该研究成果可广泛应用于医学、生物学、化学等领域的科学文献元分析,加速科研成果的综合和应用。自动化元分析能够大幅提升研究效率,减少人为误差,为科研人员提供更可靠的证据支持,促进科学发现和技术创新。
📄 摘要(原文)
This study investigates the automation of meta-analysis in scientific documents using large language models (LLMs). Meta-analysis is a robust statistical method that synthesizes the findings of multiple studies support articles to provide a comprehensive understanding. We know that a meta-article provides a structured analysis of several articles. However, conducting meta-analysis by hand is labor-intensive, time-consuming, and susceptible to human error, highlighting the need for automated pipelines to streamline the process. Our research introduces a novel approach that fine-tunes the LLM on extensive scientific datasets to address challenges in big data handling and structured data extraction. We automate and optimize the meta-analysis process by integrating Retrieval Augmented Generation (RAG). Tailored through prompt engineering and a new loss metric, Inverse Cosine Distance (ICD), designed for fine-tuning on large contextual datasets, LLMs efficiently generate structured meta-analysis content. Human evaluation then assesses relevance and provides information on model performance in key metrics. This research demonstrates that fine-tuned models outperform non-fine-tuned models, with fine-tuned LLMs generating 87.6% relevant meta-analysis abstracts. The relevance of the context, based on human evaluation, shows a reduction in irrelevancy from 4.56% to 1.9%. These experiments were conducted in a low-resource environment, highlighting the study's contribution to enhancing the efficiency and reliability of meta-analysis automation.