MLAN: Language-Based Instruction Tuning Preserves and Transfers Knowledge in Multimodal Language Models
作者: Jianhong Tu, Zhuohao Ni, Nicholas Crispino, Zihao Yu, Michael Bendersky, Beliz Gunel, Ruoxi Jia, Xin Liu, Lingjuan Lyu, Dawn Song, Chenguang Wang
分类: cs.CL
发布日期: 2024-11-15 (更新: 2025-06-28)
💡 一句话要点
MLAN:基于语言指令微调,在多模态语言模型中保持并迁移知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 指令微调 视觉语言模型 知识迁移 文本数据增强
📋 核心要点
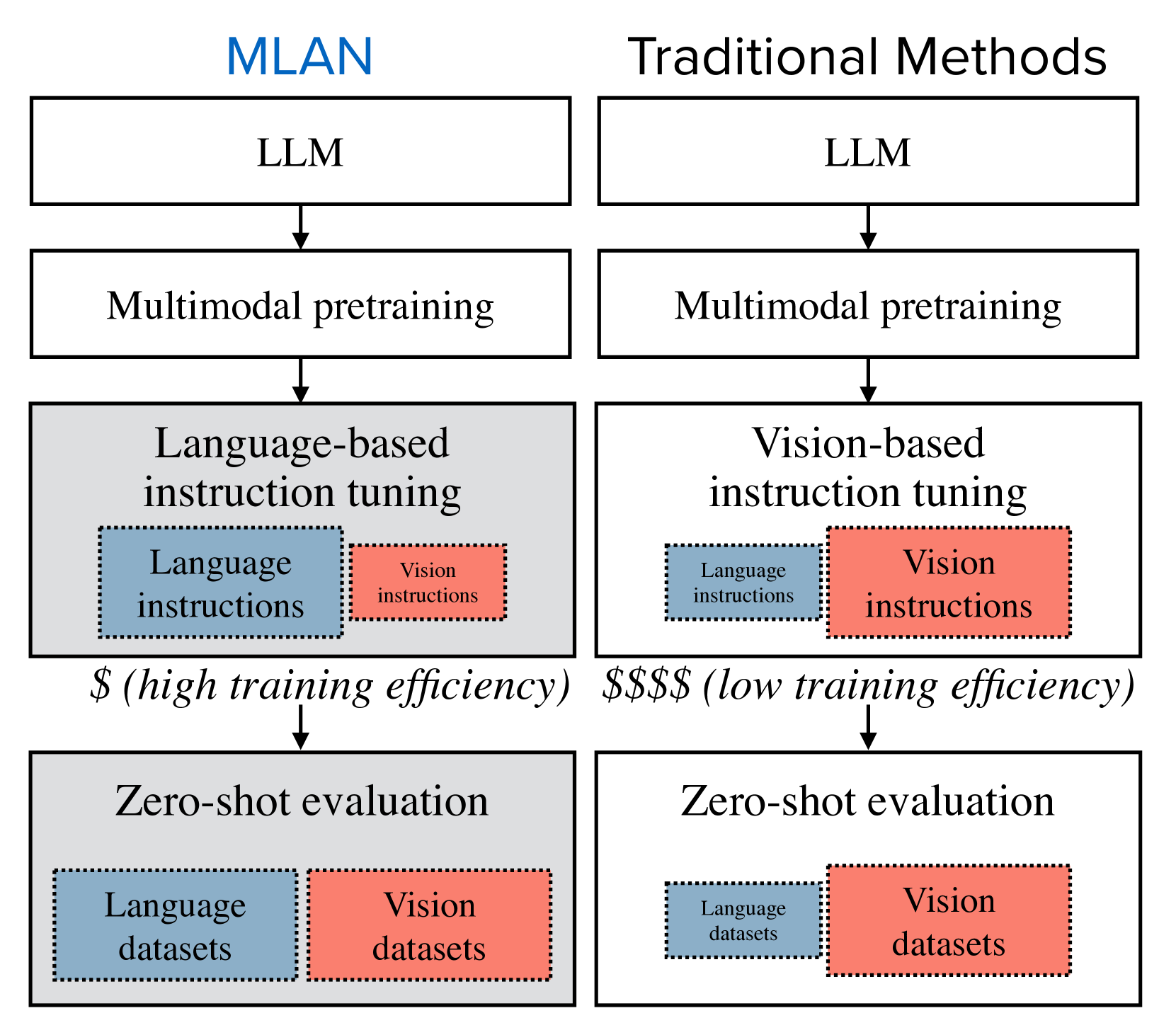
- 现有视觉指令微调方法过度依赖视觉-语言数据,忽略了纯文本数据的重要性,限制了模型的知识迁移能力。
- MLAN通过在视觉指令微调中引入多样化的纯文本数据,构建坚实的文本知识库,提升模型的零样本泛化能力。
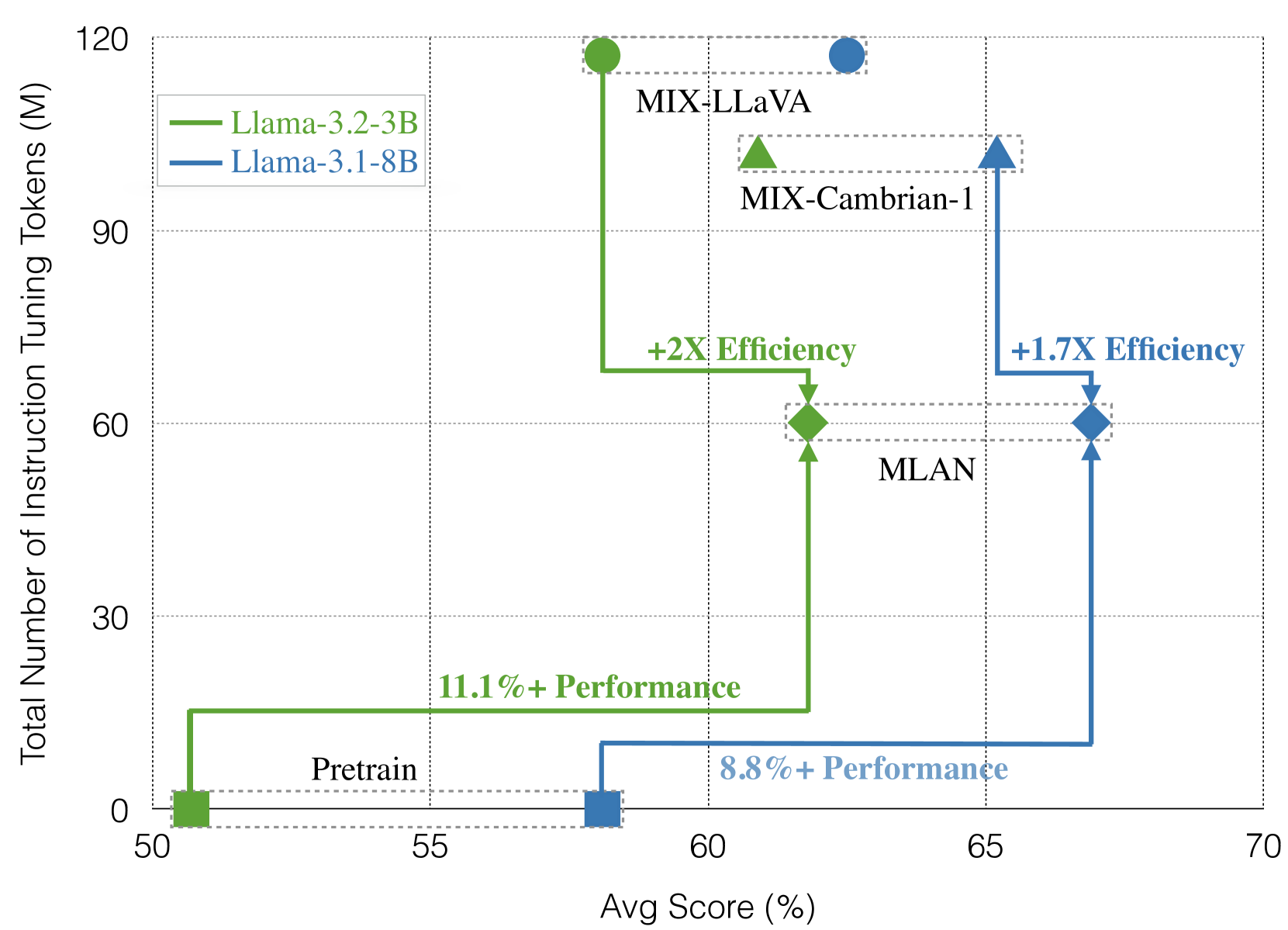
- 实验表明,MLAN在减少训练tokens的同时,能够达到与传统视觉主导方法相当的性能,并有效迁移知识。
📝 摘要(中文)
本文提出了一种新颖的视觉指令微调策略,旨在通过构建坚实的纯文本知识库来提升多模态大型语言模型的零样本任务泛化能力。现有工作缺乏对指令微调阶段各模态重要性的充分实验,通常使用大量的视觉-语言数据,而限制了纯文本数据,并固定了模态的混合比例。通过在视觉指令微调阶段加入多样化的纯文本数据,并在各种受控实验中改变视觉-语言数据,我们研究了模态在视觉指令微调中的重要性。全面的评估表明,文本主导的指令微调方法在跨12个通用数据集上,能够在两种模态上达到与传统视觉主导混合方法相当的性能,同时使用的总训练tokens减少了一半。我们发现,简单地增加足够多样化的纯文本数据,就能实现跨模态的指令遵循能力和领域知识的迁移,并且比视觉-语言方法更有效。
🔬 方法详解
问题定义:现有视觉指令微调方法通常侧重于视觉-语言数据的混合,而对纯文本数据的使用不足,这限制了模型从文本中学习和迁移知识的能力。这种不平衡的数据使用方式可能导致模型在处理纯文本任务时表现不佳,并且难以泛化到新的领域。
核心思路:MLAN的核心思路是通过增加纯文本数据的比例,在视觉指令微调阶段构建一个更强大的文本知识库。这样做的目的是让模型更好地理解和遵循指令,并将这些知识迁移到视觉相关的任务中。通过文本数据增强模型的指令理解能力,从而提升其在多模态任务中的表现。
技术框架:MLAN的整体框架是在现有的多模态大型语言模型的基础上进行指令微调。关键在于调整训练数据的组成,增加纯文本数据的比例,并进行受控实验来评估不同模态数据组合的影响。训练过程仍然采用标准的指令微调流程,但更强调文本数据的作用。
关键创新:MLAN最重要的创新点在于强调了纯文本数据在视觉指令微调中的重要性,并证明了通过增加文本数据可以更有效地提升模型的泛化能力和知识迁移能力。与以往侧重视觉-语言数据的方法不同,MLAN提供了一种更高效且更具可扩展性的训练策略。
关键设计:MLAN的关键设计在于对训练数据的精细控制。论文通过控制视觉-语言数据和纯文本数据的比例,以及文本数据的多样性,来研究不同数据组合对模型性能的影响。具体的参数设置和损失函数与标准的指令微调方法相同,但更注重数据配比的优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MLAN在12个通用数据集上,能够在两种模态上达到与传统视觉主导混合方法相当的性能,同时使用的总训练tokens减少了一半。这表明,通过增加纯文本数据,可以更有效地训练多模态模型,并提升其在各种任务中的表现。
🎯 应用场景
MLAN可应用于各种多模态任务,例如图像描述生成、视觉问答、视觉推理等。该研究成果有助于提升多模态模型的通用性和泛化能力,使其在实际应用中能够更好地理解和处理复杂的视觉信息,并根据指令完成相应的任务。此外,该方法在降低训练成本和提高效率方面也具有重要意义。
📄 摘要(原文)
We present a novel visual instruction tuning strategy to improve the zero-shot task generalization of multimodal large language models by building a firm text-only knowledge base. Existing work lacks sufficient experimentation on the importance of each modality in the instruction tuning stage, often using a majority of vision-language data while keeping text-only data limited and fixing mixtures of modalities. By incorporating diverse text-only data in the visual instruction tuning stage, we vary vision-language data in various controlled experiments to investigate the importance of modality in visual instruction tuning. Our comprehensive evaluation shows that the text-heavy instruction tuning approach is able to perform on-par with traditional vision-heavy mixtures on both modalities across 12 general datasets while using as low as half the total training tokens. We find that simply increasing sufficiently diverse text-only data enables transfer of instruction following ability and domain knowledge across modalities while being more efficient than the vision-language approach.