Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
作者: Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, Jifeng Dai
分类: cs.CL, cs.CV
发布日期: 2024-11-15 (更新: 2025-04-07)
💡 一句话要点
提出混合偏好优化(MPO)方法,提升多模态大语言模型(MLLM)的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 偏好优化 思维链 多模态推理 数据集构建
📋 核心要点
- 现有MLLM在预训练和微调后,面临分布偏移问题,导致多模态推理能力,特别是CoT性能下降。
- 论文提出混合偏好优化(MPO)方法,通过偏好学习增强MLLM的多模态推理能力,提升CoT性能。
- 实验表明,MPO能有效提升InternVL2-8B和InternVL2-76B的性能,InternVL2-8B-MPO在MathVista上提升显著。
📝 摘要(中文)
现有的开源多模态大语言模型(MLLM)通常采用预训练和监督微调的训练流程。然而,这些模型存在分布偏移问题,限制了它们的多模态推理能力,尤其是在思维链(CoT)性能方面。为了解决这个问题,我们引入了一种偏好优化(PO)过程来增强MLLM的多模态推理能力。具体来说,(1)在数据方面,我们设计了一个自动化的偏好数据构建流程,创建了MMPR,一个高质量、大规模的多模态推理偏好数据集;(2)在模型方面,我们探索了将PO与MLLM集成,开发了一种简单而有效的方法,称为混合偏好优化(MPO),它可以提高多模态CoT性能。我们的方法增强了InternVL2-8B和InternVL2-76B的多模态推理能力。值得注意的是,我们的模型InternVL2-8B-MPO在MathVista上实现了67.0的准确率,超过了InternVL2-8B 8.7个百分点,并且达到了与大10倍的InternVL2-76B相当的性能。我们希望这项研究能够激发MLLM的进一步发展。代码、数据和模型已发布。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在经过预训练和监督微调后,由于数据分布偏移而导致的推理能力下降问题,尤其是在需要复杂推理的Chain-of-Thought (CoT) 任务中。现有方法难以有效提升MLLM在这些任务上的表现。
核心思路:论文的核心思路是利用偏好优化(Preference Optimization, PO)来引导模型学习更符合人类偏好的推理路径。通过构建高质量的偏好数据集,并设计合适的优化方法,使模型能够生成更准确、更合理的推理过程,从而提升整体的推理性能。
技术框架:整体框架包含两个主要部分:一是多模态推理偏好数据集(MMPR)的构建流程,二是混合偏好优化(MPO)方法的实现。MMPR数据集通过自动化流程生成,包含多个推理场景下的偏好数据。MPO方法则将偏好优化集成到MLLM的训练过程中,通过调整模型的输出分布,使其更符合偏好数据。
关键创新:论文的关键创新在于提出了混合偏好优化(MPO)方法,这是一种将偏好学习与MLLM相结合的有效策略。与传统的监督微调相比,MPO能够更好地利用人类的偏好信息,引导模型学习更有效的推理策略。此外,自动化偏好数据构建流程也是一个重要的创新,它降低了构建高质量偏好数据的成本。
关键设计:MPO的关键设计包括:(1) MMPR数据集的构建,需要设计合适的prompt和评估指标来生成高质量的偏好数据;(2) 偏好优化损失函数的设计,需要平衡模型生成结果的准确性和多样性;(3) 如何将偏好优化与现有的MLLM训练流程相结合,以最小的代价实现性能提升。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
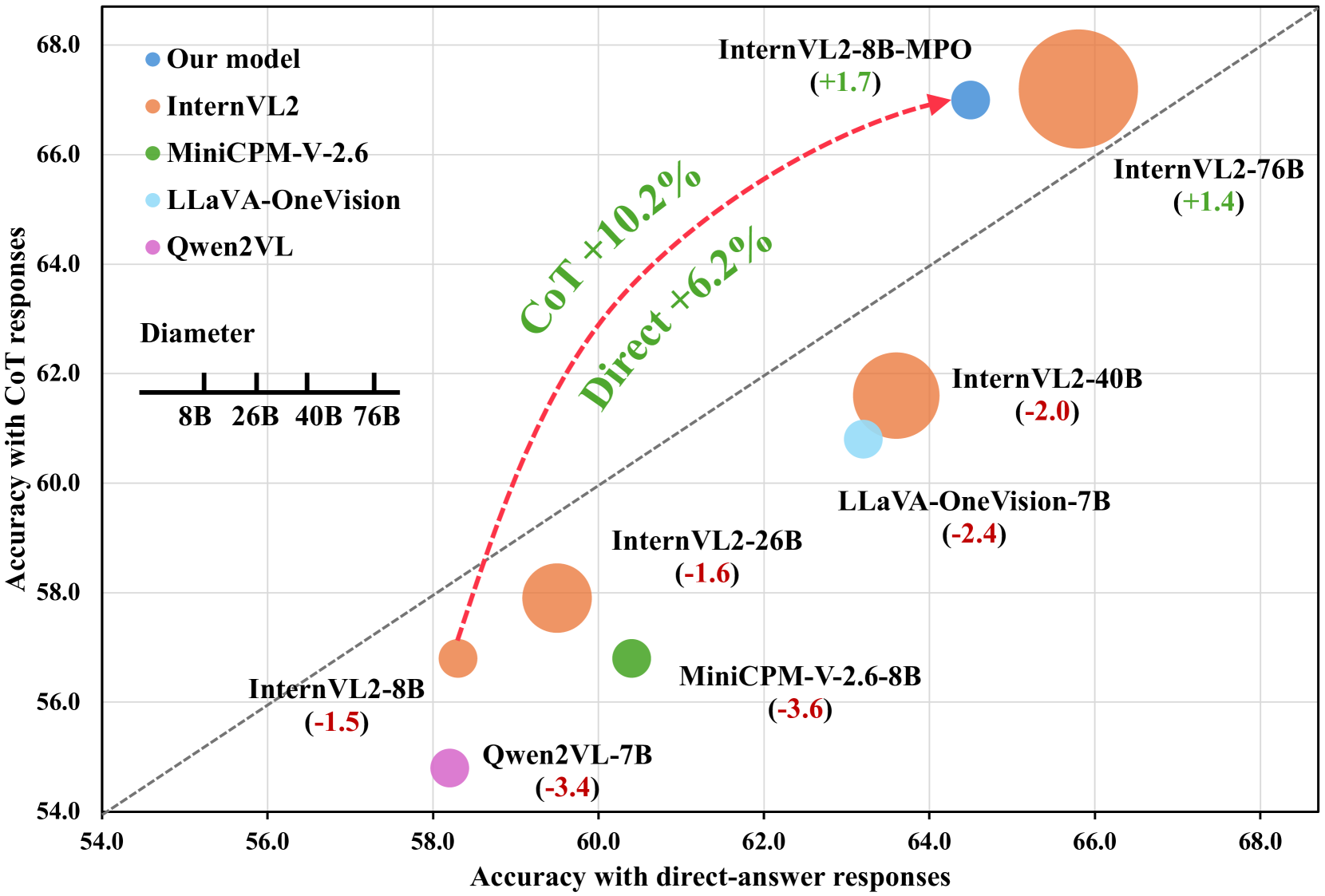


📊 实验亮点
实验结果表明,提出的MPO方法能够显著提升MLLM的多模态推理能力。例如,InternVL2-8B-MPO在MathVista数据集上取得了67.0%的准确率,相比于InternVL2-8B提升了8.7个百分点,并且达到了与参数量大10倍的InternVL2-76B相当的性能。这些结果验证了MPO方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要多模态信息理解和推理的场景,例如智能问答、视觉对话、机器人导航、医疗诊断等。通过提升MLLM的推理能力,可以提高这些应用场景的智能化水平和用户体验。未来,该方法有望扩展到更多模态和更复杂的推理任务中,推动通用人工智能的发展。
📄 摘要(原文)
Existing open-source multimodal large language models (MLLMs) generally follow a training process involving pre-training and supervised fine-tuning. However, these models suffer from distribution shifts, which limit their multimodal reasoning, particularly in the Chain-of-Thought (CoT) performance. To address this, we introduce a preference optimization (PO) process to enhance the multimodal reasoning capabilities of MLLMs. Specifically, (1) on the data side, we design an automated preference data construction pipeline to create MMPR, a high-quality, large-scale multimodal reasoning preference dataset; and (2) on the model side, we explore integrating PO with MLLMs, developing a simple yet effective method, termed Mixed Preference Optimization (MPO), which boosts multimodal CoT performance. Our approach enhances the multimodal reasoning abilities of both InternVL2-8B and InternVL2-76B. Notably, our model, InternVL2-8B-MPO, achieves an accuracy of 67.0 on MathVista, outperforming InternVL2-8B by 8.7 points and achieving performance comparable to the 10$\times$ larger InternVL2-76B. We hope this study could inspire further advancements in MLLMs. Code, data, and model are released.