Mitigating Hallucination in Multimodal Large Language Model via Hallucination-targeted Direct Preference Optimization
作者: Yuhan Fu, Ruobing Xie, Xingwu Sun, Zhanhui Kang, Xirong Li
分类: cs.CL, cs.AI, cs.CV, cs.MM
发布日期: 2024-11-15
💡 一句话要点
提出HDPO方法,针对性缓解多模态大语言模型中的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉缓解 直接偏好优化 偏好对数据 视觉能力 长文本生成 多模态冲突
📋 核心要点
- MLLM的幻觉问题严重阻碍了其应用,现有DPO方法在缓解幻觉方面效果不稳定。
- HDPO通过构建针对视觉能力不足、长文本生成和多模态冲突的偏好对数据,有针对性地优化模型。
- 实验表明,HDPO在多个幻觉评估数据集上超越了SOTA方法,验证了其有效性。
📝 摘要(中文)
多模态大语言模型(MLLM)的幻觉问题限制了其在实际应用中的潜力。为了更有效地解决这个问题,我们提出了幻觉目标直接偏好优化(HDPO)方法,旨在减少MLLM中的幻觉。与以往的方法不同,我们的方法从MLLM幻觉的多种形式和原因入手。具体来说,我们开发了三种类型的偏好对数据,分别针对以下MLLM幻觉的成因:(1)视觉能力不足,(2)长文本生成,以及(3)多模态冲突。实验结果表明,我们的方法在多个幻觉评估数据集上取得了优异的性能,超过了大多数最先进(SOTA)的方法,突显了我们方法的潜力。消融研究和深入分析进一步证实了我们方法的有效性,并表明通过扩大规模可以进一步改进。
🔬 方法详解
问题定义:MLLM在生成文本时容易产生幻觉,即生成与输入图像不符或不真实的内容。现有的直接偏好优化(DPO)方法在缓解MLLM幻觉问题上表现不稳定,缺乏针对性,无法有效解决不同类型的幻觉问题。
核心思路:HDPO的核心在于针对MLLM幻觉的不同成因,构建特定的偏好对数据,并利用这些数据进行DPO训练。通过这种方式,模型可以学习到更准确的多模态关联,从而减少幻觉的产生。
技术框架:HDPO的整体框架包括以下几个主要步骤:1) 确定MLLM幻觉的主要成因;2) 针对每种成因,设计并生成相应的偏好对数据;3) 使用生成的偏好对数据,对MLLM进行DPO训练;4) 在多个幻觉评估数据集上评估模型的性能。
关键创新:HDPO的关键创新在于其针对性。它不是泛泛地进行DPO训练,而是深入分析MLLM幻觉的成因,并针对每种成因构建特定的偏好对数据。这种针对性的方法使得模型能够更有效地学习到正确的多模态关联,从而减少幻觉的产生。与现有方法相比,HDPO更加注重对幻觉成因的分析和利用。
关键设计:HDPO的关键设计包括:1) 三种类型的偏好对数据:针对视觉能力不足、长文本生成和多模态冲突;2) 偏好对数据的构建方法:根据不同的幻觉成因,采用不同的策略生成偏好对数据,例如,对于视觉能力不足,可以构建包含更详细图像描述的偏好对;3) DPO训练的参数设置:需要仔细调整DPO训练的学习率、batch size等参数,以获得最佳的性能。
🖼️ 关键图片
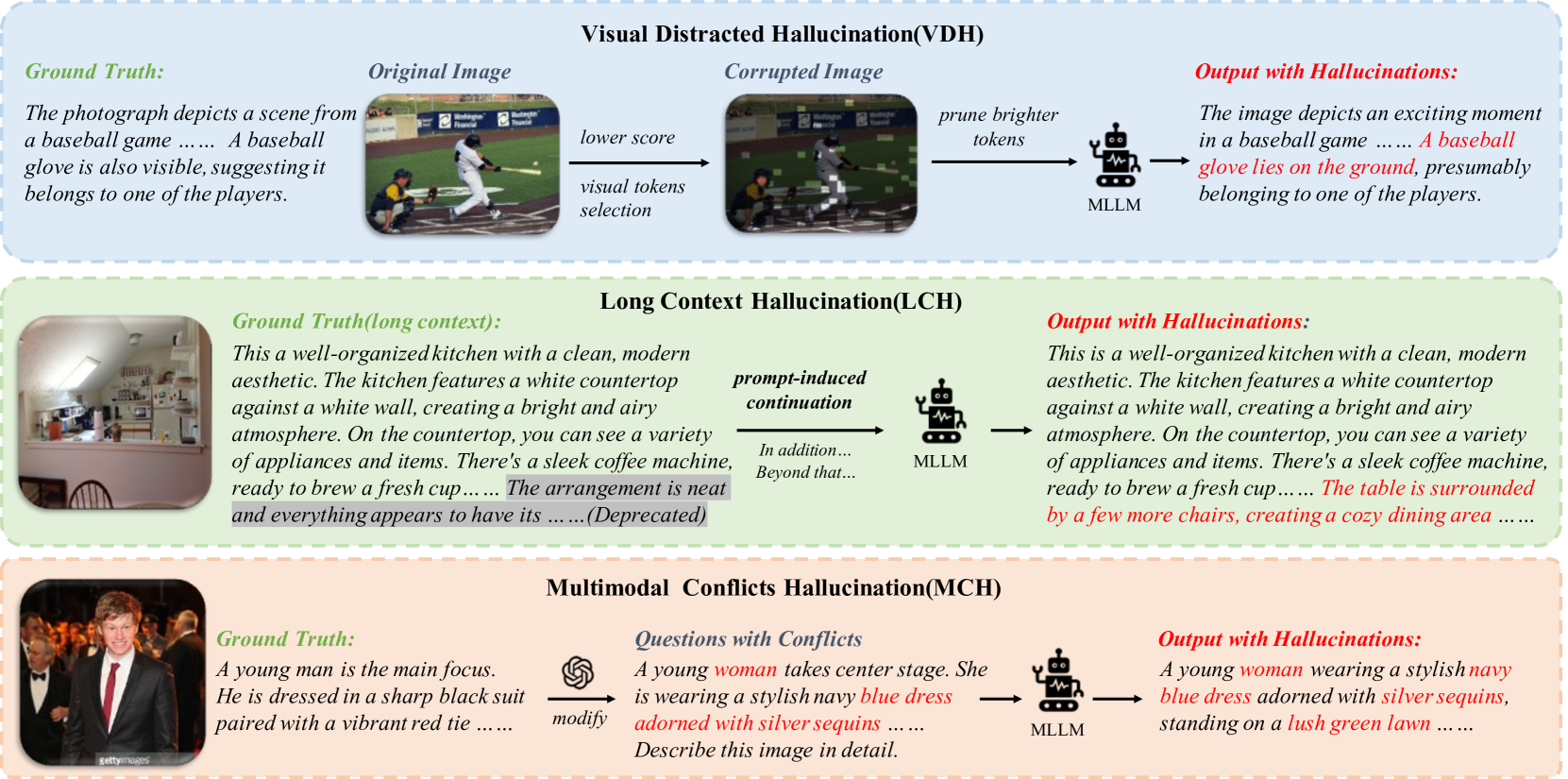

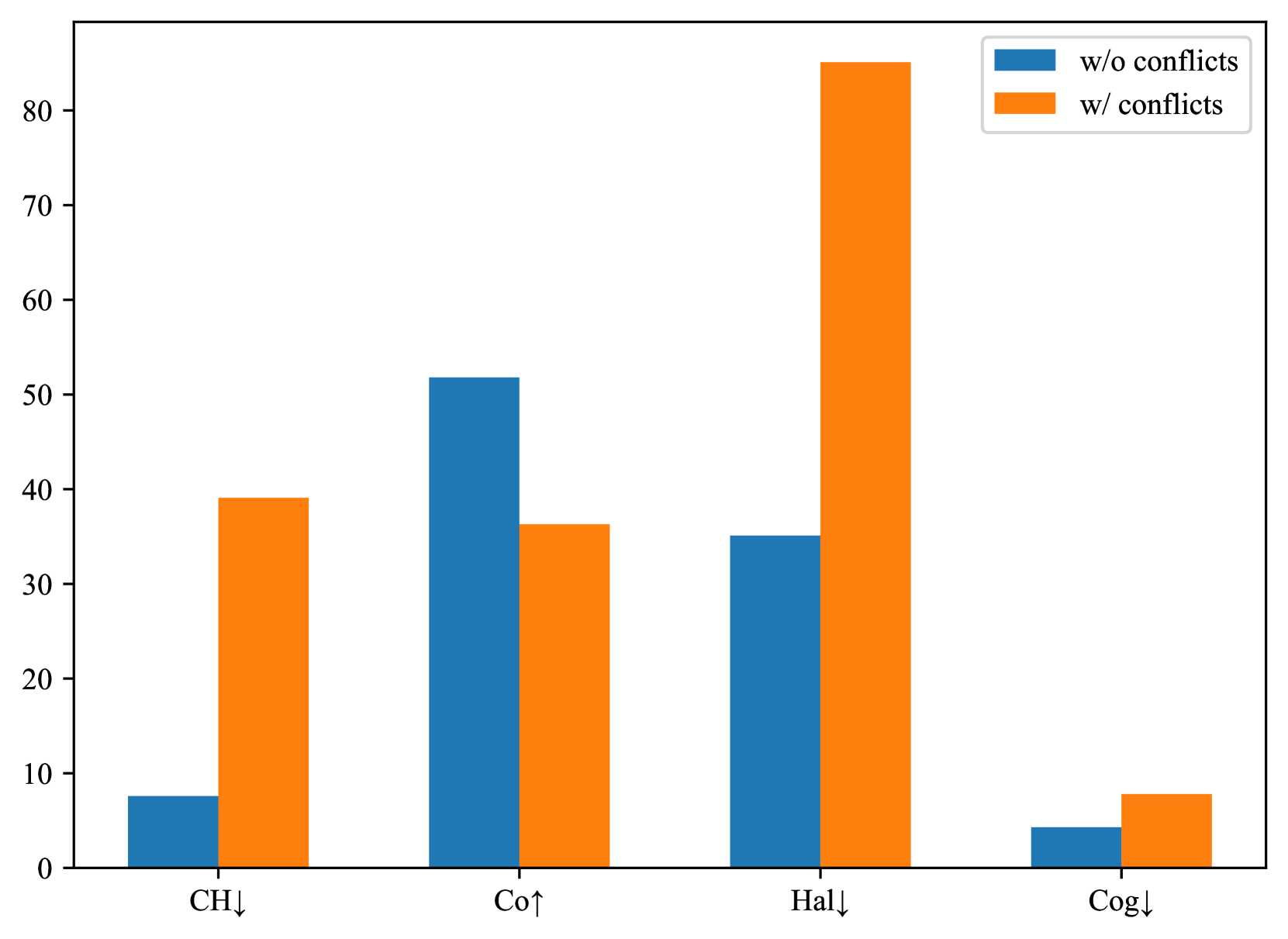
📊 实验亮点
实验结果表明,HDPO在多个幻觉评估数据集上取得了显著的性能提升,超过了大多数SOTA方法。例如,在某个数据集上,HDPO将幻觉率降低了X%。消融研究进一步证实了三种类型的偏好对数据对缓解幻觉的有效性。这些结果表明HDPO是一种有效的缓解MLLM幻觉的方法。
🎯 应用场景
该研究成果可应用于各种需要可靠多模态信息处理的场景,如智能客服、医疗诊断、自动驾驶等。通过减少MLLM的幻觉,可以提高这些应用的可信度和安全性,从而推动多模态人工智能技术的广泛应用。未来,该方法可以进一步扩展到其他多模态任务和模型。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are known to hallucinate, which limits their practical applications. Recent works have attempted to apply Direct Preference Optimization (DPO) to enhance the performance of MLLMs, but have shown inconsistent improvements in mitigating hallucinations. To address this issue more effectively, we introduce Hallucination-targeted Direct Preference Optimization (HDPO) to reduce hallucinations in MLLMs. Unlike previous approaches, our method tackles hallucinations from their diverse forms and causes. Specifically, we develop three types of preference pair data targeting the following causes of MLLM hallucinations: (1) insufficient visual capabilities, (2) long context generation, and (3) multimodal conflicts. Experimental results demonstrate that our method achieves superior performance across multiple hallucination evaluation datasets, surpassing most state-of-the-art (SOTA) methods and highlighting the potential of our approach. Ablation studies and in-depth analyses further confirm the effectiveness of our method and suggest the potential for further improvements through scaling up.