Compound-QA: A Benchmark for Evaluating LLMs on Compound Questions
作者: Yutao Hou, Yajing Luo, Zhiwen Ruan, Hongru Wang, Weifeng Ge, Yun Chen, Guanhua Chen
分类: cs.CL
发布日期: 2024-11-15
💡 一句话要点
提出Compound-QA基准,用于评估LLM在复合问题上的理解、推理和知识能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 复合问题 评估基准 问答系统 自然语言处理
📋 核心要点
- 现有LLM评估基准侧重于单个问题,忽略了真实场景中复杂交互,无法有效评估LLM的综合能力。
- 提出Compound-QA基准,通过合成包含多个子问题的复合问题,全面评估LLM的理解、推理和知识能力。
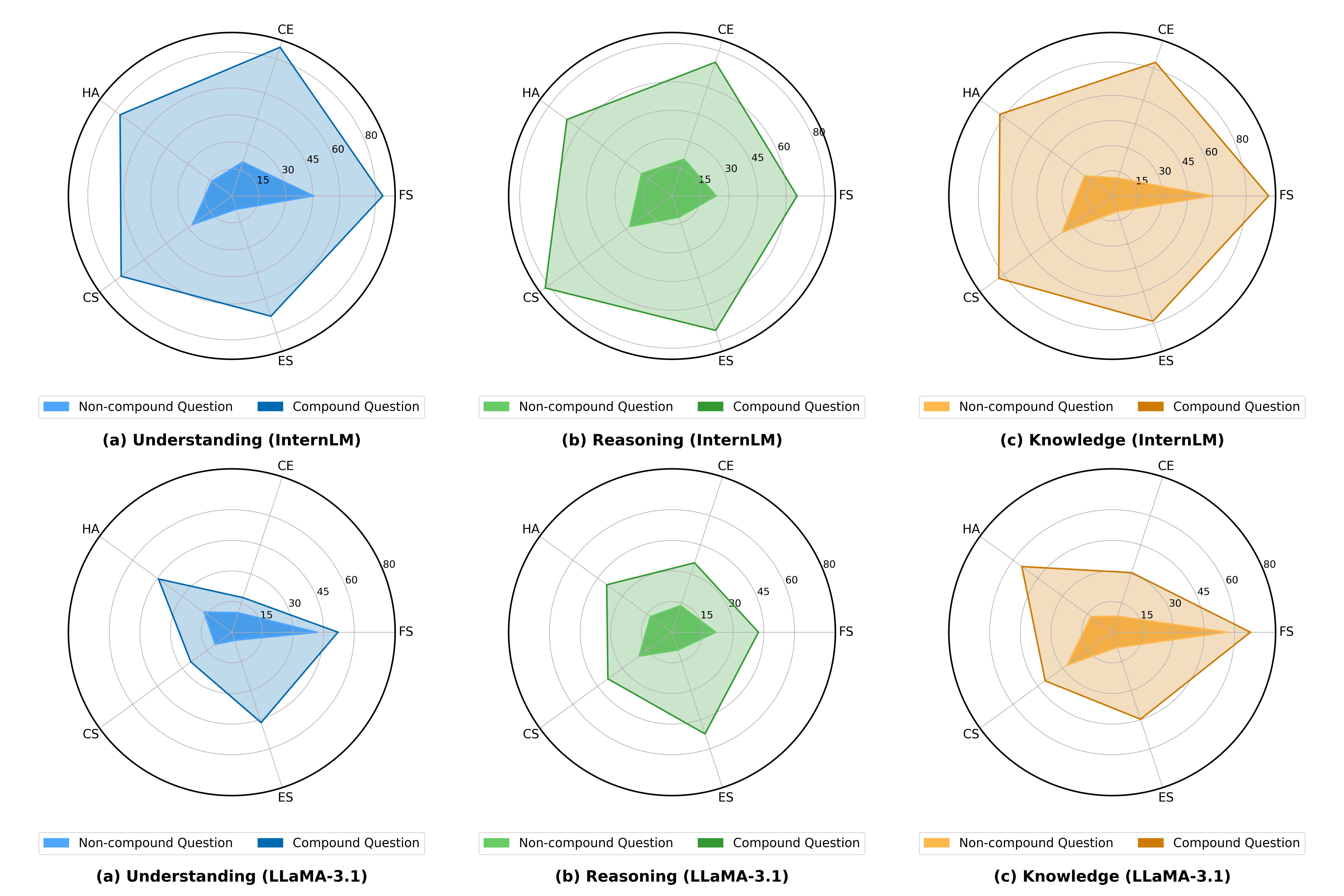
- 实验表明,开源LLM在复合问题上的表现明显低于非复合问题,验证了Compound-QA基准的有效性,并探索了提升LLM性能的方法。
📝 摘要(中文)
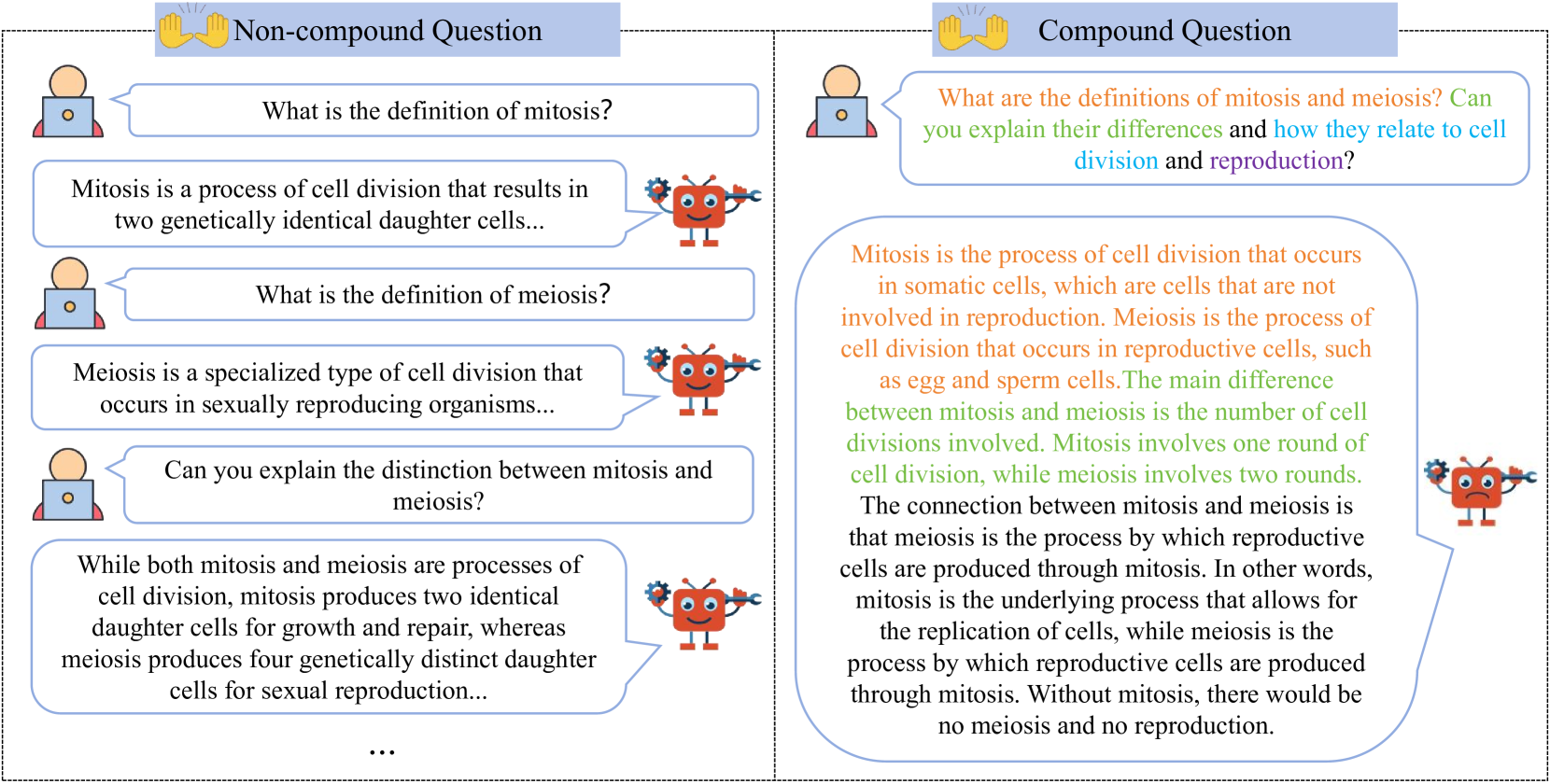
大型语言模型(LLMs)在各种任务中表现出卓越的性能,促使研究人员开发多样化的评估基准。然而,现有的基准通常只衡量LLMs对单个问题的响应能力,忽略了现实应用中复杂的交互。本文提出了复合问题合成(CQ-Syn)方法,创建了Compound-QA基准,专注于包含多个子问题的复合问题。该基准来源于现有的QA数据集,使用专有的LLMs进行标注,并通过人工验证保证准确性。它包含五个类别:事实陈述、因果关系、假设分析、比较选择和评估建议。该基准从理解、推理和知识三个维度评估LLM的能力。使用Compound-QA对八个开源LLMs的评估揭示了它们在复合问题上的响应模式,这些模式明显逊色于对非复合问题的响应。此外,我们研究了各种方法来提高LLMs在复合问题上的性能。结果表明,这些方法显著提高了模型在复合问题上的理解和推理能力。
🔬 方法详解
问题定义:论文旨在解决现有LLM评估基准无法有效评估LLM在处理复杂、多步骤推理的复合问题上的能力的问题。现有基准主要关注单个问题的回答,忽略了真实场景中问题往往包含多个子问题,需要综合理解和推理才能解决的特点。
核心思路:论文的核心思路是构建一个包含复合问题的基准数据集,通过评估LLM在这些问题上的表现,更全面地衡量其理解、推理和知识能力。通过分析LLM在复合问题上的错误类型,可以更好地了解其弱点,并指导模型改进。
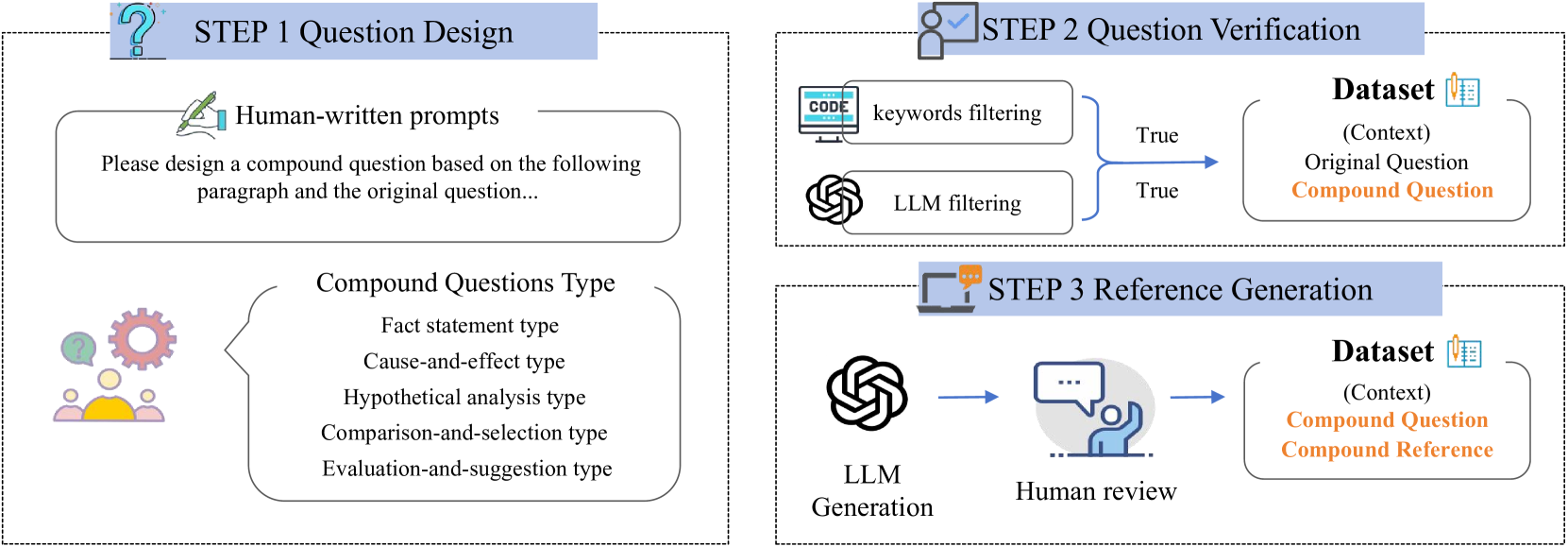
技术框架:Compound-QA基准的构建流程主要包括以下几个阶段:1) 从现有QA数据集中选择问题;2) 使用CQ-Syn方法生成复合问题,该方法涉及将原始问题分解为多个子问题,并组合成一个复合问题;3) 使用专有LLM对复合问题进行标注;4) 通过人工验证确保标注的准确性。该基准包含五个类别:事实陈述、因果关系、假设分析、比较选择和评估建议。
关键创新:该论文的关键创新在于提出了Compound-QA基准,该基准专注于评估LLM在复合问题上的表现。与现有基准相比,Compound-QA更贴近真实应用场景,能够更全面地评估LLM的综合能力。此外,论文还提出了CQ-Syn方法,用于自动生成复合问题,降低了基准构建的成本。
关键设计:CQ-Syn方法是生成复合问题的关键。具体实现细节未知,但可以推测其可能涉及以下设计:1) 子问题分解策略,如何将原始问题分解为多个语义相关的子问题;2) 子问题组合策略,如何将分解后的子问题组合成一个连贯、合理的复合问题;3) 约束条件,例如限制复合问题的长度、子问题的数量等,以保证生成问题的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,开源LLM在Compound-QA基准上的表现明显低于非复合问题,验证了复合问题对LLM的挑战性。通过引入特定的增强方法,LLM在复合问题上的理解和推理能力得到了显著提升。具体性能数据未知,但结果表明该基准能够有效区分不同LLM的性能差异,并指导模型改进。
🎯 应用场景
Compound-QA基准可用于评估和比较不同LLM在复杂推理任务中的性能,指导LLM的改进和优化。该基准的应用领域包括智能客服、问答系统、智能助手等,有助于提升这些系统在处理复杂用户查询时的准确性和效率。未来,该基准可以扩展到更多领域,例如医疗诊断、金融分析等。
📄 摘要(原文)
Large language models (LLMs) demonstrate remarkable performance across various tasks, prompting researchers to develop diverse evaluation benchmarks. However, existing benchmarks typically measure the ability of LLMs to respond to individual questions, neglecting the complex interactions in real-world applications. In this paper, we introduce Compound Question Synthesis (CQ-Syn) to create the Compound-QA benchmark, focusing on compound questions with multiple sub-questions. This benchmark is derived from existing QA datasets, annotated with proprietary LLMs and verified by humans for accuracy. It encompasses five categories: Factual-Statement, Cause-and-Effect, Hypothetical-Analysis, Comparison-and-Selection, and Evaluation-and-Suggestion. It evaluates the LLM capability in terms of three dimensions including understanding, reasoning, and knowledge. Our assessment of eight open-source LLMs using Compound-QA reveals distinct patterns in their responses to compound questions, which are significantly poorer than those to non-compound questions. Additionally, we investigate various methods to enhance LLMs performance on compound questions. The results indicate that these approaches significantly improve the models' comprehension and reasoning abilities on compound questions.