Prompting and Fine-tuning Large Language Models for Automated Code Review Comment Generation
作者: Md. Asif Haider, Ayesha Binte Mostofa, Sk. Sabit Bin Mosaddek, Anindya Iqbal, Toufique Ahmed
分类: cs.SE, cs.CL, cs.LG
发布日期: 2024-11-15
💡 一句话要点
利用提示工程与微调大语言模型,实现自动化代码评审意见生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码评审 大语言模型 提示工程 微调 QLoRA 函数调用图 代码摘要
📋 核心要点
- 代码评审意见生成任务具有多样性和非唯一性,现有方法难以生成准确的评审意见。
- 通过参数高效的QLoRA微调开源LLM,并结合函数调用图和代码摘要进行提示工程,提升模型性能。
- 实验表明,该方法在CodeReviewer数据集上显著提升了BLEU-4分数,并通过人工评估验证了有效性。
📝 摘要(中文)
生成准确的代码评审意见仍然是一个重大挑战,因为任务输出本质上是多样且非唯一的。在编程和自然语言数据上预训练的大语言模型在面向代码的任务中表现良好。然而,大规模预训练由于其环境影响和项目特定的泛化问题,并非总是可行的。在这项工作中,我们首先在消费级硬件上以参数高效的量化低秩(QLoRA)方式微调开源大语言模型(LLM),以改进评审意见生成。最近的研究表明,将语义元数据信息增强到提示中可以提高其他代码相关任务的性能。为了在代码评审活动中探索这一点,我们还提示专有的、闭源的LLM,用函数调用图和代码摘要来增强输入代码补丁。我们的两种策略都提高了评审意见生成性能,在CodeReviewer数据集上,GPT-3.5模型上使用函数调用图增强的少样本提示超过了预训练基线约90%的BLEU-4分数。此外,少样本提示的Gemini-1.0 Pro、QLoRA微调的Code Llama和Llama 3.1模型在此任务上取得了有竞争力的结果(性能提升范围从25%到83%)。一项额外的人工评估研究进一步验证了我们的实验结果,反映了现实世界开发人员基于相关定性指标对LLM生成的代码评审意见的看法。
🔬 方法详解
问题定义:论文旨在解决自动化代码评审意见生成的问题。现有方法难以生成准确且有用的评审意见,因为代码评审是一个主观且复杂的任务,涉及理解代码的意图、发现潜在的错误和提出改进建议。现有方法的痛点在于无法充分利用代码的语义信息,并且难以适应不同的代码风格和项目需求。
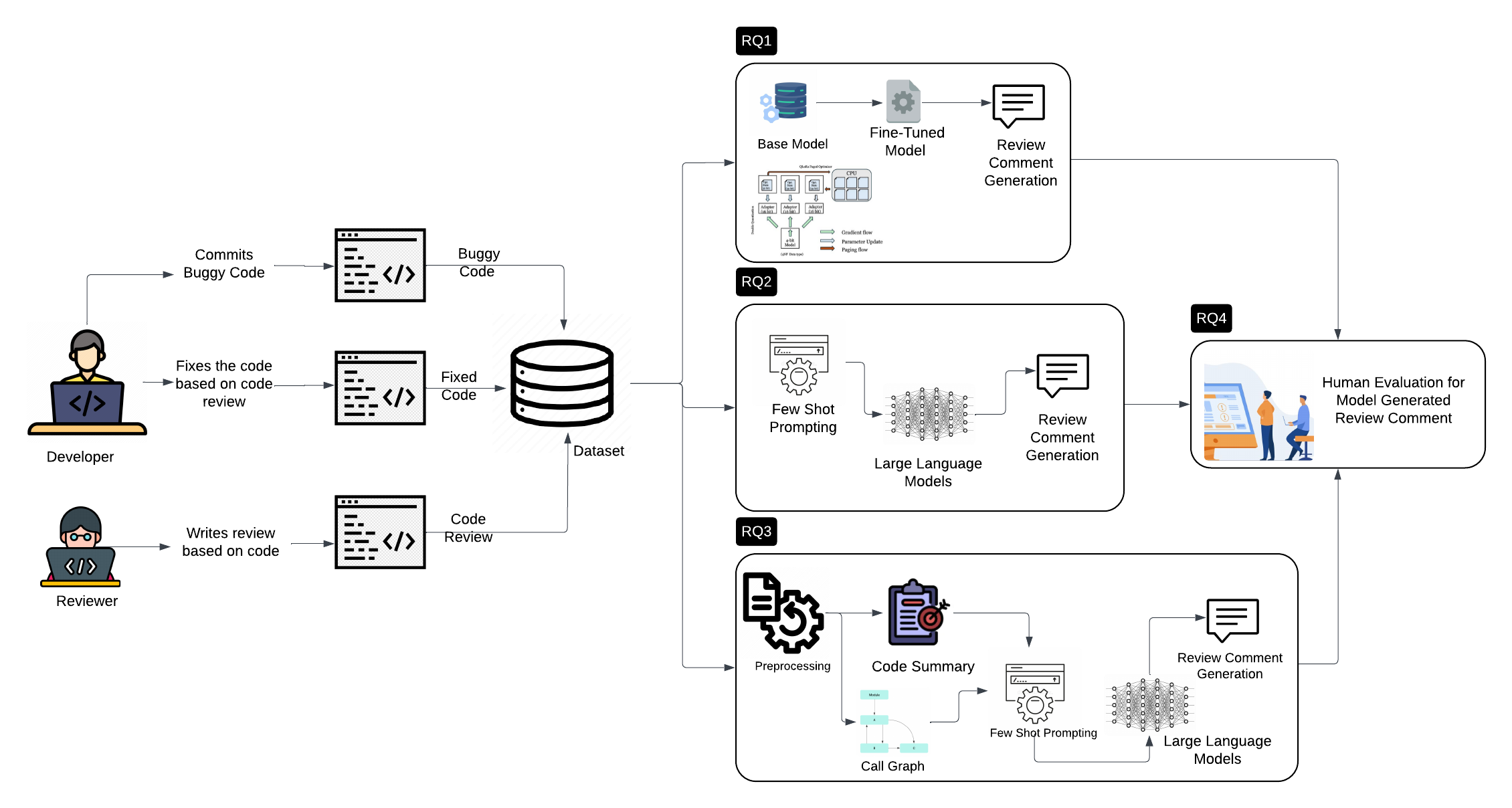
核心思路:论文的核心思路是利用大语言模型(LLM)的强大能力,通过微调和提示工程来改进代码评审意见生成。具体来说,论文探索了两种策略:一是使用参数高效的QLoRA方法微调开源LLM,使其更好地适应代码评审任务;二是利用函数调用图和代码摘要等语义元数据来增强LLM的输入提示,使其能够更好地理解代码的上下文和意图。
技术框架:论文的技术框架主要包括两个部分:QLoRA微调和提示工程。QLoRA微调部分使用开源LLM(如Code Llama和Llama 3.1)作为基础模型,并在消费级硬件上进行微调。提示工程部分使用闭源LLM(如GPT-3.5和Gemini-1.0 Pro),并结合函数调用图和代码摘要等语义元数据来构建输入提示。整个流程包括数据预处理、模型训练/推理和结果评估等步骤。
关键创新:论文的关键创新在于将参数高效的QLoRA微调和提示工程相结合,应用于自动化代码评审意见生成任务。通过QLoRA微调,可以在有限的计算资源下训练出性能良好的代码评审模型。通过提示工程,可以利用代码的语义信息来指导LLM生成更准确和有用的评审意见。此外,论文还探索了使用函数调用图和代码摘要等不同类型的语义元数据对提示效果的影响。
关键设计:在QLoRA微调方面,论文采用了量化和低秩分解等技术来减少模型参数量和计算复杂度。在提示工程方面,论文设计了不同的提示模板,将代码补丁、函数调用图和代码摘要等信息整合到输入提示中。此外,论文还使用了少样本学习的方法,通过提供少量示例来指导LLM生成评审意见。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用函数调用图增强的少样本提示在GPT-3.5模型上,CodeReviewer数据集的BLEU-4分数超过预训练基线约90%。少样本提示的Gemini-1.0 Pro、QLoRA微调的Code Llama和Llama 3.1模型也取得了有竞争力的结果,性能提升范围从25%到83%。人工评估也验证了LLM生成的代码评审意见的有效性。
🎯 应用场景
该研究成果可应用于自动化代码评审工具,帮助开发人员提高代码质量、减少错误和加快开发速度。通过自动生成评审意见,可以减轻人工评审的负担,并提供更一致和全面的评审结果。此外,该技术还可以用于代码教育和代码理解等领域,帮助初学者学习代码规范和理解代码逻辑。
📄 摘要(原文)
Generating accurate code review comments remains a significant challenge due to the inherently diverse and non-unique nature of the task output. Large language models pretrained on both programming and natural language data tend to perform well in code-oriented tasks. However, large-scale pretraining is not always feasible due to its environmental impact and project-specific generalizability issues. In this work, first we fine-tune open-source Large language models (LLM) in parameter-efficient, quantized low-rank (QLoRA) fashion on consumer-grade hardware to improve review comment generation. Recent studies demonstrate the efficacy of augmenting semantic metadata information into prompts to boost performance in other code-related tasks. To explore this in code review activities, we also prompt proprietary, closed-source LLMs augmenting the input code patch with function call graphs and code summaries. Both of our strategies improve the review comment generation performance, with function call graph augmented few-shot prompting on the GPT-3.5 model surpassing the pretrained baseline by around 90% BLEU-4 score on the CodeReviewer dataset. Moreover, few-shot prompted Gemini-1.0 Pro, QLoRA fine-tuned Code Llama and Llama 3.1 models achieve competitive results (ranging from 25% to 83% performance improvement) on this task. An additional human evaluation study further validates our experimental findings, reflecting real-world developers' perceptions of LLM-generated code review comments based on relevant qualitative metrics.