Orca: Enhancing Role-Playing Abilities of Large Language Models by Integrating Personality Traits
作者: Yuxuan Huang
分类: cs.CL, cs.AI
发布日期: 2024-11-15
🔗 代码/项目: GITHUB
💡 一句话要点
Orca:融合人格特质,提升大型语言模型角色扮演能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色扮演 人格特质 个性化对话系统 指令调优
📋 核心要点
- 现有角色扮演对话系统主要关注通过设计角色配置文件来增强模型遵循指令的能力,忽略了驱动人类对话的心理因素。
- Orca框架通过整合人格特质,进行数据处理和训练,从而定制具有特定人格的角色扮演大型语言模型。
- 实验结果表明,Orca模型在OrcaBench基准测试中表现优异,证明了其在感知人格特质和提升角色扮演能力方面的有效性。
📝 摘要(中文)
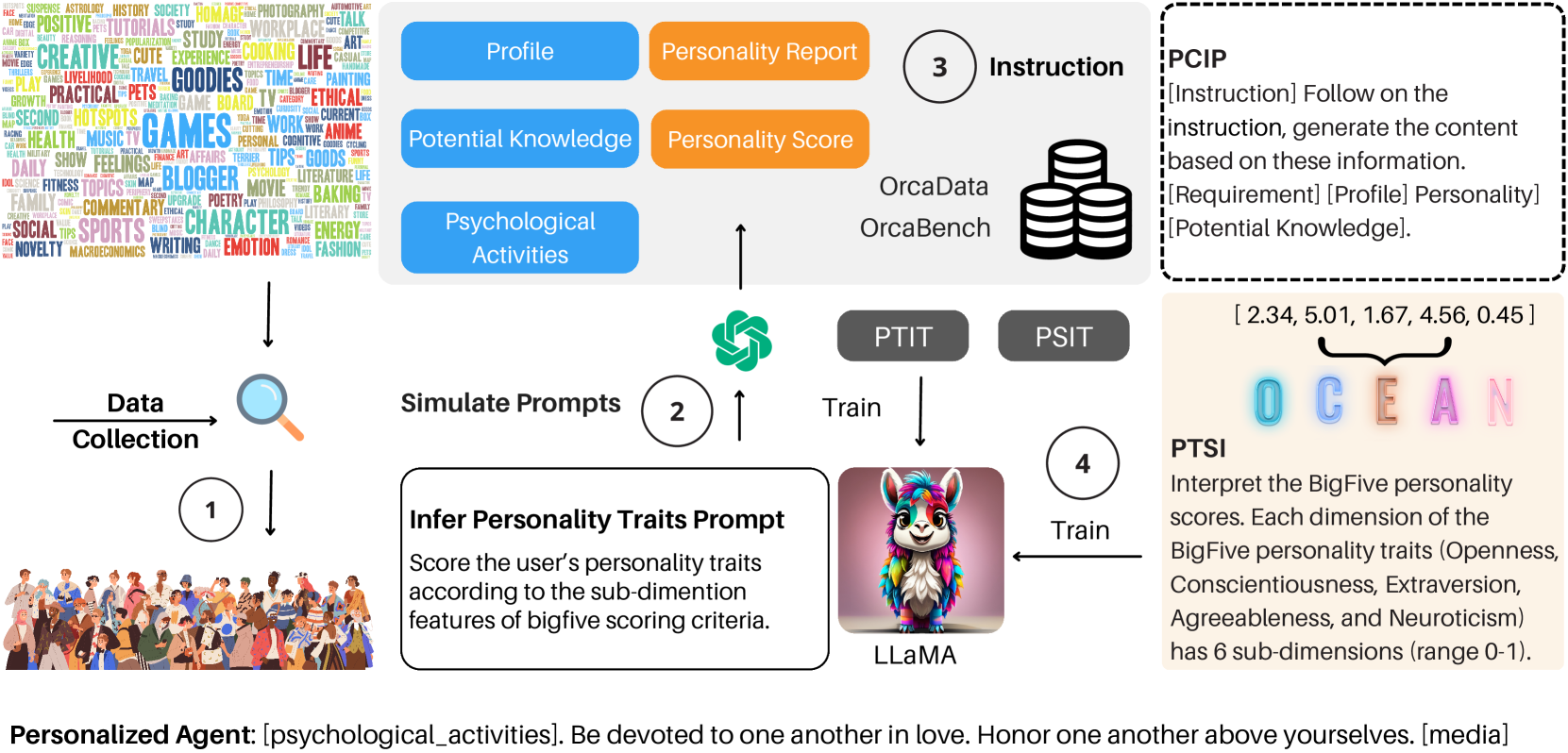
本文提出Orca框架,通过整合人格特质来处理数据和训练定制角色的大型语言模型,旨在提升个性化对话系统的性能。Orca框架包含四个阶段:(1)人格特质推断,利用大型语言模型推断用户的BigFive人格特质报告和分数。(2)数据增强,模拟用户的个人资料、背景故事和心理活动。(3)数据集构建,采用人格条件指令提示(PCIP)来刺激大型语言模型。(4)建模和训练,使用生成的数据进行人格条件指令调优(PTIT和PSIT),以增强现有的开源大型语言模型。此外,本文还引入了OrcaBench,这是第一个用于评估大型语言模型在社交平台上生成内容质量的多尺度基准。实验结果表明,所提出的模型在该基准上表现出色,证明了其在感知人格特质方面的卓越性和有效性,从而显著提高了角色扮演能力。
🔬 方法详解
问题定义:现有角色扮演对话系统主要关注指令遵循,忽略了人类对话中重要的人格心理因素,导致生成的对话缺乏真实感和个性化。因此,需要一种方法能够将人格特质融入到大型语言模型的训练中,从而提升其角色扮演能力。
核心思路:Orca的核心思路是将用户的人格特质融入到大型语言模型的训练数据和训练过程中。通过推断用户的人格特质,模拟用户的人物背景和心理活动,并使用人格条件指令提示来刺激模型,从而使模型能够生成更具个性化和真实感的对话。
技术框架:Orca框架包含四个主要阶段:(1)人格特质推断:利用大型语言模型推断用户的人格特质。(2)数据增强:模拟用户的个人资料、背景故事和心理活动。(3)数据集构建:使用人格条件指令提示(PCIP)来构建训练数据集。(4)建模和训练:使用生成的数据进行人格条件指令调优(PTIT和PSIT),以增强现有的开源大型语言模型。
关键创新:Orca的关键创新在于将人格特质融入到大型语言模型的训练过程中。通过人格特质推断、数据增强和人格条件指令提示等技术,使模型能够更好地理解和模拟不同人格的角色,从而生成更具个性化和真实感的对话。此外,OrcaBench基准测试的提出也为评估角色扮演对话系统的性能提供了一个新的标准。
关键设计:Orca框架中,人格特质推断使用预训练的大型语言模型,例如GPT-3。数据增强阶段使用规则和模板来生成用户的个人资料、背景故事和心理活动。人格条件指令提示(PCIP)通过在指令中加入人格特质信息来引导模型生成特定人格的回复。人格条件指令调优(PTIT和PSIT)使用交叉熵损失函数来优化模型参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Orca模型在OrcaBench基准测试中表现优异,显著提高了大型语言模型在角色扮演任务中的性能。具体而言,Orca模型在多个指标上都优于现有的基线模型,证明了其在感知人格特质和生成个性化对话方面的有效性。这些结果表明,将人格特质融入到大型语言模型的训练中可以显著提升其角色扮演能力。
🎯 应用场景
Orca框架可应用于各种个性化对话系统,例如虚拟助手、社交机器人和游戏角色。通过整合人格特质,可以使这些系统能够更好地理解和响应用户的需求,从而提供更个性化和更具吸引力的用户体验。该研究的成果有助于推动人机交互领域的发展,并为构建更智能、更人性化的对话系统奠定基础。
📄 摘要(原文)
Large language models has catalyzed the development of personalized dialogue systems, numerous role-playing conversational agents have emerged. While previous research predominantly focused on enhancing the model's capability to follow instructions by designing character profiles, neglecting the psychological factors that drive human conversations. In this paper, we propose Orca, a framework for data processing and training LLMs of custom characters by integrating personality traits. Orca comprises four stages: (1) Personality traits inferring, leverage LLMs to infer user's BigFive personality trait reports and scores. (2) Data Augment, simulate user's profile, background story, and psychological activities. (3) Dataset construction, personality-conditioned instruction prompting (PCIP) to stimulate LLMs. (4) Modeling and Training, personality-conditioned instruction tuning (PTIT and PSIT), using the generated data to enhance existing open-source LLMs. We introduce OrcaBench, the first benchmark for evaluating the quality of content generated by LLMs on social platforms across multiple scales. Our experiments demonstrate that our proposed model achieves superior performance on this benchmark, demonstrating its excellence and effectiveness in perceiving personality traits that significantly improve role-playing abilities. Our Code is available at https://github.com/Aipura/Orca.