Adaptive Decoding via Latent Preference Optimization
作者: Shehzaad Dhuliawala, Ilia Kulikov, Ping Yu, Asli Celikyilmaz, Jason Weston, Sainbayar Sukhbaatar, Jack Lanchantin
分类: cs.CL
发布日期: 2024-11-14
💡 一句话要点
提出基于隐偏好优化的自适应解码方法,动态调整语言模型生成温度以提升性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应解码 隐偏好优化 语言模型 采样温度 动态调整
📋 核心要点
- 现有语言模型解码时,固定温度无法兼顾创造性和事实准确性,高温度更具创造性,低温度更准确。
- 提出自适应解码方法,通过学习动态调整采样温度,以适应不同任务对创造性和准确性的需求。
- 引入隐偏好优化(LPO)方法训练模型,实验表明在多种任务上优于固定温度解码。
📝 摘要(中文)
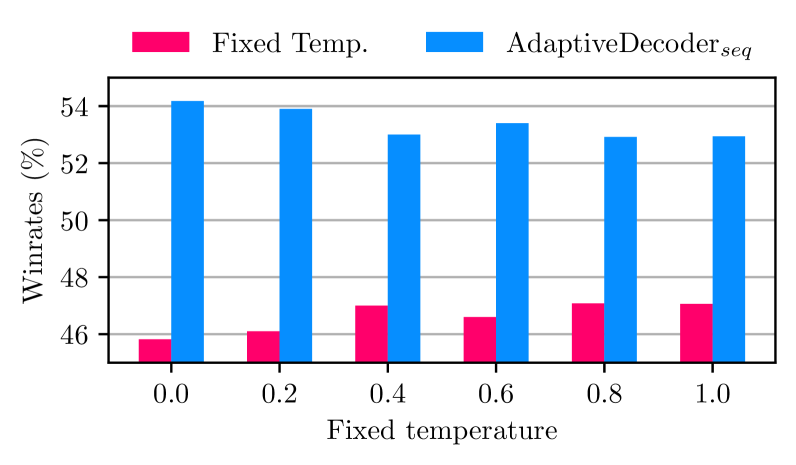
本文提出了一种自适应解码方法,该方法通过在模型中添加一个额外的层,在推理时动态选择采样温度,以优化性能。该方法可以在token级别或example级别调整温度。为了学习该层的参数,我们引入了隐偏好优化(LPO)方法,这是一种训练离散隐变量(如温度选择)的通用方法。实验结果表明,我们的方法在需要不同温度的任务(包括UltraFeedback、创意故事写作和GSM8K)上,优于所有固定解码温度。
🔬 方法详解
问题定义:现有语言模型在解码时通常使用固定的采样温度,这无法很好地适应不同任务的需求。例如,创意写作任务需要较高的温度以产生更多样化的结果,而事实性问答任务则需要较低的温度以保证答案的准确性。因此,如何动态地调整采样温度以适应不同的任务是一个关键问题。
核心思路:本文的核心思路是引入一个可学习的模块,该模块能够根据输入动态地选择合适的采样温度。通过优化该模块的参数,使得模型能够在不同的任务上自动地选择最佳的温度,从而提高整体性能。这种动态调整温度的策略能够更好地平衡创造性和准确性。
技术框架:该方法在现有的语言模型基础上增加了一个自适应解码层。该层的作用是根据模型的上下文表示,预测一个合适的采样温度。具体来说,该层接收模型的隐藏状态作为输入,然后输出一个温度值。在解码过程中,模型使用该温度值进行采样,生成下一个token。整个框架包含两个主要部分:语言模型和自适应解码层。
关键创新:该方法最重要的创新点在于提出了自适应解码的概念,即根据输入动态地调整采样温度。与传统的固定温度解码方法相比,自适应解码能够更好地适应不同任务的需求,从而提高模型的性能。此外,本文还提出了隐偏好优化(LPO)方法,用于训练自适应解码层。
关键设计:自适应解码层可以使用不同的网络结构实现,例如全连接网络或Transformer层。损失函数的设计至关重要,需要能够反映不同任务对创造性和准确性的偏好。LPO方法通过最大化隐变量(即温度选择)的期望奖励来训练模型。具体的参数设置和网络结构需要根据具体的任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在UltraFeedback、创意故事写作和GSM8K等多个任务上均优于所有固定温度的解码方法。具体来说,在UltraFeedback任务上,该方法取得了显著的性能提升,表明其能够更好地适应不同用户的偏好。在创意故事写作任务上,该方法生成的文本更具创造性和多样性。在GSM8K任务上,该方法能够更准确地解决数学问题。
🎯 应用场景
该研究成果可广泛应用于各种需要语言模型生成文本的场景,例如对话系统、机器翻译、文本摘要、故事生成等。通过自适应地调整采样温度,可以提高生成文本的质量和多样性,从而提升用户体验。该方法还有潜力应用于其他离散隐变量的优化问题,例如动作选择、策略学习等。
📄 摘要(原文)
During language model decoding, it is known that using higher temperature sampling gives more creative responses, while lower temperatures are more factually accurate. However, such models are commonly applied to general instruction following, which involves both creative and fact seeking tasks, using a single fixed temperature across all examples and tokens. In this work, we introduce Adaptive Decoding, a layer added to the model to select the sampling temperature dynamically at inference time, at either the token or example level, in order to optimize performance. To learn its parameters we introduce Latent Preference Optimization (LPO) a general approach to train discrete latent variables such as choices of temperature. Our method outperforms all fixed decoding temperatures across a range of tasks that require different temperatures, including UltraFeedback, Creative Story Writing, and GSM8K.