Robustness and Confounders in the Demographic Alignment of LLMs with Human Perceptions of Offensiveness
作者: Shayan Alipour, Indira Sen, Mattia Samory, Tanushree Mitra
分类: cs.CY, cs.CL
发布日期: 2024-11-13 (更新: 2024-11-22)
💡 一句话要点
研究揭示LLM冒犯性判断中的人口统计偏差受混淆因素影响,需多数据集分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人口统计偏差 冒犯性语言 混淆因素 多数据集分析
📋 核心要点
- 现有研究对LLM中人口统计偏差的评估不足,缺乏系统性,且忽略了混淆因素的影响。
- 该研究通过多数据集分析,考察人口统计特征、文档难度、标注者敏感度等因素对LLM冒犯性判断的影响。
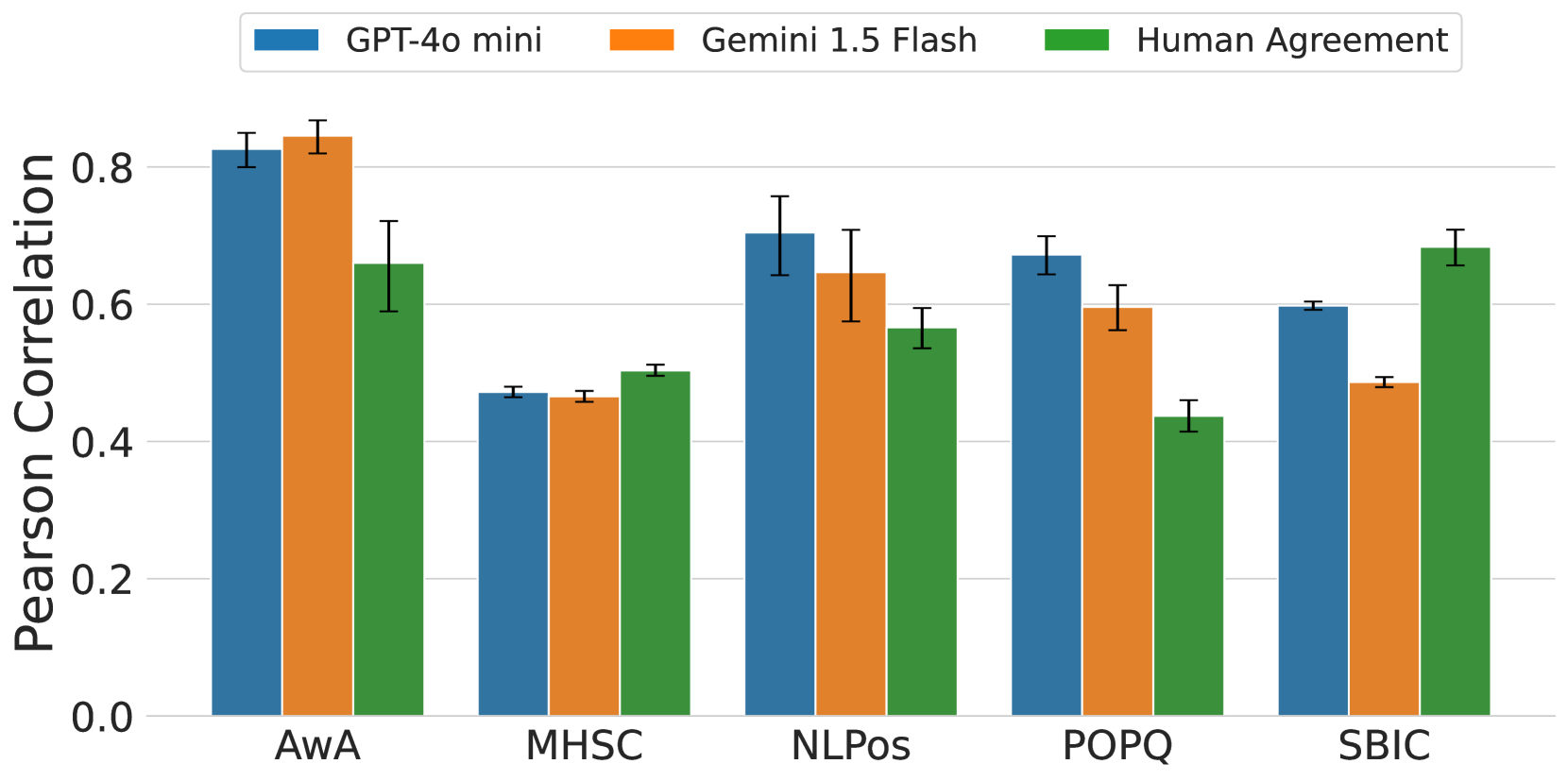
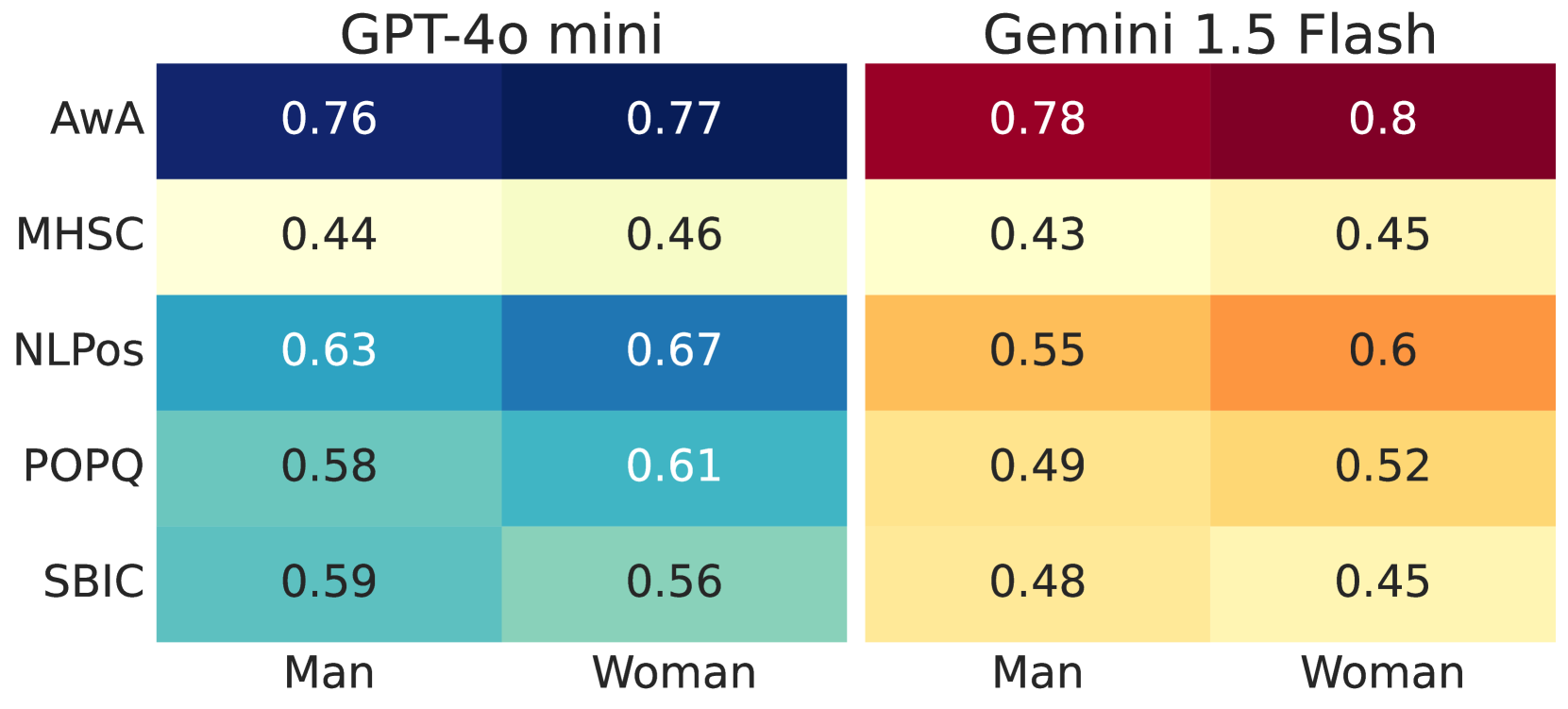
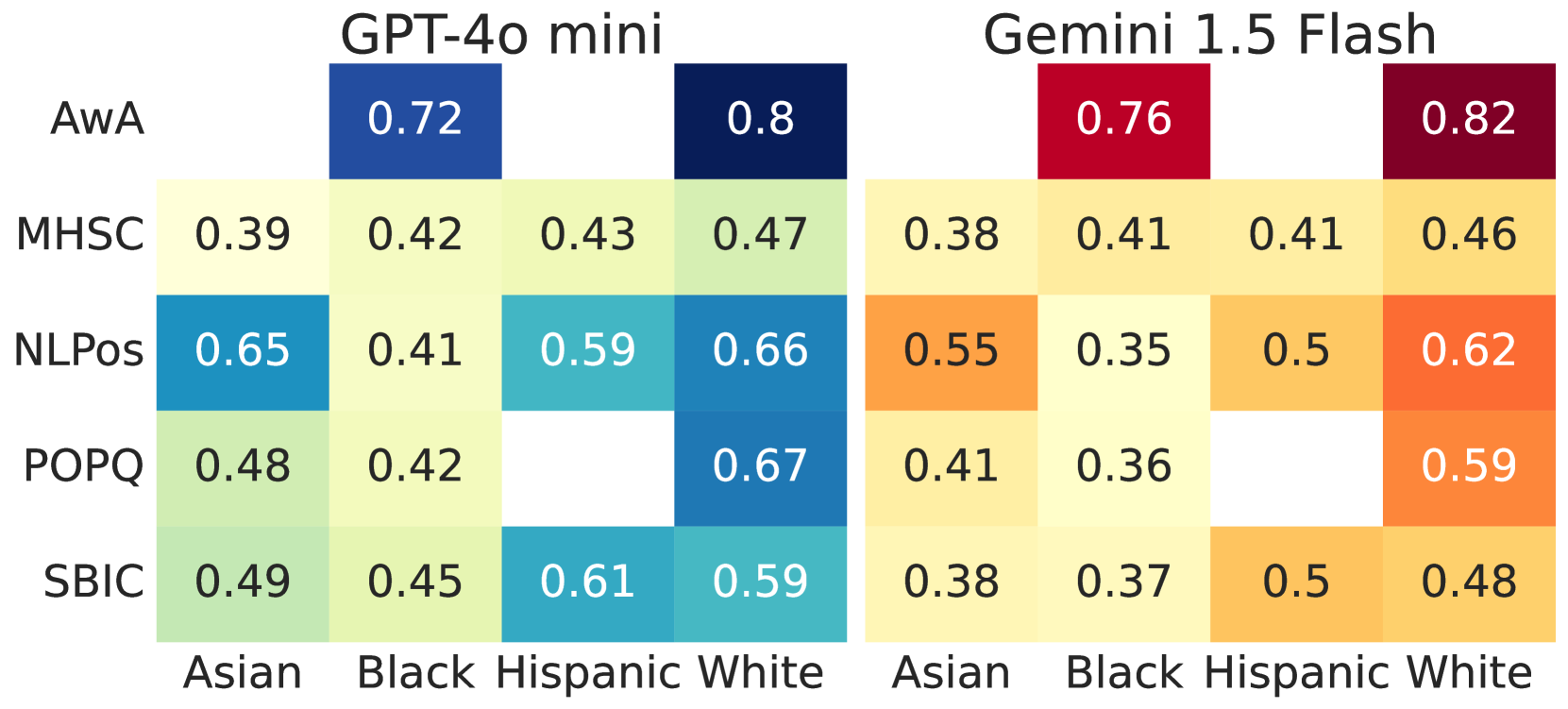
- 实验表明,混淆因素比单纯的人口统计特征更能解释LLM与人类标注一致性的差异,强调了多数据集分析的重要性。
📝 摘要(中文)
大型语言模型(LLM)存在人口统计偏差已是共识,但鲜有研究系统性地评估这些偏差,或考虑混淆因素。本文通过分析五个冒犯性语言数据集(约22万条标注),考察LLM与人类标注在冒犯性判断上的一致性。研究发现,人口统计特征(特别是种族)确实影响一致性,但这种影响在不同数据集之间并不一致,且常与其他因素纠缠在一起。诸如文档难度、标注者敏感度和群体内一致性等混淆因素,比单纯的人口统计特征更能解释一致性模式的差异。具体而言,一致性随标注者敏感度和群体一致性的提高而增加,而文档难度越大,一致性越低。研究结果强调了多数据集分析和考虑混淆因素的方法在开发LLM人口统计偏差的稳健度量中的重要性。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理文本时,会表现出一定程度的人口统计偏差,尤其是在判断文本是否具有冒犯性时。现有的研究往往只关注单一数据集,缺乏跨数据集的验证,并且忽略了其他可能影响判断结果的混淆因素,例如文本本身的难度、标注者的主观敏感度以及标注者群体内部的一致性。这些因素的忽略可能导致对LLM偏差的错误评估。
核心思路:该论文的核心思路是,通过多数据集的分析,同时考虑人口统计特征和多种混淆因素,来更全面、更准确地评估LLM在冒犯性判断上与人类标注的一致性。通过统计建模,量化不同因素对一致性的影响程度,从而揭示LLM偏差的真实来源。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集并整理五个包含冒犯性语言标注的数据集;2) 针对每个数据集,提取人口统计特征(如种族)、文档难度(例如,使用语言模型计算困惑度)、标注者敏感度(例如,通过标注者的标注行为推断)和群体内一致性等特征;3) 使用统计模型(例如,线性回归模型)分析这些特征与LLM和人类标注一致性之间的关系;4) 对比不同数据集上的结果,分析人口统计特征和混淆因素的影响差异。
关键创新:该研究的关键创新在于:1) 强调了多数据集分析的重要性,避免了单一数据集可能带来的偏差;2) 系统性地考虑了多种混淆因素,例如文档难度、标注者敏感度和群体内一致性,从而更准确地评估LLM的偏差;3) 通过统计建模,量化了不同因素对LLM一致性的影响程度,为后续研究提供了参考。
关键设计:在数据收集方面,论文使用了五个公开的冒犯性语言数据集,确保了研究的可靠性和可复现性。在特征提取方面,文档难度通过计算文本的困惑度来衡量,标注者敏感度通过分析标注者的标注行为来推断,群体内一致性通过计算标注者之间的Cohen's Kappa系数来衡量。在统计建模方面,论文使用了线性回归模型,并控制了其他变量的影响,从而更准确地评估了人口统计特征和混淆因素对LLM一致性的影响。
🖼️ 关键图片
📊 实验亮点
研究发现,人口统计特征(如种族)对LLM冒犯性判断的影响在不同数据集上并不一致。更重要的是,文档难度、标注者敏感度和群体内一致性等混淆因素,比单纯的人口统计特征更能解释LLM与人类标注一致性的差异。例如,一致性随标注者敏感度和群体一致性的提高而增加,而文档难度越大,一致性越低。
🎯 应用场景
该研究成果可应用于开发更公平、更可靠的LLM。通过识别和减轻LLM中的人口统计偏差,可以避免模型在实际应用中产生歧视性或冒犯性的输出,例如在内容审核、情感分析和对话系统中。未来的研究可以基于此框架,探索更多混淆因素,并开发更有效的偏差缓解策略。
📄 摘要(原文)
Large language models (LLMs) are known to exhibit demographic biases, yet few studies systematically evaluate these biases across multiple datasets or account for confounding factors. In this work, we examine LLM alignment with human annotations in five offensive language datasets, comprising approximately 220K annotations. Our findings reveal that while demographic traits, particularly race, influence alignment, these effects are inconsistent across datasets and often entangled with other factors. Confounders -- such as document difficulty, annotator sensitivity, and within-group agreement -- account for more variation in alignment patterns than demographic traits alone. Specifically, alignment increases with higher annotator sensitivity and group agreement, while greater document difficulty corresponds to reduced alignment. Our results underscore the importance of multi-dataset analyses and confounder-aware methodologies in developing robust measures of demographic bias in LLMs.