A Comparative Study of Discrete Speech Tokens for Semantic-Related Tasks with Large Language Models
作者: Dingdong Wang, Mingyu Cui, Dongchao Yang, Xueyuan Chen, Helen Meng
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-11-13
备注: 5 tables, 4 figures
💡 一句话要点
对比离散语音Token与连续语音特征在语义相关任务中对大语言模型的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 离散语音Token 连续语音特征 语义理解 性能对比
📋 核心要点
- 现有语音LLM研究多集中于连续语音特征,缺乏对离散语音token与连续特征性能差距的深入分析。
- 本研究通过对比实验,揭示了离散语音token在细粒度语义理解任务中的局限性,并分析了其原因。
- 实验结果表明,连续语音特征通常优于离散token,并提出了改进离散token性能的潜在方向。
📝 摘要(中文)
随着语音大语言模型(Speech LLMs)的兴起,离散语音token因其能与文本token无缝集成而备受关注。与大多数关注连续语音特征的研究不同,尽管基于离散token的LLM在某些任务上表现出良好的结果,但很少有研究探讨这两种范式之间的性能差距。本文使用轻量级LLM(Qwen1.5-0.5B)对各种语义相关任务中的离散和连续特征进行了公平而彻底的比较。研究结果表明,连续特征通常优于离散token,尤其是在需要细粒度语义理解的任务中。此外,本研究超越了表面层面的比较,识别了离散token性能不佳的关键因素,例如有限的token粒度和低效的信息保留。为了提高离散token的性能,我们基于分析探索了潜在的改进方向。我们希望我们的结果能为推进语音LLM中离散语音token提供新的见解。
🔬 方法详解
问题定义:论文旨在解决语音大语言模型中,离散语音token与连续语音特征在语义相关任务上的性能差异问题。现有方法主要集中于连续语音特征,忽略了离散语音token的潜力,且缺乏对二者性能差距的深入分析,导致无法充分发挥语音LLM的性能。
核心思路:论文的核心思路是通过实验对比,量化离散语音token与连续语音特征在不同语义相关任务上的性能差异,并分析导致差异的关键因素,从而为改进离散语音token的性能提供指导。通过分析token粒度、信息保留等因素,找出离散token的瓶颈。
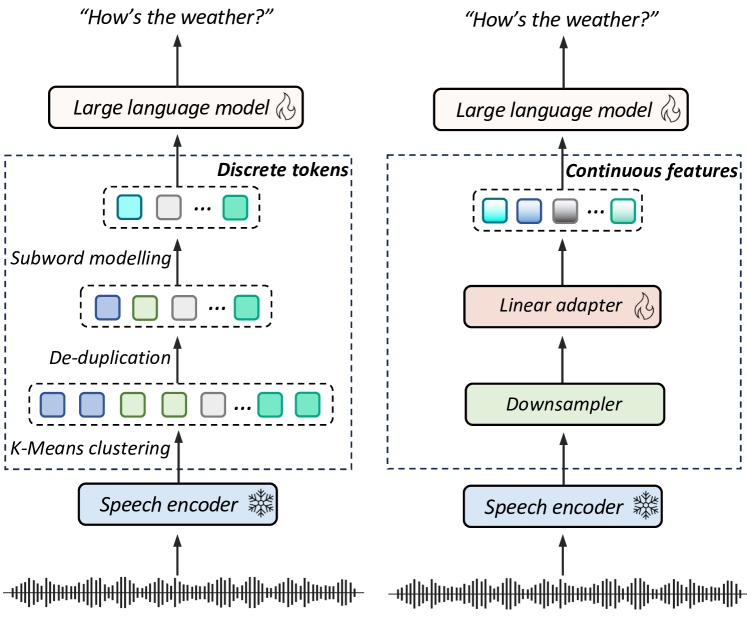
技术框架:论文采用轻量级LLM(Qwen1.5-0.5B)作为实验平台,对比离散语音token和连续语音特征在多个语义相关任务上的表现。具体流程包括:1) 选取合适的离散语音token和连续语音特征提取方法;2) 在Qwen1.5-0.5B上训练和评估模型;3) 分析实验结果,找出性能差异的原因;4) 提出改进离散语音token性能的潜在方向。
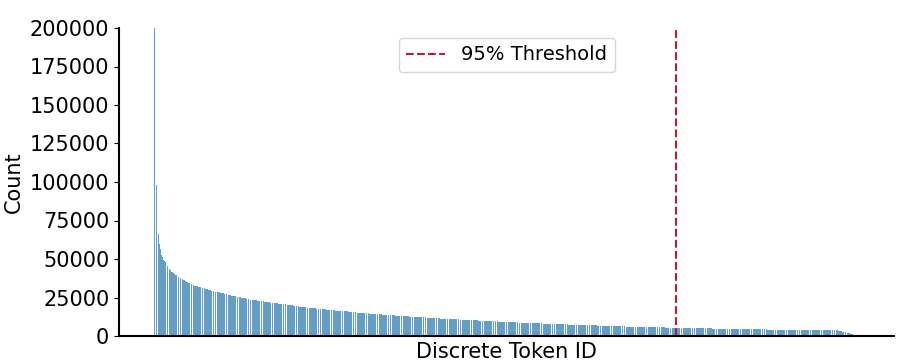
关键创新:论文的关键创新在于对离散语音token与连续语音特征进行了全面的对比分析,并深入探讨了离散语音token性能不佳的原因,例如token粒度不足和信息保留能力有限。这为后续研究提供了新的视角和方向。
关键设计:论文的关键设计包括:1) 选取Qwen1.5-0.5B作为轻量级LLM,降低实验成本;2) 选择多个语义相关任务,保证实验结果的泛化性;3) 对比不同粒度的离散语音token,分析token粒度对性能的影响;4) 分析信息保留能力,例如通过注意力机制分析模型对不同token的关注程度。
🖼️ 关键图片
📊 实验亮点
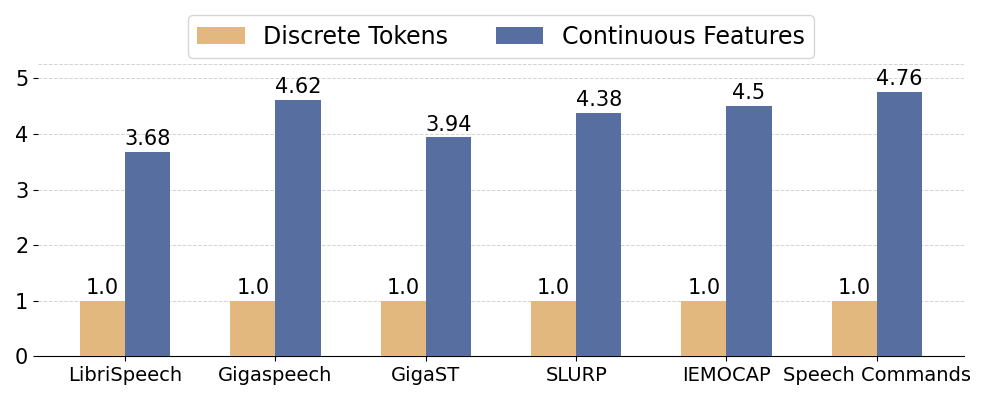
实验结果表明,在需要细粒度语义理解的任务中,连续语音特征通常优于离散语音token。例如,在语音情感识别任务中,使用连续语音特征的模型性能明显高于使用离散语音token的模型。通过分析,发现离散语音token的性能瓶颈在于token粒度不足和信息保留能力有限。该研究为后续改进离散语音token的表示方法提供了重要的参考。
🎯 应用场景
该研究成果可应用于语音识别、语音翻译、语音情感分析等领域。通过优化离散语音token的表示,可以提升语音LLM在各种任务上的性能,从而改善人机交互体验,并为语音技术的进一步发展提供支持。未来的研究可以探索更有效的离散语音token表示方法,例如结合上下文信息或引入更细粒度的token。
📄 摘要(原文)
With the rise of Speech Large Language Models (Speech LLMs), there has been growing interest in discrete speech tokens for their ability to integrate with text-based tokens seamlessly. Compared to most studies that focus on continuous speech features, although discrete-token based LLMs have shown promising results on certain tasks, the performance gap between these two paradigms is rarely explored. In this paper, we present a fair and thorough comparison between discrete and continuous features across a variety of semantic-related tasks using a light-weight LLM (Qwen1.5-0.5B). Our findings reveal that continuous features generally outperform discrete tokens, particularly in tasks requiring fine-grained semantic understanding. Moreover, this study goes beyond surface-level comparison by identifying key factors behind the under-performance of discrete tokens, such as limited token granularity and inefficient information retention. To enhance the performance of discrete tokens, we explore potential aspects based on our analysis. We hope our results can offer new insights into the opportunities for advancing discrete speech tokens in Speech LLMs.