CLaSP: Learning Concepts for Time-Series Signals from Natural Language Supervision
作者: Aoi Ito, Kota Dohi, Yohei Kawaguchi
分类: cs.CL, cs.LG
发布日期: 2024-11-13 (更新: 2025-08-06)
💡 一句话要点
CLaSP:利用自然语言监督学习时间序列信号的概念
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列检索 自然语言查询 对比学习 大型语言模型 工业诊断
📋 核心要点
- 现有时间序列信号检索方法依赖草图、同义词典或手动设计,可扩展性和适应性受限。
- CLaSP采用对比学习,将时间序列信号映射到自然语言描述,无需预定义同义词典。
- 在TRUCE和SUSHI数据集上,CLaSP在基于自然语言查询检索时间序列模式方面表现出高精度。
📝 摘要(中文)
本文提出了一种名为CLaSP的新模型,该模型能够使用描述信号特征的自然语言查询来检索时间序列信号。基于描述性查询搜索时间序列信号的能力在工业诊断等领域至关重要,在这些领域中,数据科学家经常需要找到具有特定特征的信号。然而,现有的方法依赖于基于草图的输入、预定义的同义词词典或特定于领域的手动设计,限制了它们的可扩展性和适应性。CLaSP通过采用对比学习将时间序列信号映射到自然语言描述来解决这些挑战。与先前的方法不同,它消除了对预定义同义词词典的需求,并利用了大型语言模型(LLM)的丰富上下文知识。使用将时间序列信号与自然语言描述配对的TRUCE和SUSHI数据集,我们证明CLaSP在基于自然语言查询检索各种时间序列模式方面实现了高精度。
🔬 方法详解
问题定义:论文旨在解决使用自然语言查询检索时间序列信号的问题。现有方法,如基于草图的输入或预定义的同义词词典,缺乏可扩展性和适应性,难以应对复杂多变的信号特征描述。领域相关的专家知识和手动设计成本高昂,阻碍了广泛应用。
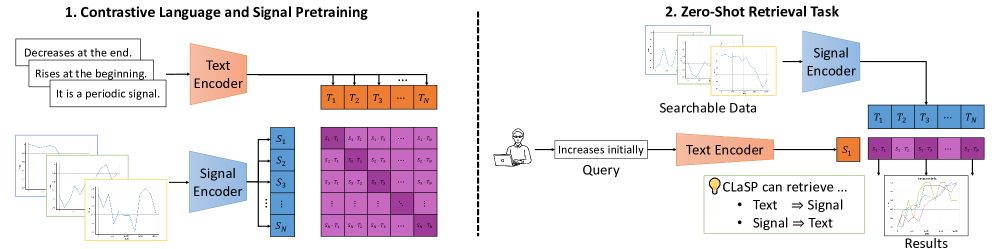
核心思路:CLaSP的核心思路是利用对比学习,将时间序列信号和描述它们的自然语言文本嵌入到同一个语义空间中。通过这种方式,模型能够学习信号和文本之间的对应关系,从而实现基于自然语言查询的信号检索。这种方法避免了对预定义同义词典的依赖,并能够利用大型语言模型(LLM)的上下文理解能力。
技术框架:CLaSP的整体框架包含两个主要模块:时间序列编码器和文本编码器。时间序列编码器负责将时间序列信号转换为向量表示,文本编码器负责将自然语言描述转换为向量表示。然后,使用对比学习目标函数,训练模型使得匹配的时间序列信号和文本描述的向量表示尽可能接近,而不匹配的向量表示尽可能远离。检索时,将查询文本编码为向量,然后在时间序列信号的向量空间中搜索最相似的信号。
关键创新:CLaSP的关键创新在于利用对比学习和大型语言模型,实现了基于自然语言的通用时间序列信号检索。与传统方法相比,它无需手动设计特征或构建同义词典,能够自动学习信号和文本之间的复杂关系。此外,CLaSP能够利用LLM的上下文理解能力,处理更复杂和细粒度的自然语言查询。
关键设计:时间序列编码器可以使用各种模型,例如卷积神经网络(CNN)或循环神经网络(RNN)。文本编码器通常使用预训练的语言模型,例如BERT或RoBERTa。对比学习损失函数通常采用InfoNCE损失,该损失函数旨在最大化正样本对的相似度,同时最小化负样本对的相似度。训练过程中,需要构建正负样本对,正样本对是匹配的时间序列信号和文本描述,负样本对是不匹配的时间序列信号和文本描述。
🖼️ 关键图片
📊 实验亮点
CLaSP在TRUCE和SUSHI数据集上取得了显著的检索精度。实验结果表明,CLaSP能够准确地检索到与自然语言查询相匹配的时间序列信号,优于现有的基于草图或同义词典的方法。具体的性能提升幅度未知,但摘要强调了CLaSP实现了“高精度”。
🎯 应用场景
CLaSP可应用于工业诊断、医疗健康、金融分析等领域。例如,在工业诊断中,工程师可以使用自然语言描述设备异常信号的特征,快速检索到相关的历史数据,从而诊断设备故障。在医疗健康领域,医生可以使用自然语言描述患者的生理信号特征,检索到相似病例,辅助疾病诊断。在金融分析领域,分析师可以使用自然语言描述股票价格走势,检索到历史相似的走势,预测未来趋势。
📄 摘要(原文)
This paper presents CLaSP, a novel model for retrieving time-series signals using natural language queries that describe signal characteristics. The ability to search time-series signals based on descriptive queries is essential in domains such as industrial diagnostics, where data scientists often need to find signals with specific characteristics. However, existing methods rely on sketch-based inputs, predefined synonym dictionaries, or domain-specific manual designs, limiting their scalability and adaptability. CLaSP addresses these challenges by employing contrastive learning to map time-series signals to natural language descriptions. Unlike prior approaches, it eliminates the need for predefined synonym dictionaries and leverages the rich contextual knowledge of large language models (LLMs). Using the TRUCE and SUSHI datasets, which pair time-series signals with natural language descriptions, we demonstrate that CLaSP achieves high accuracy in retrieving a variety of time series patterns based on natural language queries.