Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
作者: Hui Dai, Ryan Teehan, Mengye Ren
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-13 (更新: 2025-07-08)
备注: ICML 2025
💡 一句话要点
提出Daily Oracle,利用每日新闻持续评估LLM的时间泛化能力与预测未来事件的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 时间泛化 未来事件预测 每日新闻 检索增强生成
📋 核心要点
- 现有LLM评估基准缺乏时间维度,无法有效评估模型性能随时间推移的变化。
- 提出Daily Oracle基准,利用每日新闻自动生成QA对,评估LLM预测未来事件的能力。
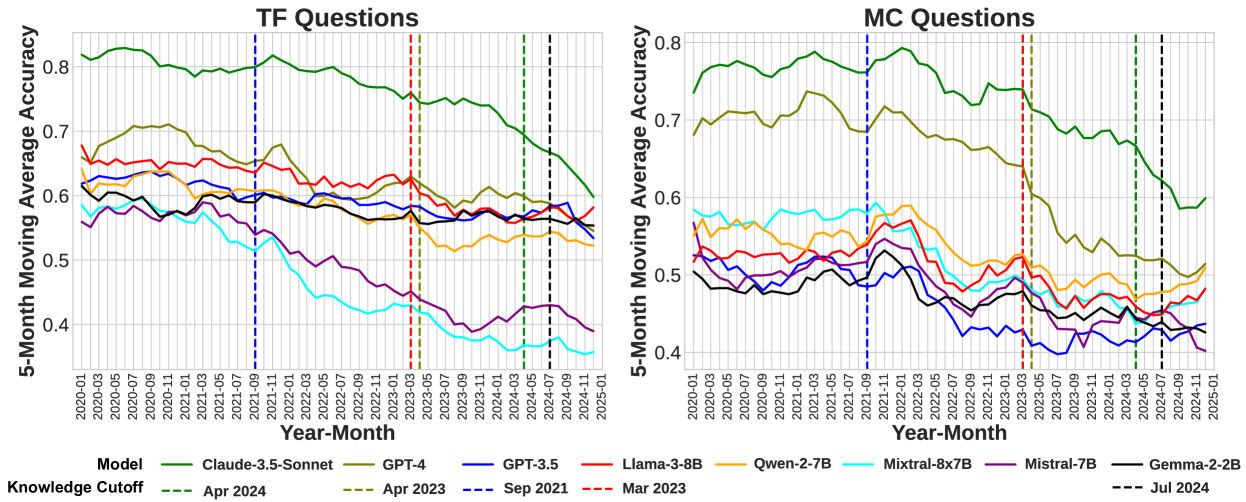
- 实验表明,LLM性能随预训练数据过时而下降,即使使用RAG也无法完全缓解。
📝 摘要(中文)
由于新模型和训练数据的不断涌现,现有的大语言模型(LLM)评估基准很快变得过时。这些基准也无法评估LLM性能随时间的变化,因为它们由一组没有时间维度的静态问题组成。为了解决这些局限性,我们提出使用未来事件预测作为一种持续评估方法,以评估LLM的时间泛化和预测能力。我们的基准Daily Oracle,自动从每日新闻中生成问答(QA)对,挑战LLM预测“未来”事件的结果。我们的研究结果表明,随着预训练数据变得过时,LLM的性能会随着时间的推移而下降。虽然检索增强生成(RAG)有可能提高预测准确性,但性能下降的模式仍然存在,突出了持续模型更新的必要性。代码和数据可在https://agenticlearning.ai/daily-oracle获得。
🔬 方法详解
问题定义:论文旨在解决现有LLM评估基准无法有效衡量模型随时间推移的性能变化的问题。现有基准通常是静态的,无法反映模型在面对不断变化的世界知识时的表现。这导致我们难以了解LLM的“保鲜期”以及何时需要更新模型。
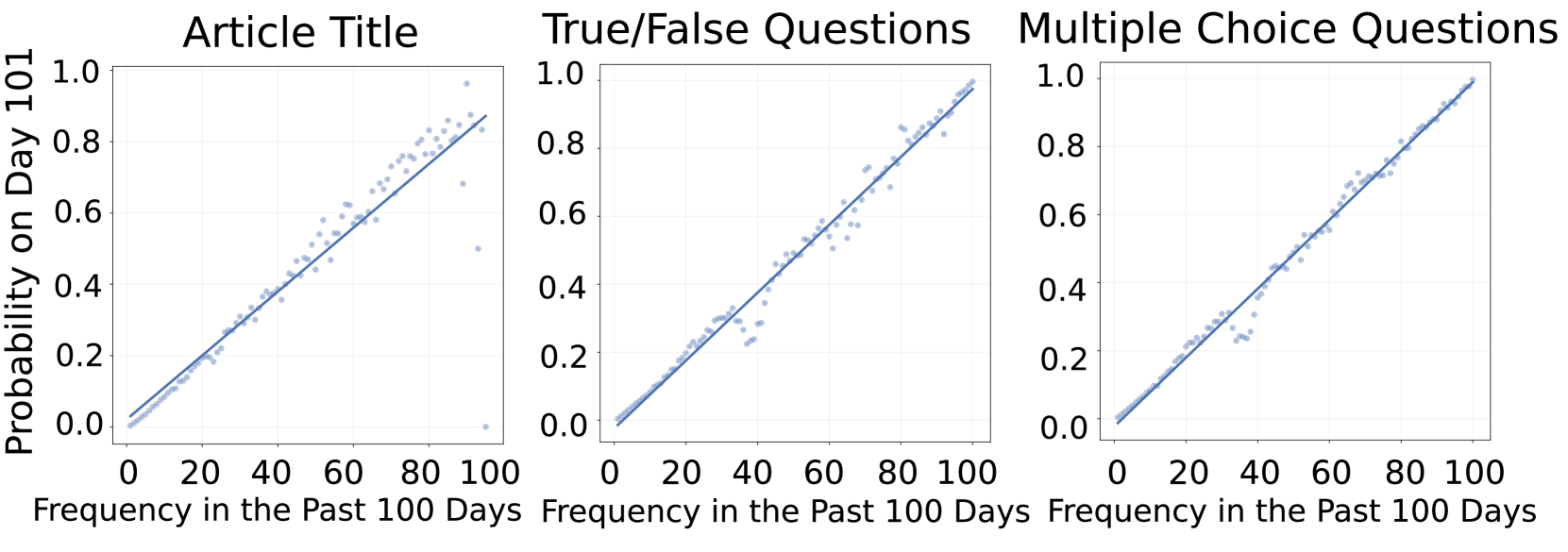
核心思路:论文的核心思路是利用每日新闻作为“预言机”,从中提取信息来构建问答对,其中问题基于过去的新闻,答案则基于未来的新闻。通过这种方式,可以持续评估LLM预测未来事件的能力,从而衡量其时间泛化能力。
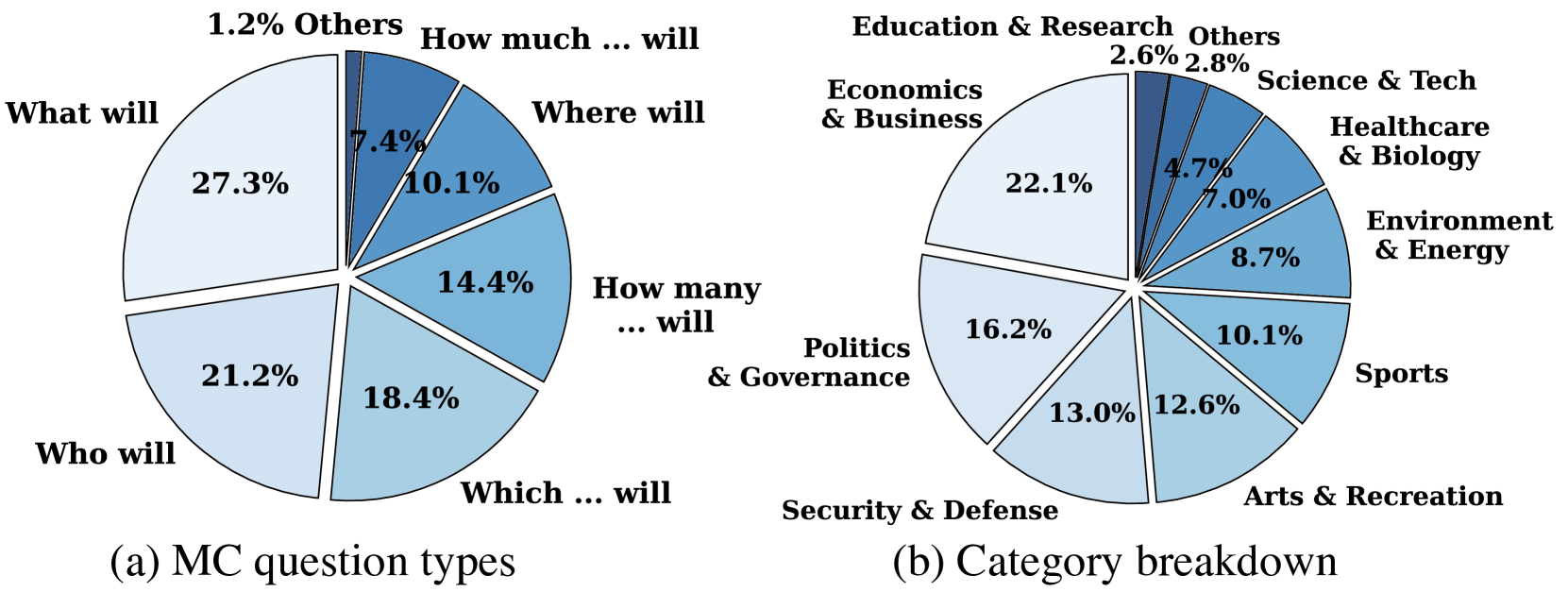
技术框架:Daily Oracle基准的整体流程如下:1) 收集每日新闻数据;2) 从新闻中提取事件信息;3) 基于提取的事件信息,生成问答对,其中问题涉及过去发生的事件,答案涉及未来发生的事件;4) 使用生成的问答对评估LLM的预测准确性;5) 随着时间的推移,持续评估LLM的性能变化。
关键创新:该论文的关键创新在于提出了一个动态的、基于每日新闻的LLM评估基准。与传统的静态基准相比,Daily Oracle能够更真实地反映LLM在实际应用中面临的挑战,并能够评估模型的时间泛化能力。此外,该基准可以自动生成问答对,从而实现持续评估。
关键设计:Daily Oracle的关键设计包括:1) 如何从新闻中有效提取事件信息;2) 如何生成高质量的问答对,确保问题和答案之间存在逻辑关系;3) 如何选择合适的评估指标来衡量LLM的预测准确性。论文可能使用了自然语言处理技术,如命名实体识别、关系抽取等,来提取事件信息。问答对的生成可能采用了模板或生成式方法。评估指标可能包括准确率、召回率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随着预训练数据变得过时,LLM的性能会随着时间的推移而下降。即使使用检索增强生成(RAG)技术,也只能部分缓解性能下降的问题,这表明持续的模型更新是必要的。具体的性能数据和对比基线在论文中给出,但摘要中未明确提及具体的性能提升幅度。
🎯 应用场景
该研究成果可应用于LLM的持续监控和评估,帮助开发者了解模型的性能衰减情况,并及时进行模型更新。此外,该方法还可以用于评估不同LLM的时间泛化能力,为模型选择提供参考。在金融预测、舆情分析等领域,对LLM的预测能力进行持续评估尤为重要。
📄 摘要(原文)
Many existing evaluation benchmarks for Large Language Models (LLMs) quickly become outdated due to the emergence of new models and training data. These benchmarks also fall short in assessing how LLM performance changes over time, as they consist of a static set of questions without a temporal dimension. To address these limitations, we propose using future event prediction as a continuous evaluation method to assess LLMs' temporal generalization and forecasting abilities. Our benchmark, Daily Oracle, automatically generates question-answer (QA) pairs from daily news, challenging LLMs to predict "future" event outcomes. Our findings reveal that as pre-training data becomes outdated, LLM performance degrades over time. While Retrieval Augmented Generation (RAG) has the potential to enhance prediction accuracy, the performance degradation pattern persists, highlighting the need for continuous model updates. Code and data are available at https://agenticlearning.ai/daily-oracle.