Knowledge Bases in Support of Large Language Models for Processing Web News
作者: Yihe Zhang, Nabin Pakka, Nian-Feng Tzeng
分类: cs.CL, cs.AI
发布日期: 2024-11-13 (更新: 2024-11-14)
备注: 10 pages, 5 figures
💡 一句话要点
提出一种基于知识库增强的大语言模型新闻处理框架,提升新闻分类效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识库 新闻处理 信息提取 图卷积
📋 核心要点
- 大语言模型虽然蕴含丰富知识,但缺乏常识推理,难以有效应用于下游任务。
- 该论文提出利用NewsIE提取新闻结构化信息,并结合BERTGraph进行图卷积,增强知识表示。
- 实验结果表明,该框架在新闻分类任务上取得了有希望的性能提升。
📝 摘要(中文)
大语言模型(LLMs)近年来在广泛应用中备受关注。通过海量数据集的预训练,LLM在其隐藏参数中隐式地记忆了训练数据集的事实知识。然而,由于缺乏常识推理,隐式地保存在参数中的知识往往使得下游应用程序难以有效利用。本文介绍了一种通用框架,该框架允许借助LLM构建知识库,专门用于处理Web新闻。该框架应用基于规则的新闻信息提取器(NewsIE)从新闻条目中提取关系元组,称为知识库,然后将其与LLM获得的新闻条目的隐式知识事实进行图卷积,用于新闻分类。它涉及两个轻量级组件:1) NewsIE:用于提取每个新闻条目的结构化信息,以关系元组的形式;2) BERTGraph:用于将隐式知识事实与NewsIE提取的关系元组进行图卷积。我们在不同的新闻相关数据集下评估了我们的框架用于新闻类别分类,并获得了有希望的实验结果。
🔬 方法详解
问题定义:现有的大语言模型虽然在预训练阶段学习了大量知识,但这些知识隐式地存储在模型参数中,缺乏结构化表示,难以进行常识推理,导致在新闻处理等下游任务中效果不佳。因此,如何有效地利用大语言模型中的知识,并结合外部知识库进行增强,是本文要解决的问题。
核心思路:本文的核心思路是将大语言模型学习到的隐式知识与从新闻文本中提取的结构化知识相结合。具体而言,首先利用NewsIE提取新闻中的关系元组,构建知识库;然后,利用BERTGraph将这些关系元组与大语言模型提取的隐式知识进行图卷积,从而增强知识表示,提升新闻分类效果。
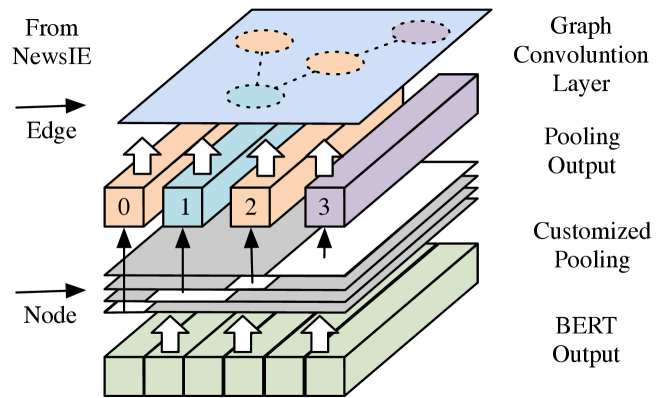
技术框架:该框架主要包含两个模块:NewsIE和BERTGraph。NewsIE负责从新闻文本中提取结构化信息,以关系元组的形式表示。BERTGraph负责将NewsIE提取的关系元组与大语言模型提取的隐式知识进行图卷积。整体流程是:首先使用NewsIE提取新闻文本的关系元组,构建知识库;然后,使用BERT对新闻文本进行编码,提取隐式知识;最后,使用BERTGraph将关系元组和隐式知识进行图卷积,得到增强的知识表示,用于新闻分类。
关键创新:该论文的关键创新在于将基于规则的信息提取器(NewsIE)与图卷积网络(BERTGraph)相结合,有效地利用了大语言模型中的隐式知识和新闻文本中的结构化知识。这种结合方式既能够利用大语言模型的强大表示能力,又能够引入外部知识库进行增强,从而提升新闻处理效果。
关键设计:NewsIE的设计依赖于预定义的规则,用于提取新闻文本中的实体和关系。BERTGraph采用图卷积网络结构,将关系元组作为图的节点,关系作为边,进行信息传播和聚合。损失函数采用交叉熵损失函数,用于优化新闻分类模型。具体的网络结构和参数设置在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文在不同的新闻相关数据集上进行了实验,结果表明该框架在新闻类别分类任务上取得了有希望的性能。具体的性能数据、对比基线和提升幅度在摘要中没有明确给出,属于未知信息。但整体而言,实验结果验证了该框架的有效性。
🎯 应用场景
该研究成果可应用于智能新闻推荐、舆情分析、虚假新闻检测等领域。通过结合大语言模型和知识库,可以更准确地理解新闻内容,提高相关应用的性能。未来,该方法还可以扩展到其他类型的文本数据处理任务中,例如金融报告分析、医学文献挖掘等。
📄 摘要(原文)
Large Language Models (LLMs) have received considerable interest in wide applications lately. During pre-training via massive datasets, such a model implicitly memorizes the factual knowledge of trained datasets in its hidden parameters. However, knowledge held implicitly in parameters often makes its use by downstream applications ineffective due to the lack of common-sense reasoning. In this article, we introduce a general framework that permits to build knowledge bases with an aid of LLMs, tailored for processing Web news. The framework applies a rule-based News Information Extractor (NewsIE) to news items for extracting their relational tuples, referred to as knowledge bases, which are then graph-convoluted with the implicit knowledge facts of news items obtained by LLMs, for their classification. It involves two lightweight components: 1) NewsIE: for extracting the structural information of every news item, in the form of relational tuples; 2) BERTGraph: for graph convoluting the implicit knowledge facts with relational tuples extracted by NewsIE. We have evaluated our framework under different news-related datasets for news category classification, with promising experimental results.