Problem-Oriented Segmentation and Retrieval: Case Study on Tutoring Conversations
作者: Rose E. Wang, Pawan Wirawarn, Kenny Lam, Omar Khattab, Dorottya Demszky
分类: cs.CL, cs.AI
发布日期: 2024-11-12
备注: EMNLP 2024 Findings. Our code and dataset are open-sourced at https://github.com/rosewang2008/posr
💡 一句话要点
提出问题导向的分割与检索(POSR)框架,应用于辅导对话结构化分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 问题导向分割 信息检索 联合建模 辅导对话 教育应用
📋 核心要点
- 现有方法难以有效结构化围绕预定义参考资料展开的开放式对话,如辅导课程。
- 提出问题导向的分割与检索(POSR)框架,联合完成对话分割和参考资料检索。
- 实验表明,联合建模的POSR方法显著优于独立流水线,并在教育应用中展现价值。
📝 摘要(中文)
本文提出了问题导向的分割与检索(POSR)任务,旨在将开放式对话(如辅导课程或商务会议)分解为多个片段,并将每个片段链接到相关的参考资料。以教育领域为例,将POSR应用于实际辅导课程,构建了LessonLink数据集,该数据集包含3500个片段,涵盖24300分钟的教学内容,并链接到116个SAT数学问题。论文评估了POSR的联合和独立方法,包括分割(如TextTiling)、检索(如ColBERT)和大型语言模型(LLM)方法。实验结果表明,将POSR建模为一个联合任务至关重要:POSR方法在联合指标上优于独立的分割和检索流水线高达+76%,在分割指标上优于传统分割方法高达+78%。最后,论文展示了POSR在下游教育应用中的实际影响,为真实课程结构中的语言和时间利用提供了新的见解。
🔬 方法详解
问题定义:论文旨在解决如何自动地将围绕特定参考材料(例如,工作表、会议议程)展开的开放式对话进行结构化分析的问题。现有方法通常将对话分割和信息检索作为独立任务处理,忽略了二者之间的内在联系,导致性能瓶颈。此外,缺乏针对此类对话场景的专用数据集,限制了相关研究的进展。
核心思路:论文的核心思路是将对话分割和参考资料检索建模为一个联合任务,即问题导向的分割与检索(POSR)。这种联合建模方式能够充分利用对话内容和参考资料之间的关联信息,从而提高分割和检索的准确性。论文认为,对话片段的划分应该以参考资料为导向,即每个片段都应该与特定的参考资料相关联。
技术框架:POSR的整体框架包括以下几个主要模块:1) 对话分割模块:将对话切分成多个片段;2) 参考资料检索模块:从参考资料库中检索与每个对话片段相关的参考资料;3) 联合优化模块:将分割和检索结果进行联合优化,以提高整体性能。论文尝试了多种实现方式,包括基于传统方法的TextTiling分割和ColBERT检索,以及基于大型语言模型(LLM)的方法。
关键创新:论文最重要的技术创新点在于将对话分割和参考资料检索建模为一个联合任务。与传统的独立流水线方法相比,POSR能够更好地利用对话内容和参考资料之间的关联信息,从而提高分割和检索的准确性。此外,LessonLink数据集的构建也为相关研究提供了宝贵的数据资源。
关键设计:论文中,联合优化模块的设计是关键。具体的技术细节包括:如何定义联合损失函数,以同时优化分割和检索结果;如何设计网络结构,以有效地融合对话内容和参考资料的信息;如何选择合适的超参数,以获得最佳的性能。论文尝试了不同的损失函数和网络结构,并通过实验验证了其有效性。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片


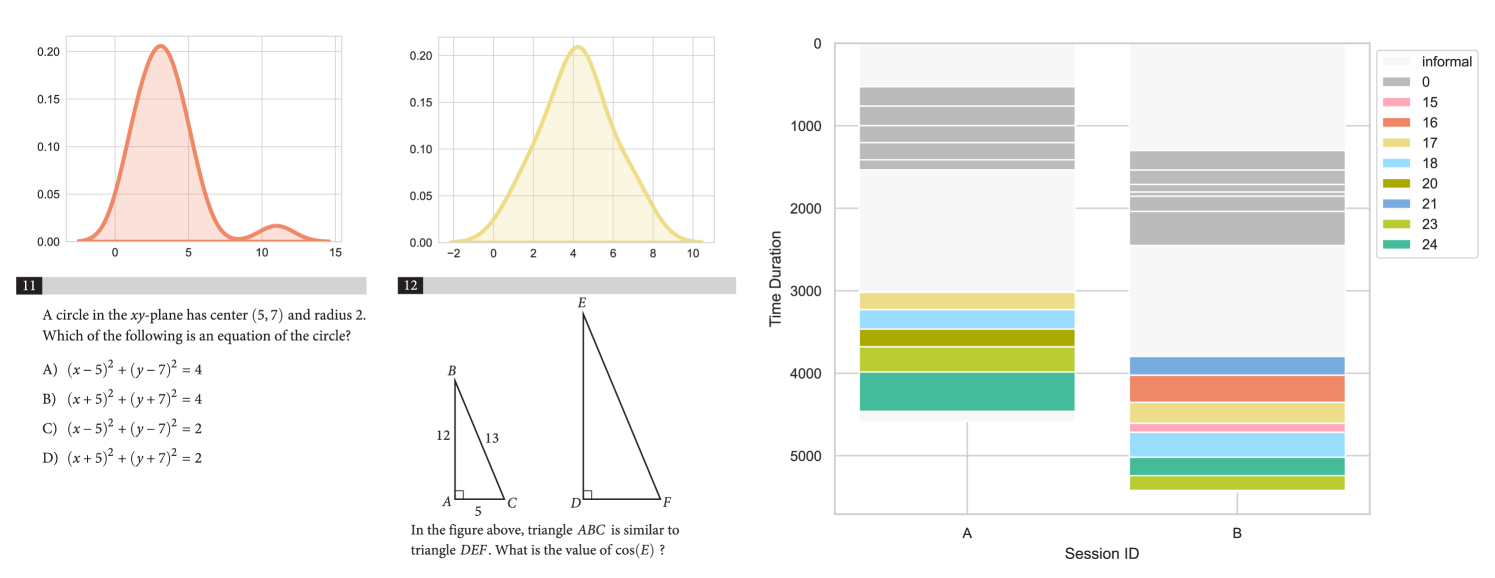
📊 实验亮点
实验结果表明,联合建模的POSR方法在LessonLink数据集上取得了显著的性能提升。在联合指标上,POSR方法优于独立的分割和检索流水线高达+76%。在分割指标上,POSR方法优于传统的分割方法高达+78%。这些结果充分证明了POSR框架的有效性。
🎯 应用场景
POSR框架可应用于多种场景,如在线教育、客户服务、会议记录等。在在线教育中,POSR可用于自动分析辅导课程,提取关键知识点,并为学生提供个性化学习建议。在客户服务中,POSR可用于快速定位客户问题,并提供相应的解决方案。在会议记录中,POSR可用于自动生成会议摘要,并链接到相关的议题和决策。
📄 摘要(原文)
Many open-ended conversations (e.g., tutoring lessons or business meetings) revolve around pre-defined reference materials, like worksheets or meeting bullets. To provide a framework for studying such conversation structure, we introduce Problem-Oriented Segmentation & Retrieval (POSR), the task of jointly breaking down conversations into segments and linking each segment to the relevant reference item. As a case study, we apply POSR to education where effectively structuring lessons around problems is critical yet difficult. We present LessonLink, the first dataset of real-world tutoring lessons, featuring 3,500 segments, spanning 24,300 minutes of instruction and linked to 116 SAT math problems. We define and evaluate several joint and independent approaches for POSR, including segmentation (e.g., TextTiling), retrieval (e.g., ColBERT), and large language models (LLMs) methods. Our results highlight that modeling POSR as one joint task is essential: POSR methods outperform independent segmentation and retrieval pipelines by up to +76% on joint metrics and surpass traditional segmentation methods by up to +78% on segmentation metrics. We demonstrate POSR's practical impact on downstream education applications, deriving new insights on the language and time use in real-world lesson structures.