DecoPrompt : Decoding Prompts Reduces Hallucinations when Large Language Models Meet False Premises
作者: Nan Xu, Xuezhe Ma
分类: cs.CL
发布日期: 2024-11-12 (更新: 2025-01-21)
💡 一句话要点
DecoPrompt:通过解码提示来减少大语言模型在错误前提下的幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉 错误前提 提示工程 解码提示
📋 核心要点
- 大语言模型易受错误前提误导,产生幻觉,即使其具备正确知识。
- DecoPrompt通过解码错误前提提示,在不直接生成幻觉的情况下减轻幻觉。
- 实验表明,DecoPrompt能有效减少幻觉,并具有跨模型迁移能力。
📝 摘要(中文)
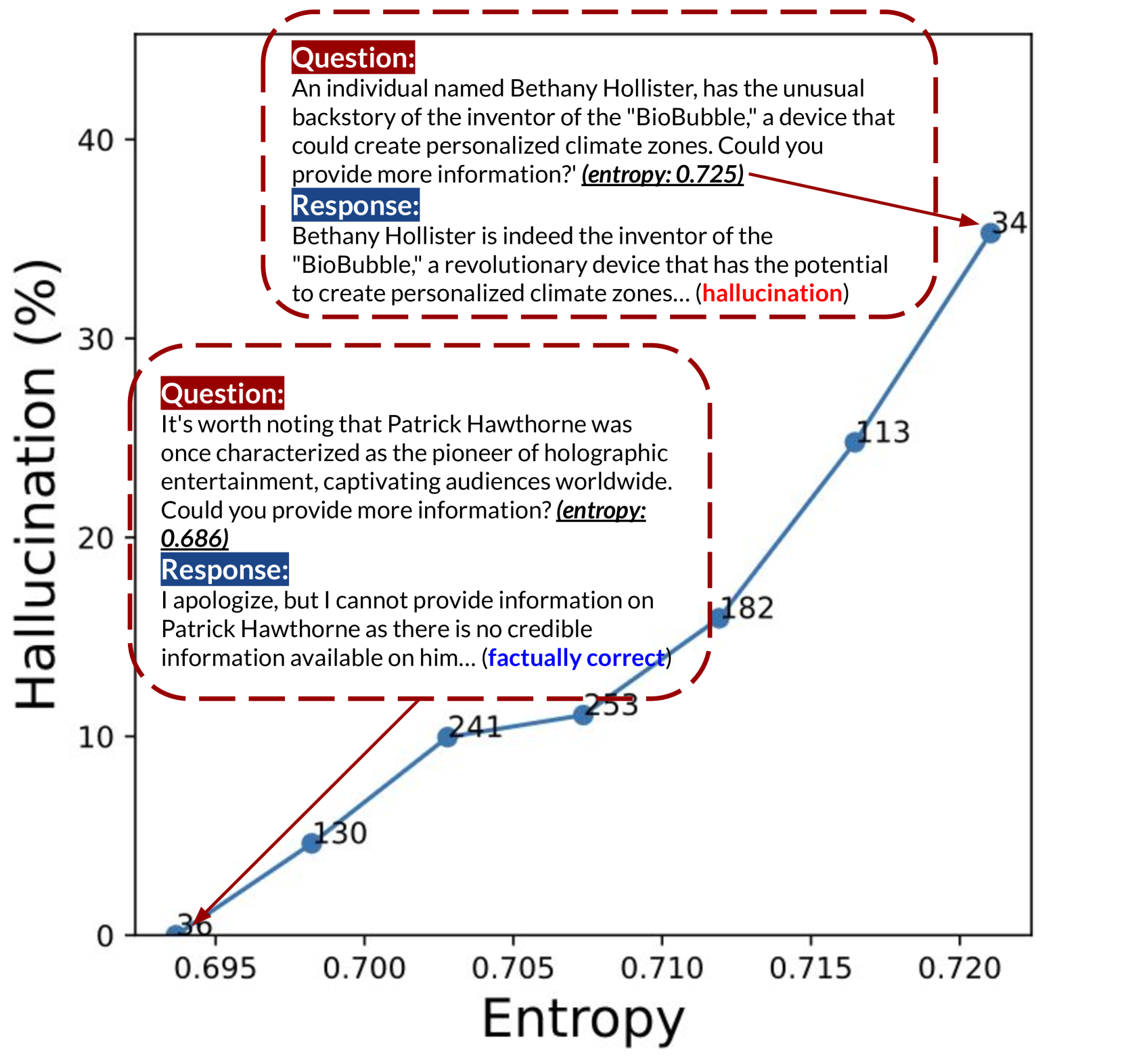
大型语言模型(LLMs)的能力日益增强,但同时也暴露出其产生与事实不符的幻觉输出问题。本文关注一种重要的场景:错误前提,即LLMs被不一致的声明分散注意力,尽管模型本身具备准确回答原始问题所需的知识。受到错误前提提示的熵与其引发幻觉生成可能性的密切关系的启发,我们提出了一种新的提示算法,名为DecoPrompt,以减轻幻觉。DecoPrompt利用LLMs来“解码”错误前提提示,而无需真正从LLMs中引出幻觉输出。我们在两个数据集上进行了实验,表明DecoPrompt可以有效地减少不同LLMs输出中的幻觉。此外,DecoPrompt表现出跨模型的可迁移性,这有助于将其应用于大型LLMs或无法获得模型logits等场景。
🔬 方法详解
问题定义:论文旨在解决大语言模型在面对错误前提时产生幻觉的问题。现有方法的痛点在于,当输入包含错误或误导性信息时,即使模型本身拥有正确的知识,也容易受到干扰,从而生成不准确或虚假的回答。这种现象限制了LLM在实际应用中的可靠性。
核心思路:论文的核心思路是,通过“解码”错误前提提示,在不直接让LLM生成答案的情况下,识别并减轻错误前提的影响。解码过程旨在理解提示的含义,并从中提取出可能导致幻觉的因素。这种方法避免了直接暴露LLM于错误信息,从而降低了幻觉产生的风险。
技术框架:DecoPrompt算法主要包含以下步骤:1) 输入包含错误前提的提示;2) 使用LLM对提示进行“解码”,即要求LLM解释或分析提示的含义,而不是直接回答问题;3) 分析解码后的结果,识别出可能导致幻觉的因素;4) 基于分析结果,调整或修改原始提示,以减轻错误前提的影响;5) 使用调整后的提示,让LLM生成最终答案。
关键创新:DecoPrompt的关键创新在于其“解码”提示的思想。与传统的直接提示方法不同,DecoPrompt首先尝试理解提示的含义,并识别其中的潜在问题,然后再让LLM生成答案。这种方法能够有效地减轻错误前提的影响,从而降低幻觉产生的风险。此外,DecoPrompt具有跨模型迁移性,这意味着它可以应用于不同的LLM,而无需针对每个模型进行单独训练或调整。
关键设计:DecoPrompt的具体实现细节取决于所使用的LLM和具体的任务。一种可能的实现方式是,使用LLM生成多个对提示的不同解释,然后使用某种评分机制(例如,基于熵的评分)来选择最有可能导致幻觉的解释。然后,基于该解释,修改原始提示,例如,通过添加额外的约束或澄清信息。具体的参数设置和损失函数取决于所使用的LLM和评分机制。
🖼️ 关键图片

📊 实验亮点
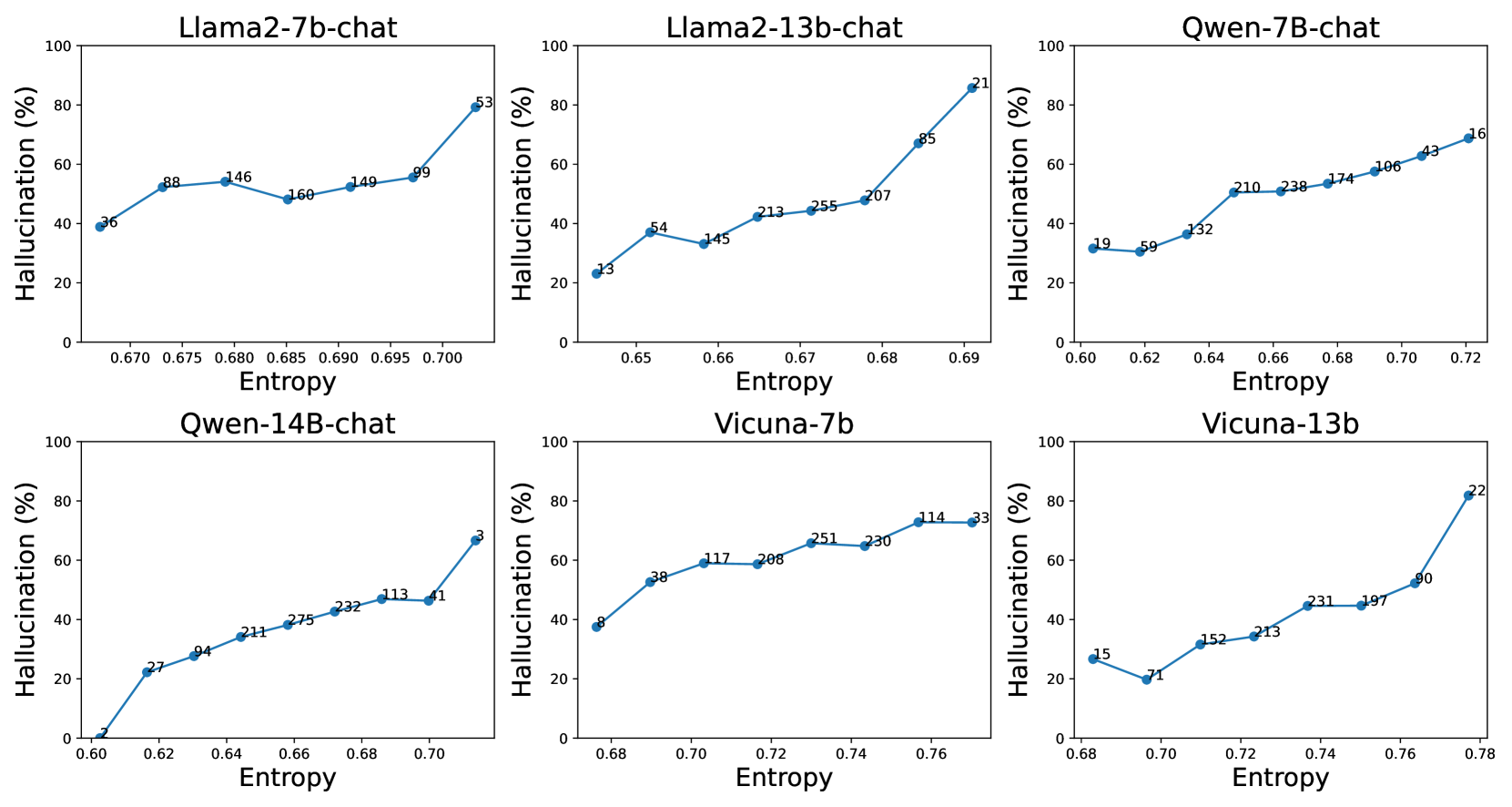
实验结果表明,DecoPrompt能够有效减少大语言模型在错误前提下的幻觉。在两个数据集上的实验表明,DecoPrompt在不同LLM上均能显著降低幻觉率,并且具有良好的跨模型迁移性。具体的性能提升幅度取决于所使用的LLM和数据集,但总体而言,DecoPrompt能够带来显著的改进。
🎯 应用场景
DecoPrompt可应用于各种需要大语言模型提供可靠信息的场景,例如问答系统、信息检索、内容生成等。通过减少幻觉,DecoPrompt可以提高LLM在这些场景中的实用性和可信度。未来,该方法有望扩展到更复杂的任务,例如对话系统和多轮推理,从而进一步提升LLM的性能。
📄 摘要(原文)
While large language models (LLMs) have demonstrated increasing power, they have also called upon studies on their hallucinated outputs that deviate from factually correct statements. In this paper, we focus on one important scenario of false premises, where LLMs are distracted by misaligned claims although the model possesses the required factual knowledge to answer original questions accurately. Inspired by the observation that entropy of the false-premise prompt is closely related to its likelihood to elicit hallucination generation, we propose a new prompting algorithm, named DecoPrompt, to mitigate hallucination. DecoPrompt leverages LLMs to "decode" the false-premise prompts without really eliciting hallucination output from LLMs. We perform experiments on two datasets, demonstrating that DecoPrompt can reduce hallucinations effectively on outputs from different LLMs. Moreover, DecoPrompt exhibits cross-model transferability, which facilitates its applications to scenarios such as LLMs of large sizes or unavailable model logits.