Richer Output for Richer Countries: Uncovering Geographical Disparities in Generated Stories and Travel Recommendations
作者: Kirti Bhagat, Kinshuk Vasisht, Danish Pruthi
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2024-11-11 (更新: 2025-02-18)
备注: Findings of NAACL (2025)
💡 一句话要点
揭示地理偏见:大型语言模型在故事生成和旅行推荐中对不同富裕程度国家存在差异性表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 地理偏见 语言模型 旅行推荐 故事生成 公平性 地理知识 情感分析
📋 核心要点
- 现有研究较少关注大型语言模型中存在的地理偏见,这可能导致模型在不同地区的表现差异。
- 该研究通过分析旅行推荐和故事生成两个任务,揭示了语言模型对不同富裕程度国家的差异化对待。
- 实验结果表明,语言模型在为较贫穷国家生成内容时,独特性和情感表达方面存在明显不足。
📝 摘要(中文)
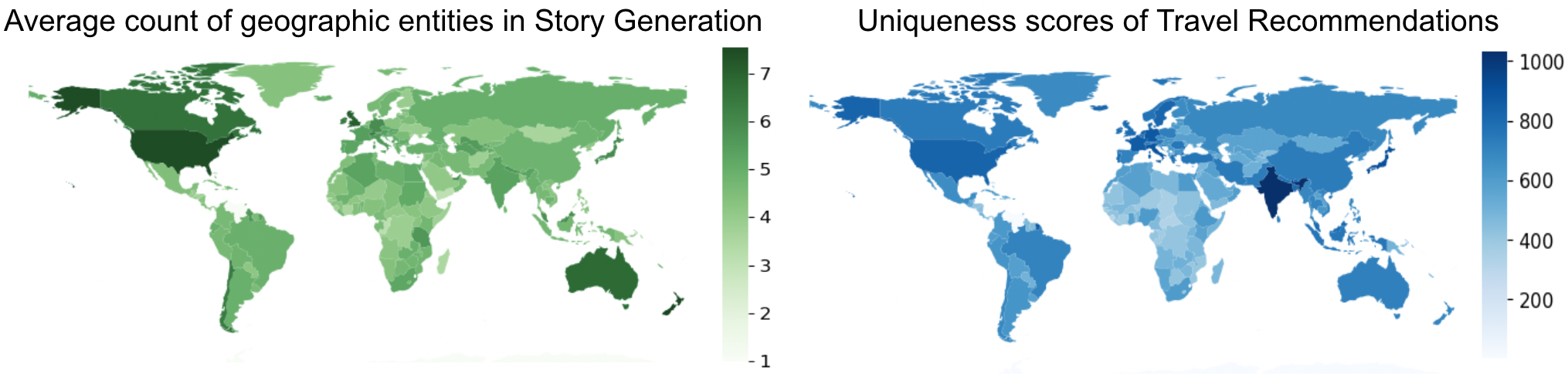
大量研究检验了语言模型在性别、种族、职业和宗教方面的偏见,但地理偏见相对较少被探索。一些研究评估了大型语言模型编码地理知识的程度。然而,编码的地理知识(或缺乏)对实际应用的影响尚未被记录。本文研究了大型语言模型在两个需要地理知识的常见场景中的表现:(a) 旅行推荐和 (b) 地理锚定的故事生成。具体来说,我们研究了五个流行的语言模型,通过大约 10 万个旅行请求和 20 万个故事生成,我们观察到,与较富裕国家相比,对应于较贫穷国家的旅行推荐更缺乏独特性,位置参考较少,并且来自这些地区的故事更常传达困苦和悲伤的情绪。
🔬 方法详解
问题定义:论文旨在研究大型语言模型在处理与地理位置相关任务时,是否存在对不同富裕程度国家存在偏见的问题。现有方法缺乏对地理偏见的系统性评估,可能导致模型在实际应用中对某些地区的用户产生不公平或不准确的结果。
核心思路:论文的核心思路是通过分析语言模型在旅行推荐和故事生成这两个任务中的输出,来评估其对不同国家或地区的理解和表达能力。通过比较模型在处理来自不同富裕程度国家的数据时所产生的差异,从而揭示潜在的地理偏见。
技术框架:该研究的技术框架主要包括以下几个步骤:1. 选择五个流行的语言模型作为研究对象。2. 构建包含大量旅行请求和故事生成任务的数据集,并根据地理位置进行分类。3. 使用选定的语言模型生成相应的旅行推荐和故事内容。4. 对生成的文本进行分析,包括位置参考的数量、情感表达的倾向性以及内容的独特性等方面。5. 比较不同富裕程度国家对应的内容差异,从而评估地理偏见的存在程度。
关键创新:该研究的关键创新在于首次系统性地评估了大型语言模型在地理知识应用中存在的偏见问题。通过量化模型在旅行推荐和故事生成任务中的表现差异,揭示了模型对不同地区的刻板印象和不公平对待。
关键设计:在实验设计方面,论文选择了旅行推荐和故事生成这两个具有代表性的任务,并构建了包含大量真实数据的测试集。在文本分析方面,论文采用了多种指标来评估生成内容的质量,包括位置参考的数量、情感极性以及文本的独特性。此外,论文还对不同语言模型的表现进行了比较,从而评估了不同模型对地理偏见的敏感程度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与较富裕国家相比,大型语言模型为较贫穷国家生成的旅行推荐更缺乏独特性,位置参考较少。此外,来自这些地区的故事更常传达困苦和悲伤的情绪。这些发现揭示了大型语言模型在地理知识应用中存在的偏见问题。
🎯 应用场景
该研究成果可应用于改进大型语言模型的公平性和公正性,减少其在地理信息相关的应用中产生的偏见。例如,可以用于优化旅行推荐系统,使其为所有国家和地区的用户提供更具个性化和准确性的建议。此外,还可以用于改善故事生成模型,使其能够更真实地反映不同地区的文化和社会背景。
📄 摘要(原文)
While a large body of work inspects language models for biases concerning gender, race, occupation and religion, biases of geographical nature are relatively less explored. Some recent studies benchmark the degree to which large language models encode geospatial knowledge. However, the impact of the encoded geographical knowledge (or lack thereof) on real-world applications has not been documented. In this work, we examine large language models for two common scenarios that require geographical knowledge: (a) travel recommendations and (b) geo-anchored story generation. Specifically, we study five popular language models, and across about $100$K travel requests, and $200$K story generations, we observe that travel recommendations corresponding to poorer countries are less unique with fewer location references, and stories from these regions more often convey emotions of hardship and sadness compared to those from wealthier nations.