LIFBench: Evaluating the Instruction Following Performance and Stability of Large Language Models in Long-Context Scenarios
作者: Xiaodong Wu, Minhao Wang, Yichen Liu, Xiaoming Shi, He Yan, Xiangju Lu, Junmin Zhu, Wei Zhang
分类: cs.CL
发布日期: 2024-11-11 (更新: 2025-07-23)
备注: 17 pages, 3 figures
💡 一句话要点
LIFBench:评估大语言模型在长文本场景下的指令跟随性能与稳定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 长文本 指令跟随 稳定性 基准测试
📋 核心要点
- 现有基准测试缺乏对LLM在长文本场景下指令跟随能力和稳定性的有效评估。
- LIFBench通过自动扩展方法生成多样化的长文本指令,并提出LIFEval进行自动化评估。
- 实验结果表明,LIFBench和LIFEval能够有效评估LLM在长文本环境下的性能,为未来发展提供指导。
📝 摘要(中文)
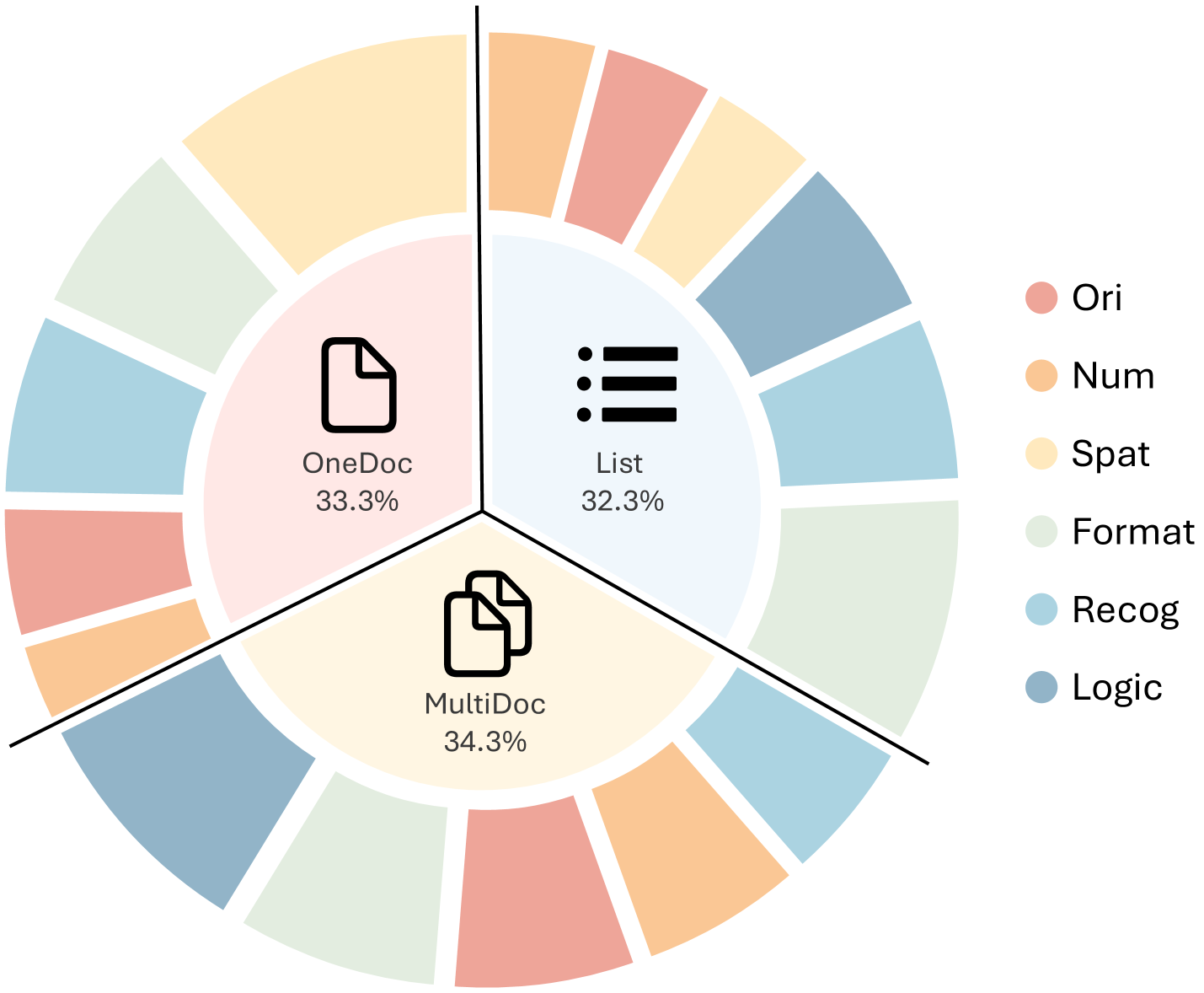
随着大语言模型(LLMs)在自然语言处理(NLP)领域的不断发展,其在长文本输入中稳定地遵循指令的能力对于实际应用至关重要。然而,现有的基准测试很少关注长文本场景下的指令跟随或不同输入上的稳定性。为了弥补这一差距,我们推出了LIFBench,这是一个可扩展的数据集,旨在评估LLMs在长文本中的指令跟随能力和稳定性。LIFBench包含三个长文本场景和十一个不同的任务,具有2,766条指令,这些指令通过一种自动扩展方法在长度、表达方式和变量三个维度上生成。在评估方面,我们提出了LIFEval,这是一种基于规则的评估方法,能够对复杂的LLM响应进行精确的自动评分,而无需依赖LLM辅助评估或人工判断。这种方法可以从多个角度全面分析模型的性能和稳定性。我们对六个长度区间内的20个著名LLM进行了详细的实验。我们的工作贡献了LIFBench和LIFEval作为评估LLM在复杂和长文本设置中性能的强大工具,为指导LLM开发的未来发展提供了宝贵的见解。
🔬 方法详解
问题定义:现有的大语言模型在处理长文本时,指令跟随能力会下降,并且在不同输入下的稳定性不足。现有的评测基准缺乏对长文本场景下指令跟随能力和稳定性的有效评估,难以准确衡量模型在实际应用中的表现。
核心思路:LIFBench的核心思路是构建一个可扩展的长文本指令数据集,并设计一种自动化的评估方法。通过自动化的方式生成多样化的指令,覆盖长度、表达方式和变量等多个维度,从而全面评估模型在长文本环境下的性能。LIFEval则通过规则化的方式,避免了对LLM辅助评估或人工判断的依赖,提高了评估的效率和客观性。
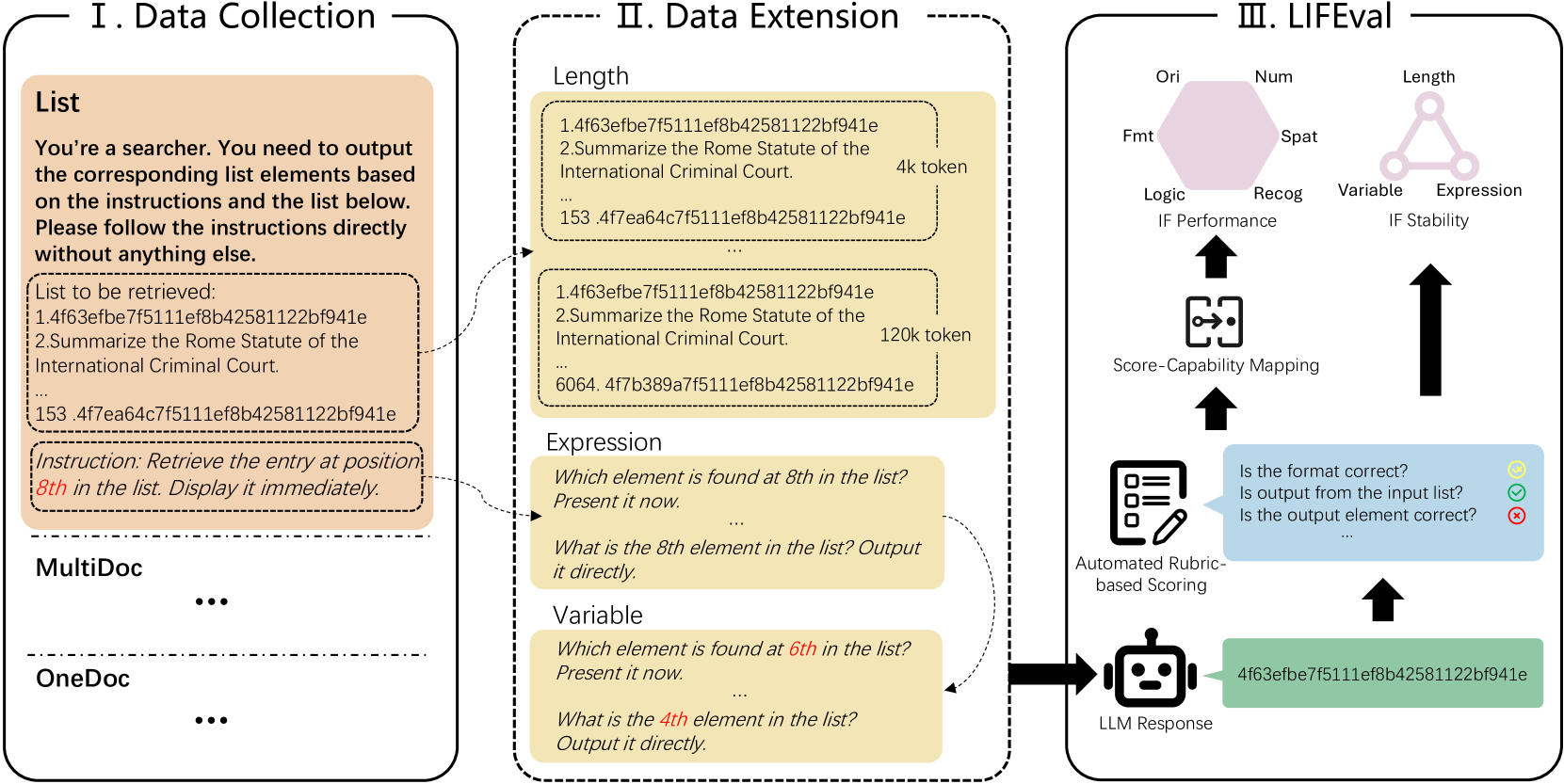
技术框架:LIFBench包含三个长文本场景和十一个不同的任务。数据集的构建过程包括:1) 定义任务和场景;2) 使用自动扩展方法生成指令,该方法在长度、表达方式和变量三个维度上扩展初始指令;3) 使用LIFEval进行评估。LIFEval是一种基于规则的评估方法,它定义了一系列规则来判断LLM的响应是否符合指令的要求。
关键创新:LIFBench的关键创新在于:1) 提出了一个可扩展的长文本指令数据集,能够全面评估LLM在长文本环境下的指令跟随能力和稳定性;2) 设计了一种自动化的评估方法LIFEval,避免了对LLM辅助评估或人工判断的依赖,提高了评估的效率和客观性。与现有方法相比,LIFBench更关注长文本场景,并提供了一种更高效、更客观的评估方式。
关键设计:LIFBench的指令生成过程采用了自动扩展方法,通过控制长度、改变表达方式和引入变量来生成多样化的指令。LIFEval的评估规则是根据任务的特点和指令的要求进行设计的,例如,对于摘要任务,评估规则会关注摘要的长度、信息覆盖度和流畅性。具体的参数设置和网络结构取决于被评估的LLM。
🖼️ 关键图片
📊 实验亮点
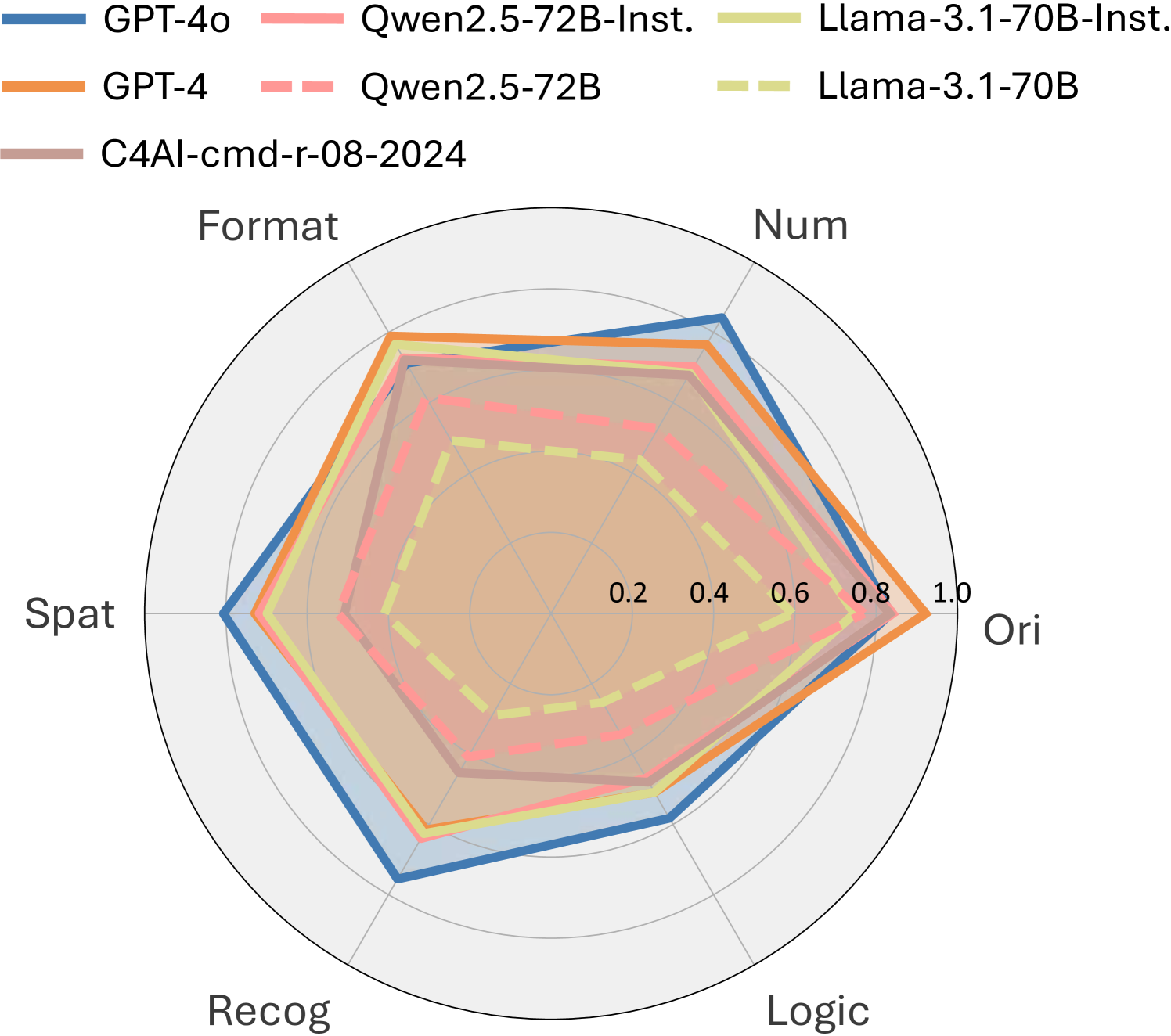
LIFBench对20个主流LLM在六个长度区间进行了详细的实验。实验结果表明,不同LLM在长文本环境下的性能差异显著,并且随着文本长度的增加,模型的性能会下降。LIFBench和LIFEval能够有效地评估LLM在长文本环境下的指令跟随能力和稳定性,为未来的研究提供了有价值的参考。
🎯 应用场景
LIFBench可用于评估和改进大语言模型在需要处理长文本的各种应用场景中的性能,例如:长篇文档摘要、代码生成、知识库问答、对话系统等。该基准测试能够帮助研究人员和开发者更好地了解LLM在长文本环境下的能力,并指导模型的优化和改进,从而提升LLM在实际应用中的效果。
📄 摘要(原文)
As Large Language Models (LLMs) evolve in natural language processing (NLP), their ability to stably follow instructions in long-context inputs has become critical for real-world applications. However, existing benchmarks seldom focus on instruction-following in long-context scenarios or stability on different inputs. To bridge this gap, we introduce LIFBench, a scalable dataset designed to evaluate LLMs' instruction-following capabilities and stability across long contexts. LIFBench comprises three long-context scenarios and eleven diverse tasks, featuring 2,766 instructions generated through an automated expansion method across three dimensions: length, expression, and variables. For evaluation, we propose LIFEval, a rubric-based assessment method that enables precise, automated scoring of complex LLM responses without reliance on LLM-assisted assessments or human judgment. This method allows for a comprehensive analysis of model performance and stability from multiple perspectives. We conduct detailed experiments on 20 prominent LLMs across six length intervals. Our work contributes LIFBench and LIFEval as robust tools for assessing LLM performance in complex and long-context settings, offering valuable insights to guide future advancements in LLM development.