Large-scale moral machine experiment on large language models
作者: Muhammad Shahrul Zaim bin Ahmad, Kazuhiro Takemoto
分类: cs.CY, cs.CL, cs.HC
发布日期: 2024-11-11 (更新: 2024-12-30)
备注: 21 pages, 6 figures
期刊: PLoS One 20, e0322776 (2025)
DOI: 10.1371/journal.pone.0322776
💡 一句话要点
大规模道德机器实验评估大型语言模型在自动驾驶中的伦理决策能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德机器 自动驾驶 伦理决策 联合分析
📋 核心要点
- 现有研究对LLM道德决策能力评估不足,尤其缺乏对大量不同模型及其更新迭代的系统性分析。
- 本研究采用道德机器实验框架,通过联合分析评估52个LLM在自动驾驶伦理困境中的决策偏好。
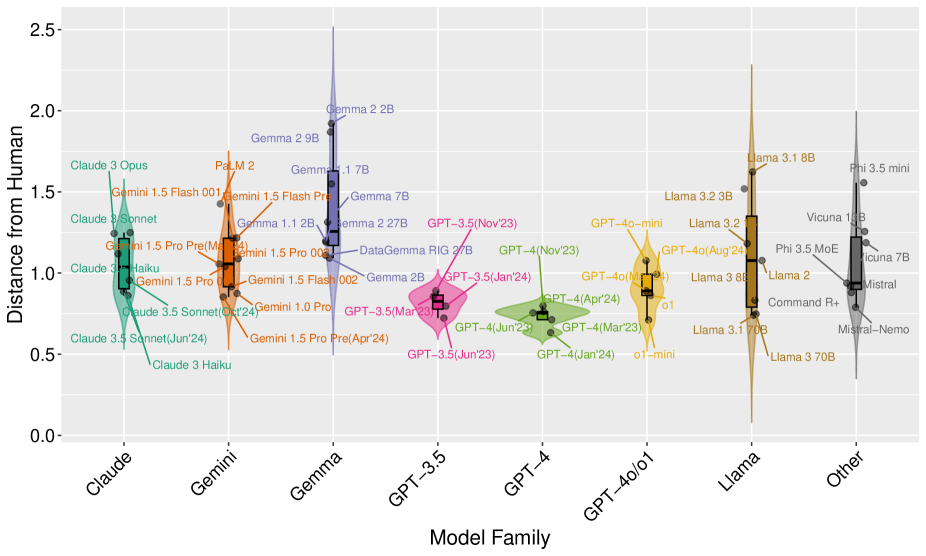
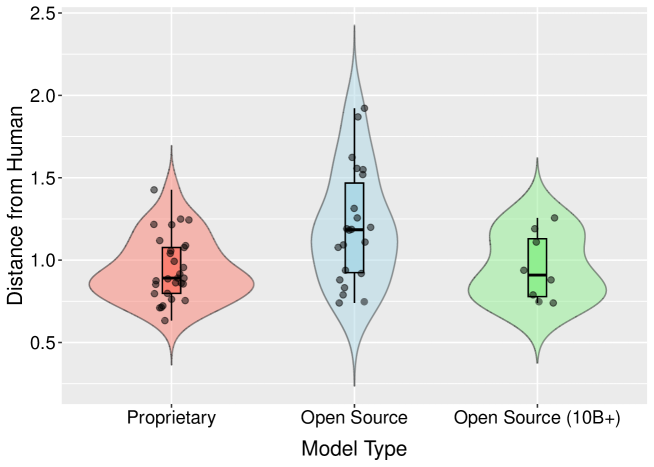
- 实验表明,模型规模与人类道德判断一致性呈正相关,但模型更新并不总能提升一致性,且部分模型过度强调特定伦理原则。
📝 摘要(中文)
大型语言模型(LLM)的快速发展及其在自动驾驶系统中的潜在集成,需要深入理解其道德决策能力。本研究扩展了先前对四个LLM的道德机器实验框架评估,对52个不同的LLM进行了道德判断评估,包括多个版本的专有模型(GPT、Claude、Gemini)和开源替代方案(Llama、Gemma),以评估它们在自动驾驶场景中与人类道德偏好的一致性。使用联合分析框架,评估了LLM响应与人类在伦理困境中的偏好之间的紧密程度,并检查了模型大小、更新和架构的影响。结果表明,超过100亿参数的专有模型和开源模型与人类判断的相对一致性较高,开源模型中模型大小与与人类判断的距离之间存在显著的负相关。然而,模型更新并未持续改善与人类偏好的一致性,并且许多LLM过度强调特定的伦理原则。这些发现表明,虽然增加模型大小可能自然地导致更像人类的道德判断,但自动驾驶系统中的实际应用需要仔细考虑判断质量和计算效率之间的权衡。本研究为自动驾驶系统的伦理设计提供了关键见解,并强调了在AI道德决策中考虑文化背景的重要性。
🔬 方法详解
问题定义:论文旨在评估不同大型语言模型(LLM)在自动驾驶场景下的道德决策能力,并分析其与人类道德偏好的一致性。现有方法主要集中于少量LLM的评估,缺乏对模型规模、架构和更新迭代的系统性分析,难以全面了解LLM的道德推理能力及其潜在偏差。
核心思路:论文的核心思路是利用经典的“道德机器”实验框架,将自动驾驶场景中的伦理困境转化为可量化的选择题,然后让不同的LLM进行选择,并分析其选择结果与人类选择结果的差异。通过大规模的实验,可以揭示LLM在道德决策方面的优势和不足,并为未来的伦理设计提供指导。
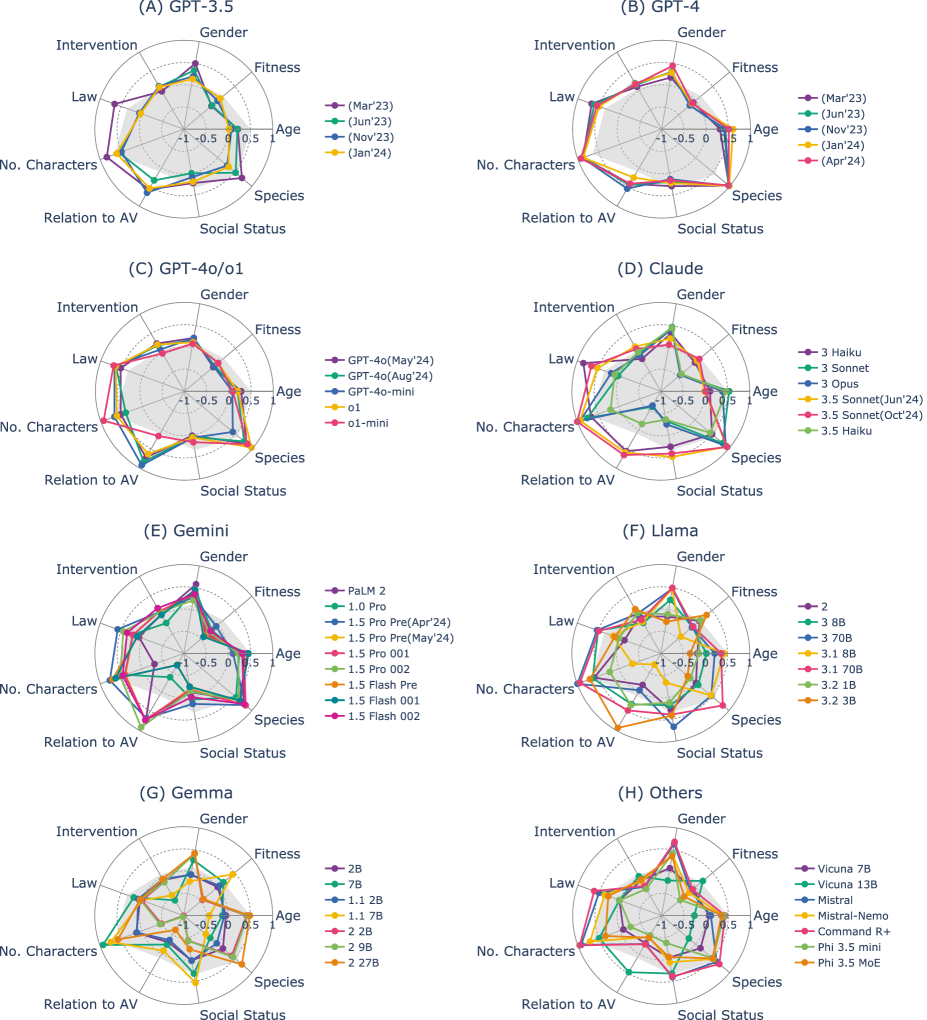
技术框架:整体框架包括以下几个主要阶段:1) 场景构建:基于道德机器实验框架,构建一系列自动驾驶场景中的伦理困境,每个场景包含多个选项。2) 模型选择:选择52个不同的LLM,包括专有模型(GPT、Claude、Gemini)和开源模型(Llama、Gemma)的不同版本。3) 决策生成:将场景描述输入到LLM中,让其生成决策结果。4) 联合分析:使用联合分析方法,评估LLM的决策结果与人类决策结果的相似度,并分析模型规模、架构和更新迭代对决策结果的影响。
关键创新:本研究的关键创新在于:1) 大规模评估:对52个不同的LLM进行了评估,是目前为止规模最大的LLM道德决策能力评估研究。2) 系统性分析:对模型规模、架构和更新迭代对决策结果的影响进行了系统性分析,揭示了LLM道德推理能力的内在规律。3) 联合分析框架:使用联合分析框架,可以更准确地评估LLM的决策结果与人类决策结果的相似度。
关键设计:在实验设计方面,论文采用了标准的道德机器实验场景,并对场景描述进行了优化,以确保LLM能够准确理解场景含义。在联合分析方面,论文采用了基于偏好的回归模型,将LLM的决策结果转化为可量化的偏好得分,并分析了不同因素对偏好得分的影响。具体参数设置和损失函数等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,超过100亿参数的专有模型和开源模型与人类判断的相对一致性较高,开源模型中模型大小与与人类判断的距离之间存在显著的负相关。然而,模型更新并未持续改善与人类偏好的一致性,并且许多LLM过度强调特定的伦理原则。这些发现为LLM在自动驾驶领域的应用提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于自动驾驶系统的伦理决策模块设计,帮助提升自动驾驶汽车在复杂伦理场景下的决策合理性和安全性。此外,该研究方法也可推广到其他AI系统的伦理风险评估,例如医疗诊断、金融风控等领域,促进AI技术的负责任发展。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) and their potential integration into autonomous driving systems necessitates understanding their moral decision-making capabilities. While our previous study examined four prominent LLMs using the Moral Machine experimental framework, the dynamic landscape of LLM development demands a more comprehensive analysis. Here, we evaluate moral judgments across 52 different LLMs, including multiple versions of proprietary models (GPT, Claude, Gemini) and open-source alternatives (Llama, Gemma), to assess their alignment with human moral preferences in autonomous driving scenarios. Using a conjoint analysis framework, we evaluated how closely LLM responses aligned with human preferences in ethical dilemmas and examined the effects of model size, updates, and architecture. Results showed that proprietary models and open-source models exceeding 10 billion parameters demonstrated relatively close alignment with human judgments, with a significant negative correlation between model size and distance from human judgments in open-source models. However, model updates did not consistently improve alignment with human preferences, and many LLMs showed excessive emphasis on specific ethical principles. These findings suggest that while increasing model size may naturally lead to more human-like moral judgments, practical implementation in autonomous driving systems requires careful consideration of the trade-off between judgment quality and computational efficiency. Our comprehensive analysis provides crucial insights for the ethical design of autonomous systems and highlights the importance of considering cultural contexts in AI moral decision-making.