PDC & DM-SFT: A Road for LLM SQL Bug-Fix Enhancing
作者: Yiwen Duan, Yonghong Yu, Xiaoming Zhao, Yichang Wu, Wenbo Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-11
备注: COLING-Industry 2025 accepted
💡 一句话要点
提出PDC & DM-SFT方法,提升LLM在SQL代码缺陷修复任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 SQL缺陷修复 渐进式数据集构建 动态掩码微调 代码生成 监督学习 数据增强 代码修复
📋 核心要点
- 现有代码大语言模型在代码生成方面表现良好,但在SQL代码缺陷修复能力上存在不足。
- 论文提出渐进式数据集构建(PDC)和动态掩码监督微调(DM-SFT)方法,提升模型SQL缺陷修复能力。
- 实验结果表明,使用PDC和DM-SFT训练的模型性能超越了当前最佳的大规模模型。
📝 摘要(中文)
代码大语言模型(Code LLMs),如Code Llama和DeepSeek-Coder,在代码生成任务中表现出色。然而,现有模型大多侧重于生成正确代码的能力,但在缺陷修复方面表现不佳。本文提出了一套增强LLM的SQL缺陷修复能力的方法,主要包括两个部分:从零开始的渐进式数据集构建(PDC)和动态掩码监督微调(DM-SFT)。PDC分别从广度和深度两个角度提出了数据扩展方法。DM-SFT引入了一种高效的缺陷修复监督学习方法,有效减少了总训练步数,并减轻了SQL代码缺陷修复训练中的“迷失方向”问题。评估结果表明,使用这两种方法训练的代码LLM模型超越了当前所有性能最佳且规模更大的模型。
🔬 方法详解
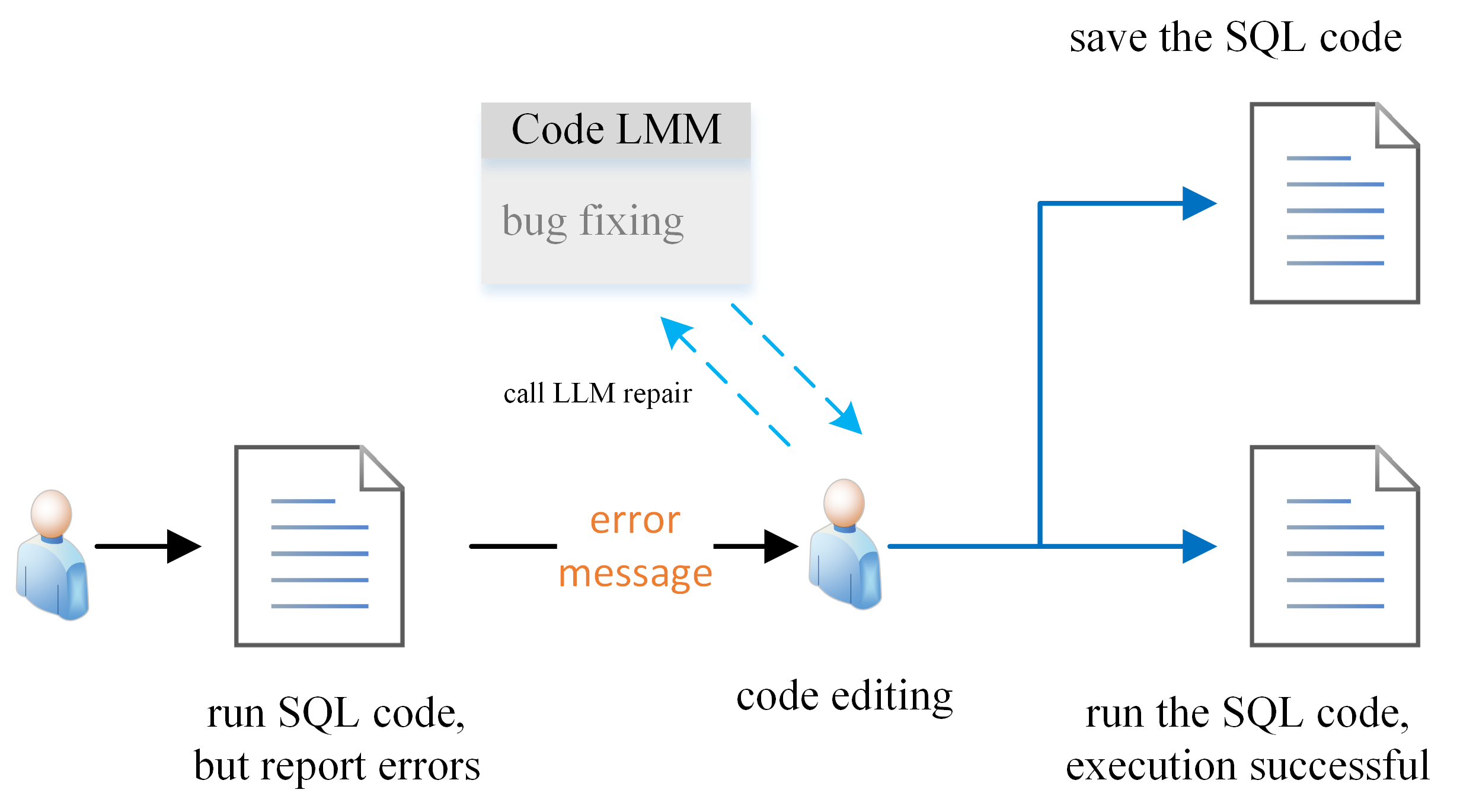
问题定义:现有代码大语言模型在代码生成任务中表现出色,但对于SQL代码的缺陷修复能力不足。现有的模型往往专注于生成正确的代码,而忽略了对错误代码的理解和修复能力。这导致模型在实际应用中,难以应对复杂的SQL缺陷修复场景。
核心思路:论文的核心思路是通过构建高质量的SQL缺陷修复数据集,并设计高效的训练方法,来提升LLM在SQL缺陷修复任务上的性能。PDC方法旨在构建更全面、更具挑战性的数据集,DM-SFT方法旨在更有效地利用这些数据进行训练。
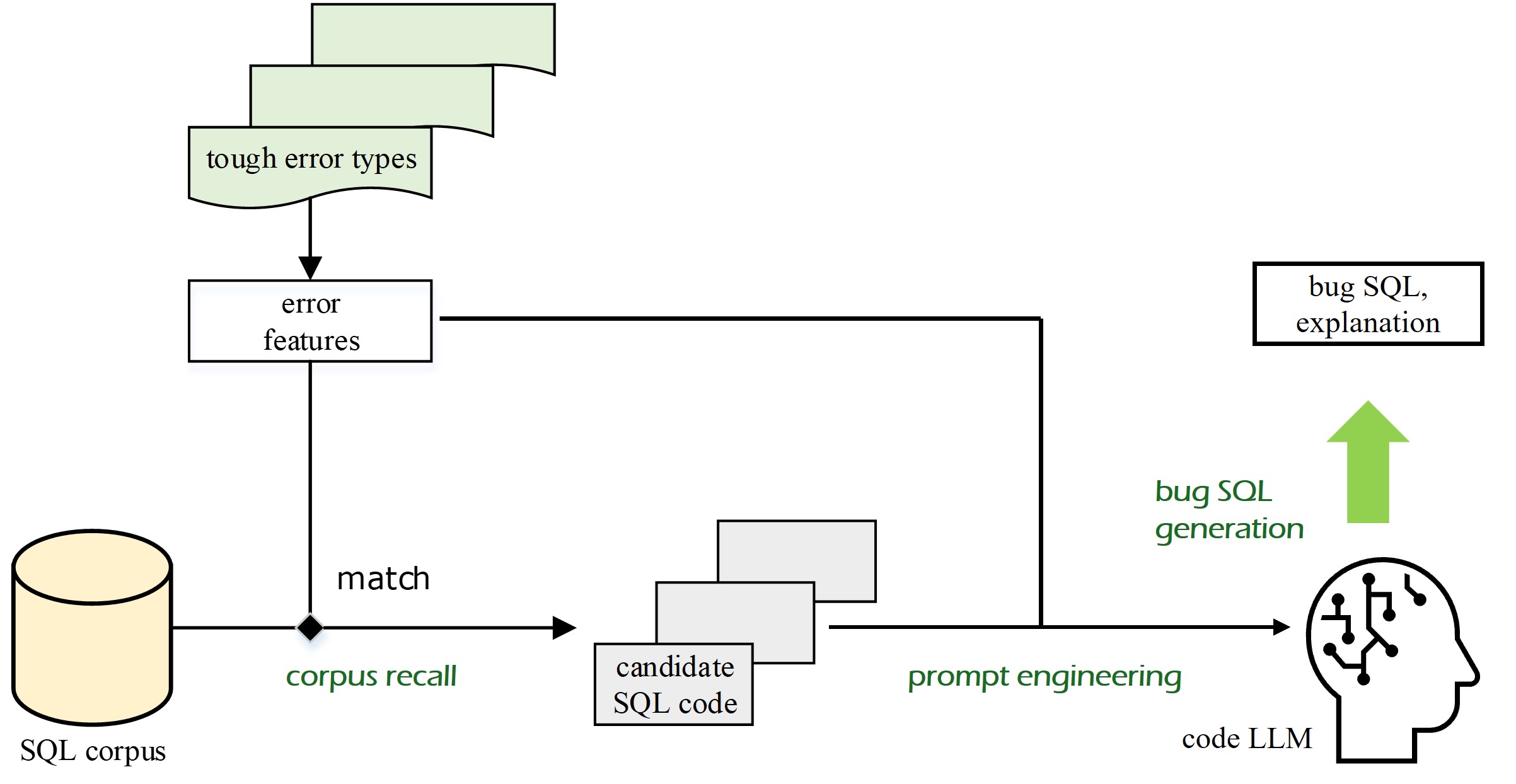
技术框架:整体框架包含两个主要阶段:1) 渐进式数据集构建(PDC):从零开始构建SQL缺陷修复数据集,包括广度优先和深度优先两种数据扩展方法。广度优先侧重于增加不同类型的错误样本,深度优先侧重于增加同一错误样本的复杂程度。2) 动态掩码监督微调(DM-SFT):使用构建的数据集对LLM进行微调,采用动态掩码策略,使模型更关注错误部分,从而提高修复效率。
关键创新:论文的关键创新在于PDC和DM-SFT的结合。PDC通过系统性的数据构建方法,解决了现有数据集不足的问题。DM-SFT通过动态掩码策略,提高了训练效率,并减轻了SQL代码缺陷修复训练中的“迷失方向”问题。与传统的监督微调方法相比,DM-SFT能够更有效地利用数据,并更快地收敛。
关键设计:PDC中,广度优先的数据扩展方法包括引入不同类型的SQL错误,如语法错误、逻辑错误、类型错误等。深度优先的数据扩展方法包括增加SQL语句的复杂度,如增加表的数量、增加JOIN操作的数量、增加子查询的嵌套层数等。DM-SFT中,动态掩码策略根据SQL语句的错误位置,动态地调整掩码的位置和大小。损失函数采用标准的交叉熵损失函数,优化器采用AdamW优化器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用PDC和DM-SFT训练的代码LLM模型在SQL缺陷修复任务上取得了显著的性能提升,超越了当前所有性能最佳且规模更大的模型。具体性能数据未知,但强调了超越现有最佳模型。
🎯 应用场景
该研究成果可应用于智能代码助手、数据库自动维护、软件测试等领域。通过提升LLM的SQL缺陷修复能力,可以减少人工调试成本,提高软件开发效率,并降低数据库维护风险。未来,该技术有望扩展到其他编程语言和代码修复场景。
📄 摘要(原文)
Code Large Language Models (Code LLMs), such as Code llama and DeepSeek-Coder, have demonstrated exceptional performance in the code generation tasks. However, most existing models focus on the abilities of generating correct code, but often struggle with bug repair. We introduce a suit of methods to enhance LLM's SQL bug-fixing abilities. The methods are mainly consisted of two parts: A Progressive Dataset Construction (PDC) from scratch and Dynamic Mask Supervised Fine-tuning (DM-SFT). PDC proposes two data expansion methods from the perspectives of breadth first and depth first respectively. DM-SFT introduces an efficient bug-fixing supervised learning approach, which effectively reduce the total training steps and mitigate the "disorientation" in SQL code bug-fixing training. In our evaluation, the code LLM models trained with two methods have exceeds all current best performing model which size is much larger.