Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
作者: Xiaojun Wu, Junxi Liu, Huanyi Su, Zhouchi Lin, Yiyan Qi, Chengjin Xu, Jiajun Su, Jiajie Zhong, Fuwei Wang, Saizhuo Wang, Fengrui Hua, Jia Li, Jian Guo
分类: cs.CL, cs.CE
发布日期: 2024-11-09 (更新: 2025-12-08)
备注: Published in Findings of EMNLP 2025
期刊: In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 22544-22560, Suzhou, China. Association for Computational Linguistics
DOI: 10.18653/v1/2025.findings-emnlp.1227
🔗 代码/项目: GITHUB
💡 一句话要点
提出Golden Touchstone金融大语言模型双语评测基准,解决现有评测标准不足问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融大语言模型 评测基准 双语评测 自然语言处理 金融NLP 模型评估 Touchstone-GPT
📋 核心要点
- 现有金融领域大语言模型评测基准存在语言覆盖窄、任务类型少、数据集质量不高等问题。
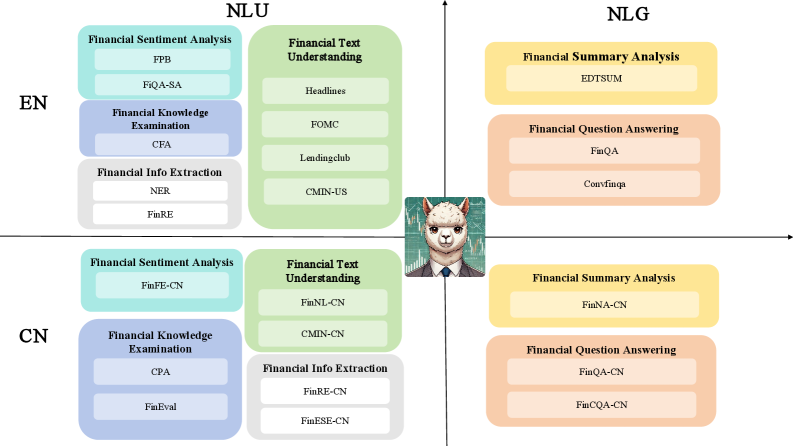
- 提出Golden Touchstone,构建包含中英文双语、覆盖八大金融NLP任务的综合性评测基准。
- 开源Touchstone-GPT,通过持续预训练和指令微调,在双语基准上展现出较强的性能。
📝 摘要(中文)
随着大型语言模型(LLMs)日益渗透金融领域,迫切需要一种标准化的方法来全面评估其性能。现有的金融基准测试通常存在语言和任务覆盖范围有限、数据集质量低以及对LLM评估的适应性不足等问题。为了解决这些局限性,我们推出了Golden Touchstone,这是一个全面的金融LLM双语基准,包含中文和英文的八个核心金融NLP任务。该基准基于广泛的开源数据收集和行业特定需求开发,全面评估模型的语言理解和生成能力。通过对GPT-4o、Llama3、FinGPT和FinMA等主要模型进行比较分析,我们揭示了它们在处理复杂金融信息方面的优势和局限性。此外,我们开源了Touchstone-GPT,这是一个通过持续预训练和指令微调训练的金融LLM,它在双语基准上表现出强大的性能,但在特定任务中仍然存在局限性。这项研究为金融LLM提供了一个实用的评估工具,并指导未来的开发和优化。Golden Touchstone的源代码和Touchstone-GPT的模型权重已在https://github.com/IDEA-FinAI/Golden-Touchstone上公开。
🔬 方法详解
问题定义:现有金融大语言模型评测基准存在以下痛点:一是语言覆盖范围有限,通常只关注英文;二是任务覆盖不全面,未能充分评估模型在各种金融场景下的能力;三是数据集质量参差不齐,影响评测结果的可靠性;四是对LLM的适应性不足,难以有效评估新型LLM的性能。
核心思路:论文的核心思路是构建一个全面、高质量、双语的金融大语言模型评测基准,以更准确地评估模型在金融领域的实际应用能力。通过覆盖更广泛的语言和任务,并采用高质量的数据集,可以更全面地了解模型的优势和不足,从而指导模型的进一步优化和改进。
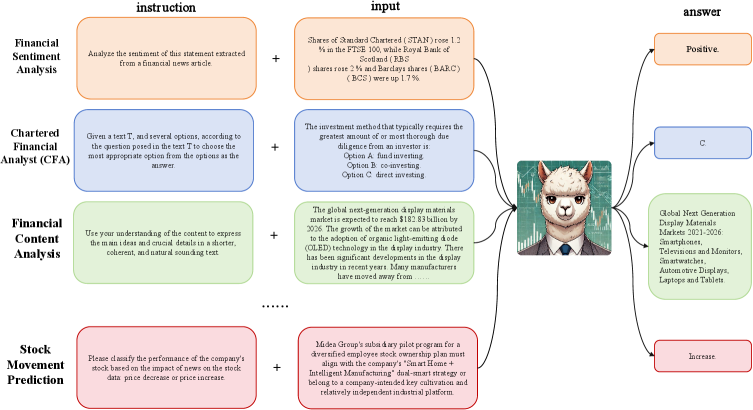
技术框架:Golden Touchstone基准包含以下主要模块:1) 数据收集与清洗:从开源数据和行业数据中收集金融文本数据,并进行清洗和预处理;2) 任务定义:定义八个核心金融NLP任务,包括信息抽取、情感分析、问答等;3) 数据集构建:为每个任务构建高质量的中文和英文数据集;4) 评测指标:选择合适的评测指标来评估模型的性能;5) 模型评测:使用Golden Touchstone基准对各种金融大语言模型进行评测,并分析结果。
关键创新:该论文的关键创新点在于构建了一个全面的双语金融大语言模型评测基准,弥补了现有评测标准的不足。与现有方法相比,Golden Touchstone具有以下优势:一是语言覆盖范围更广,同时支持中文和英文;二是任务覆盖更全面,涵盖了金融领域常见的八个NLP任务;三是数据集质量更高,经过严格的清洗和标注;四是对LLM的适应性更强,可以有效评估各种新型LLM的性能。
关键设计:在数据集构建方面,论文采用了多种数据增强技术,以提高数据集的多样性和泛化能力。在评测指标方面,论文选择了多种常用的NLP评测指标,如准确率、召回率、F1值等,并根据具体任务进行了调整。Touchstone-GPT模型通过持续预训练和指令微调进行训练,具体参数设置和损失函数等技术细节在论文中未详细说明。
🖼️ 关键图片
📊 实验亮点
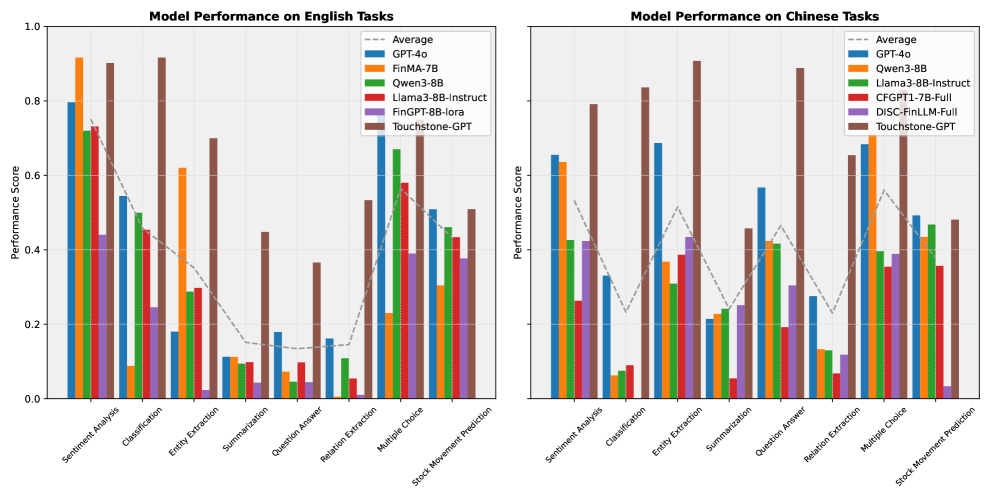
实验结果表明,GPT-4o、Llama3、FinGPT和FinMA等主要模型在Golden Touchstone基准上表现出不同的优势和局限性。Touchstone-GPT在双语基准上表现出强大的性能,但在特定任务中仍然存在局限性。具体性能数据和提升幅度在论文中未详细说明。
🎯 应用场景
该研究成果可应用于金融大语言模型的性能评估、模型优化和应用开发。金融机构和研究人员可以使用Golden Touchstone基准来评估不同模型的性能,选择最适合其需求的模型。模型开发者可以利用该基准来识别模型的不足之处,并进行针对性的优化。此外,该研究还可以促进金融NLP技术的进一步发展,推动金融领域的智能化转型。
📄 摘要(原文)
As large language models (LLMs) increasingly permeate the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. Existing financial benchmarks often suffer from limited language and task coverage, low-quality datasets, and inadequate adaptability for LLM evaluation. To address these limitations, we introduce Golden Touchstone, a comprehensive bilingual benchmark for financial LLMs, encompassing eight core financial NLP tasks in both Chinese and English. Developed from extensive open-source data collection and industry-specific demands, this benchmark thoroughly assesses models' language understanding and generation capabilities. Through comparative analysis of major models such as GPT-4o, Llama3, FinGPT, and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-source Touchstone-GPT, a financial LLM trained through continual pre-training and instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks. This research provides a practical evaluation tool for financial LLMs and guides future development and optimization. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at https://github.com/IDEA-FinAI/Golden-Touchstone.