FactLens: Benchmarking Fine-Grained Fact Verification
作者: Kushan Mitra, Dan Zhang, Sajjadur Rahman, Estevam Hruschka
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-08 (更新: 2025-05-30)
备注: 12 pages, updated version
💡 一句话要点
FactLens:提出细粒度事实核查基准,解决LLM幻觉问题中传统方法的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 细粒度验证 大型语言模型 幻觉问题 基准数据集 自动评估 子声明生成
📋 核心要点
- 现有事实核查方法依赖整体模型,难以发现复杂声明中的细微错误,缺乏透明度。
- FactLens通过将复杂声明分解为子声明,实现细粒度的事实核查,提升准确性和可解释性。
- FactLens提供基准数据集和自动评估器,实验结果表明评估器与人类判断具有较高的一致性。
📝 摘要(中文)
大型语言模型(LLM)在语言生成和理解方面表现出令人印象深刻的能力,但其产生幻觉和生成事实不正确信息的倾向仍然是一个关键限制。为了验证LLM生成的内容和其他来源的声明,传统的验证方法通常依赖于整体模型,这些模型为复杂声明分配单一的事实性标签,这可能会掩盖细微的错误。在本文中,我们提倡转向细粒度验证,将复杂声明分解为更小的子声明以进行单独验证,从而可以更精确地识别不准确之处,提高透明度并减少证据检索中的歧义。然而,生成子声明会带来挑战,例如保持上下文并确保与原始声明的语义等价性。我们引入了FactLens,这是一个用于评估细粒度事实验证的基准,具有子声明质量的指标和自动评估器。基准数据经过手动管理,以确保高质量的ground truth。我们的结果表明,自动FactLens评估器与人类判断之间存在一致性,并且我们讨论了子声明特征对整体验证性能的影响。
🔬 方法详解
问题定义:大型语言模型容易产生幻觉,生成不正确的事实信息。传统的事实核查方法通常采用整体模型,直接对复杂声明进行真假判断。这种方法无法识别声明中哪些部分是错误的,缺乏细粒度和可解释性。此外,证据检索也容易产生歧义。
核心思路:FactLens的核心思想是将复杂的声明分解为更小的、独立的子声明,然后对每个子声明进行单独的事实核查。通过这种细粒度的方式,可以更精确地定位错误,提高验证的准确性和透明度。同时,子声明的生成需要保证与原始声明的语义等价性,并保持上下文信息。
技术框架:FactLens主要包含以下几个部分:1) 数据集构建:手动构建包含复杂声明及其对应的子声明的数据集,并标注每个子声明的真假。2) 子声明生成:研究如何自动生成高质量的子声明,保证语义等价性和上下文一致性。3) 事实核查:对每个子声明进行事实核查,判断其真假。4) 评估指标:设计评估指标,用于评估子声明的质量和事实核查的性能。5) 自动评估器:开发自动评估器,用于评估子声明的质量,并与人工评估结果进行对比。
关键创新:FactLens的关键创新在于提出了细粒度的事实核查方法,将复杂声明分解为子声明进行验证。这与传统的整体验证方法形成了鲜明对比,能够更精确地定位错误,提高验证的准确性和可解释性。此外,FactLens还提供了用于评估子声明质量的指标和自动评估器。
关键设计:FactLens的关键设计包括:1) 子声明的生成策略,需要保证子声明与原始声明的语义等价性,并保持上下文信息。2) 评估子声明质量的指标,例如完整性、相关性和一致性。3) 自动评估器的设计,需要能够准确地评估子声明的质量,并与人工评估结果保持一致。具体的参数设置、损失函数、网络结构等技术细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片

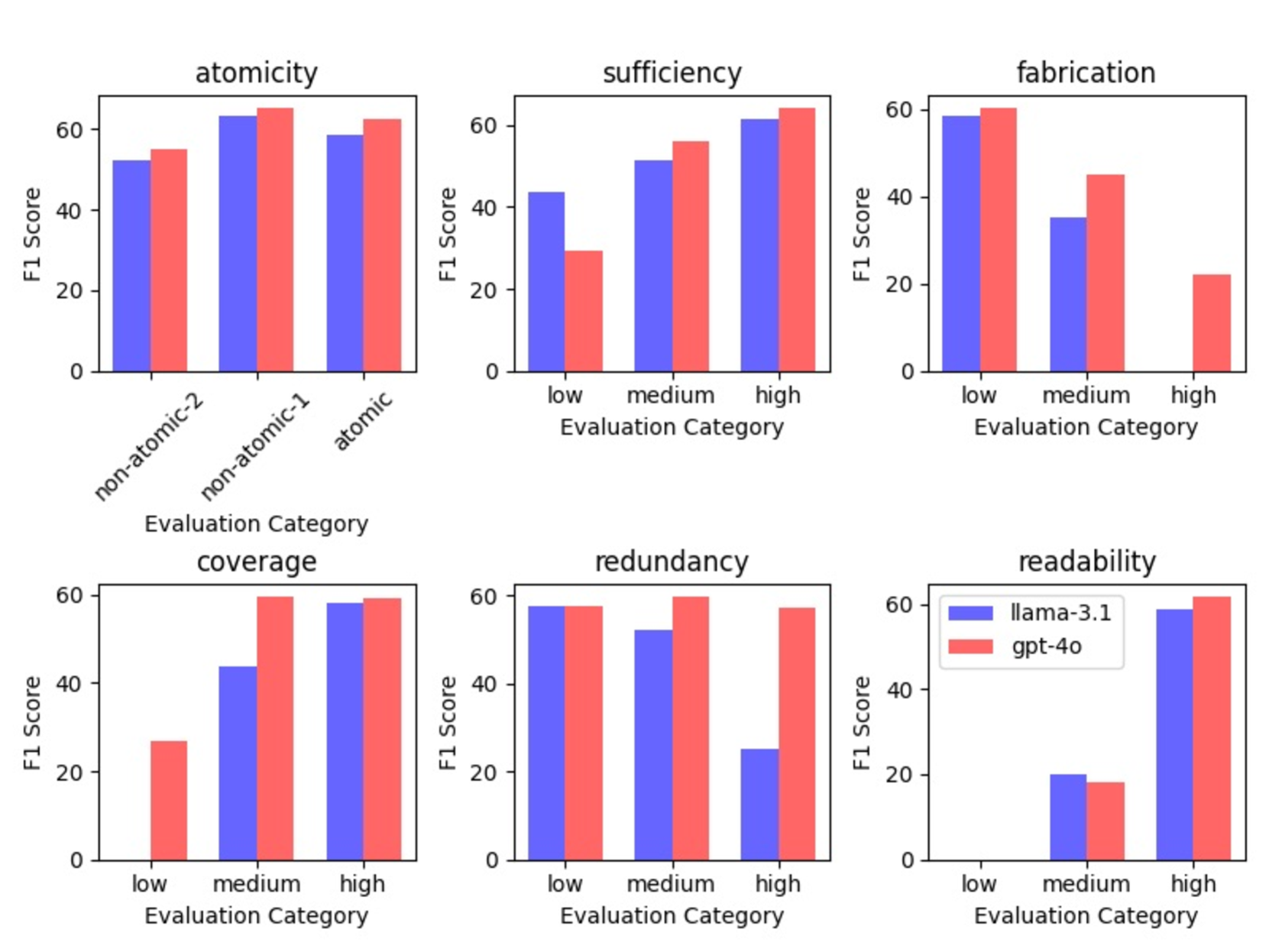

📊 实验亮点
FactLens的实验结果表明,自动评估器与人类判断之间存在较高的一致性,验证了FactLens评估框架的有效性。论文还分析了子声明的特征对整体验证性能的影响,为未来的研究提供了指导。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
FactLens可应用于多种场景,例如验证LLM生成内容的真实性,辅助新闻事实核查,提高信息检索的准确性,以及评估知识图谱的质量。该研究有助于提高人工智能系统的可靠性和可信度,减少虚假信息的传播,具有重要的社会价值和学术意义。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive capability in language generation and understanding, but their tendency to hallucinate and produce factually incorrect information remains a key limitation. To verify LLM-generated contents and claims from other sources, traditional verification approaches often rely on holistic models that assign a single factuality label to complex claims, potentially obscuring nuanced errors. In this paper, we advocate for a shift towards fine-grained verification, where complex claims are broken down into smaller sub-claims for individual verification, allowing for more precise identification of inaccuracies, improved transparency, and reduced ambiguity in evidence retrieval. However, generating sub-claims poses challenges, such as maintaining context and ensuring semantic equivalence with respect to the original claim. We introduce FactLens, a benchmark for evaluating fine-grained fact verification, with metrics and automated evaluators of sub-claim quality. The benchmark data is manually curated to ensure high-quality ground truth. Our results show alignment between automated FactLens evaluators and human judgments, and we discuss the impact of sub-claim characteristics on the overall verification performance.