One Small and One Large for Document-level Event Argument Extraction
作者: Jiaren Peng, Hongda Sun, Wenzhong Yang, Fuyuan Wei, Liang He, Liejun Wang
分类: cs.CL
发布日期: 2024-11-08
🔗 代码/项目: GITHUB
💡 一句话要点
针对文档级事件论元抽取,提出基于小型和大型语言模型的双重优化方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事件论元抽取 文档级处理 小型语言模型 大型语言模型 提示学习
📋 核心要点
- 文档级事件论元抽取面临长文本带来的事件边界模糊和冗余信息干扰两大挑战。
- 论文提出基于小型语言模型的CsEAE模型,利用协同感知和结构感知模块提升性能。
- 通过提示学习将抽取任务转化为生成任务,并结合CsEAE的洞见,提升大型语言模型的效果。
📝 摘要(中文)
本文针对文档级事件论元抽取(EAE)中因输入长度增加而面临的两大挑战:事件间语义边界难以区分和冗余信息干扰,提出了两种方法。首先,提出了基于小型语言模型(SLM)的协同和结构事件论元抽取模型(CsEAE)。CsEAE包含一个协同感知模块,通过上下文标记和协同事件提示抽取,整合当前输入中所有事件的信息。此外,CsEAE还包含一个结构感知模块,通过建立触发词所在句子与文档中其他句子之间的结构关系,减少冗余信息的干扰。其次,引入新的提示,将抽取任务转化为适合大型语言模型(LLM)的生成任务,弥补了在监督微调(SFT)条件下LLM在EAE性能上的差距。我们还对多个数据集进行了微调,开发了一个在大多数数据集上表现更好的LLM。最后,我们将CsEAE的见解应用于LLM,实现了性能的进一步提升。这表明在SLM上验证的可靠见解也适用于LLM。我们在Rams、WikiEvents和MLEE数据集上测试了我们的模型。与基线PAIE相比,CsEAE模型在Arg-C F1指标上分别提高了2.1%、2.3%和3.2%。
🔬 方法详解
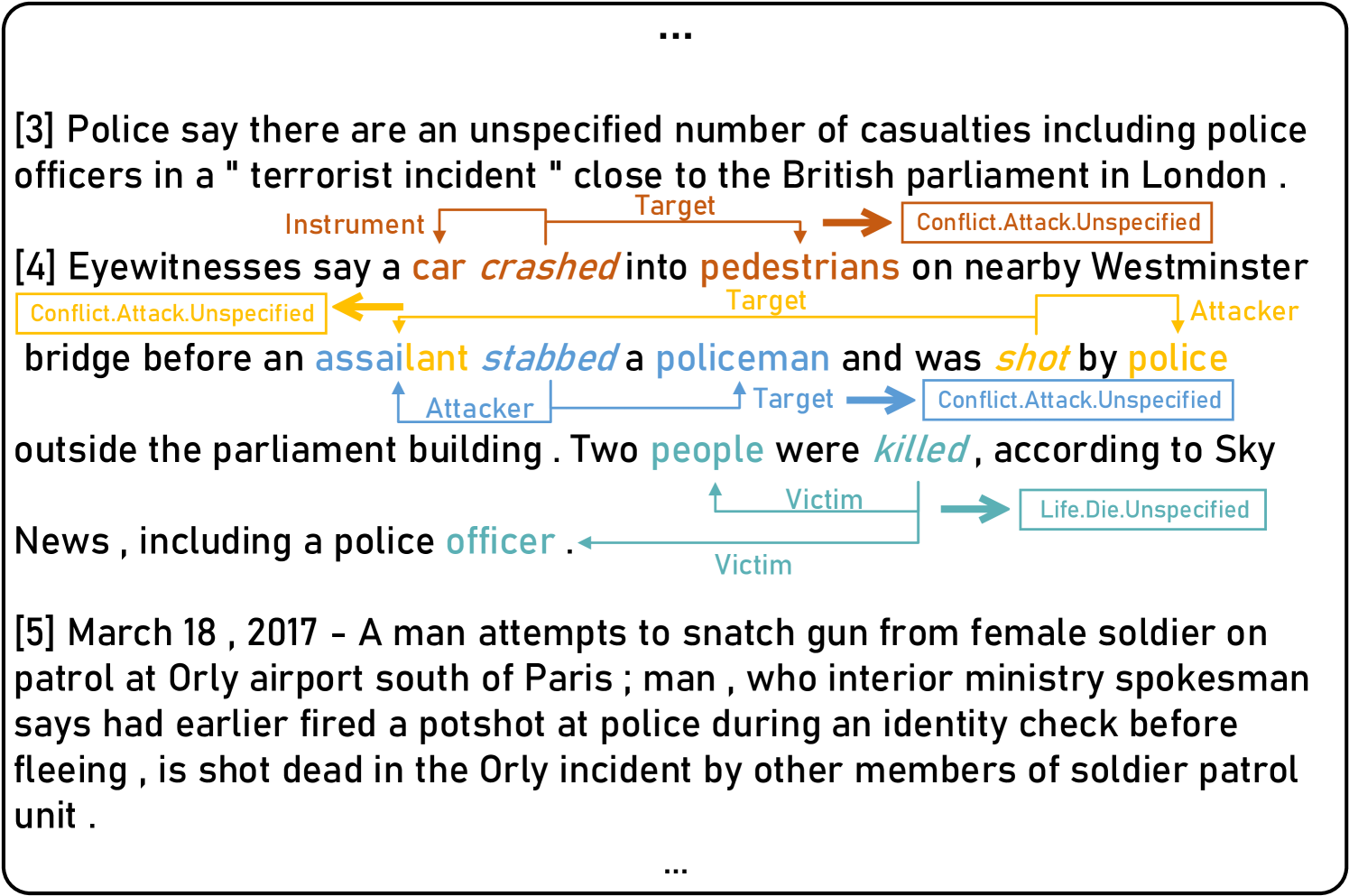
问题定义:文档级事件论元抽取任务旨在从长文档中识别事件的触发词和对应的论元,并确定它们之间的关系。现有方法在处理长文档时,面临两个主要痛点:一是难以区分不同事件之间的语义边界,导致论元抽取错误;二是文档中存在大量冗余信息,干扰模型对关键信息的提取。
核心思路:论文的核心思路是分别利用小型语言模型(SLM)和大型语言模型(LLM)的优势,并相互借鉴。对于SLM,通过协同感知和结构感知模块,增强模型对事件间关系和文档结构的理解,从而提高抽取精度。对于LLM,则通过提示学习,将其转化为更擅长的生成任务,并结合SLM的洞见进一步优化。
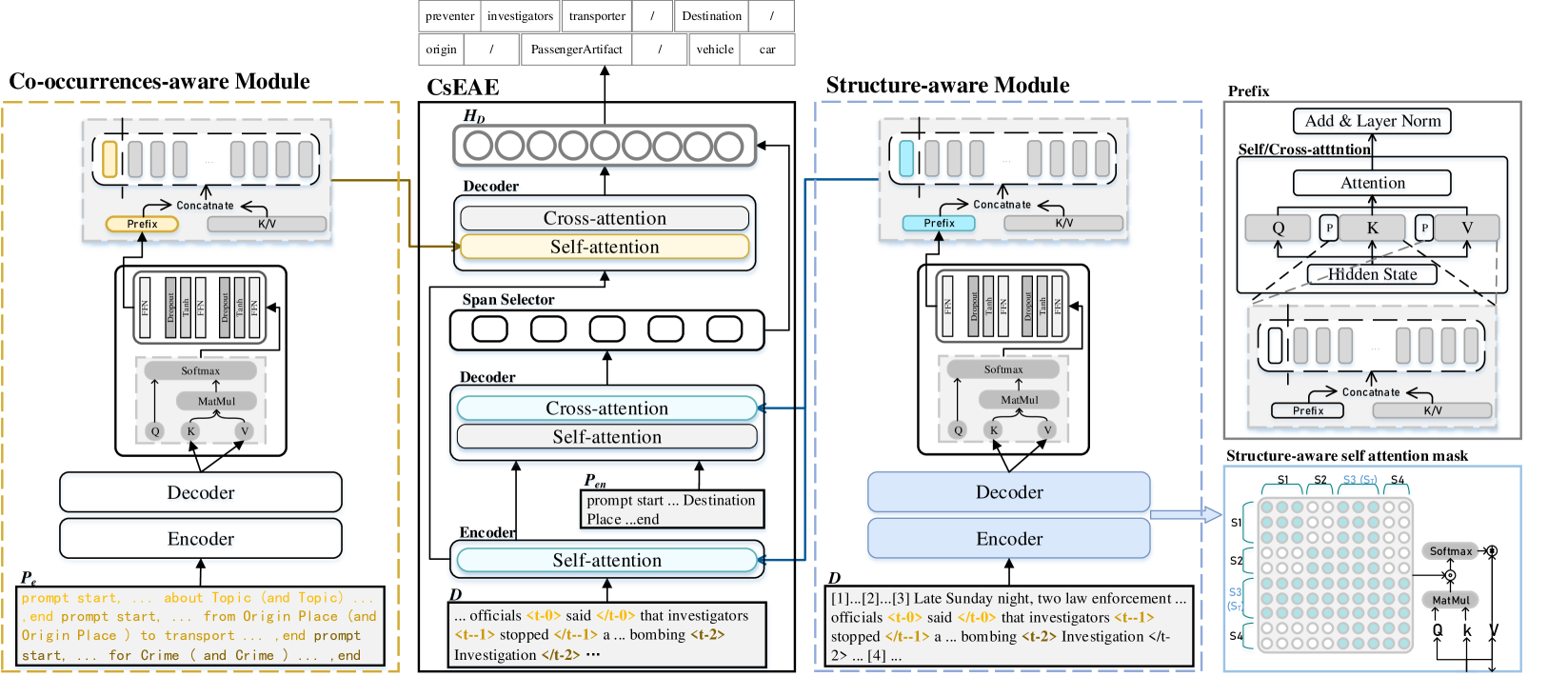
技术框架:CsEAE模型包含两个主要模块:协同感知模块和结构感知模块。协同感知模块通过上下文标记和协同事件提示抽取,整合文档中所有事件的信息,帮助模型区分事件边界。结构感知模块通过建立触发词所在句子与文档中其他句子之间的结构关系,减少冗余信息的干扰。对于LLM,则采用提示学习的方式,将事件论元抽取任务转化为生成任务,并使用监督微调进行训练。
关键创新:论文的关键创新在于:1) 提出了协同感知和结构感知模块,有效解决了SLM在文档级事件论元抽取中面临的事件边界模糊和冗余信息干扰问题;2) 探索了利用提示学习将LLM应用于文档级事件论元抽取任务的可能性,并取得了显著的性能提升;3) 验证了在SLM上获得的洞见可以有效迁移到LLM,为后续研究提供了新的思路。
关键设计:协同感知模块使用上下文标记来区分不同事件,并利用协同事件提示抽取来获取事件之间的关系。结构感知模块通过注意力机制建立触发词所在句子与文档中其他句子之间的联系。对于LLM,提示的设计至关重要,需要能够清晰地表达事件论元抽取的任务目标,并引导LLM生成正确的答案。损失函数采用交叉熵损失函数,优化目标是最小化预测结果与真实标签之间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CsEAE模型在Rams、WikiEvents和MLEE数据集上,Arg-C F1指标分别提升了2.1%、2.3%和3.2%,显著优于基线模型PAIE。同时,通过提示学习和微调,LLM在文档级事件论元抽取任务上取得了与SLM相当的性能,并可以通过借鉴CsEAE的洞见进一步提升性能。
🎯 应用场景
该研究成果可应用于信息抽取、知识图谱构建、智能问答等领域。例如,可以利用该技术从新闻报道、研究论文等文档中自动抽取事件信息,构建事件知识图谱,为舆情分析、风险评估等应用提供支持。此外,该技术还可以用于提升智能问答系统的准确性和可靠性,使其能够更好地理解用户的问题并提供相关的事件信息。
📄 摘要(原文)
Document-level Event Argument Extraction (EAE) faces two challenges due to increased input length: 1) difficulty in distinguishing semantic boundaries between events, and 2) interference from redundant information. To address these issues, we propose two methods. The first method introduces the Co and Structure Event Argument Extraction model (CsEAE) based on Small Language Models (SLMs). CsEAE includes a co-occurrences-aware module, which integrates information about all events present in the current input through context labeling and co-occurrences event prompts extraction. Additionally, CsEAE includes a structure-aware module that reduces interference from redundant information by establishing structural relationships between the sentence containing the trigger and other sentences in the document. The second method introduces new prompts to transform the extraction task into a generative task suitable for Large Language Models (LLMs), addressing gaps in EAE performance using LLMs under Supervised Fine-Tuning (SFT) conditions. We also fine-tuned multiple datasets to develop an LLM that performs better across most datasets. Finally, we applied insights from CsEAE to LLMs, achieving further performance improvements. This suggests that reliable insights validated on SLMs are also applicable to LLMs. We tested our models on the Rams, WikiEvents, and MLEE datasets. The CsEAE model achieved improvements of 2.1\%, 2.3\%, and 3.2\% in the Arg-C F1 metric compared to the baseline, PAIE~\cite{PAIE}. For LLMs, we demonstrated that their performance on document-level datasets is comparable to that of SLMs~\footnote{All code is available at https://github.com/simon-p-j-r/CsEAE}.