SSSD: Simply-Scalable Speculative Decoding
作者: Michele Marzollo, Jiawei Zhuang, Niklas Roemer, Niklas Zwingenberger, Lorenz K. Müller, Lukas Cavigelli
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-08 (更新: 2026-01-07)
备注: 16 pages, 6 figures
💡 一句话要点
提出SSSD:一种简单可扩展的无训练推测解码方法,加速大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大语言模型 无训练 n-gram模型 硬件加速 低延迟推理 领域自适应
📋 核心要点
- 现有推测解码方法依赖额外训练模型,增加部署复杂性,且对领域和语言迁移适应性差。
- SSSD通过轻量级n-gram匹配和硬件感知推测,无需训练即可实现高效推测解码。
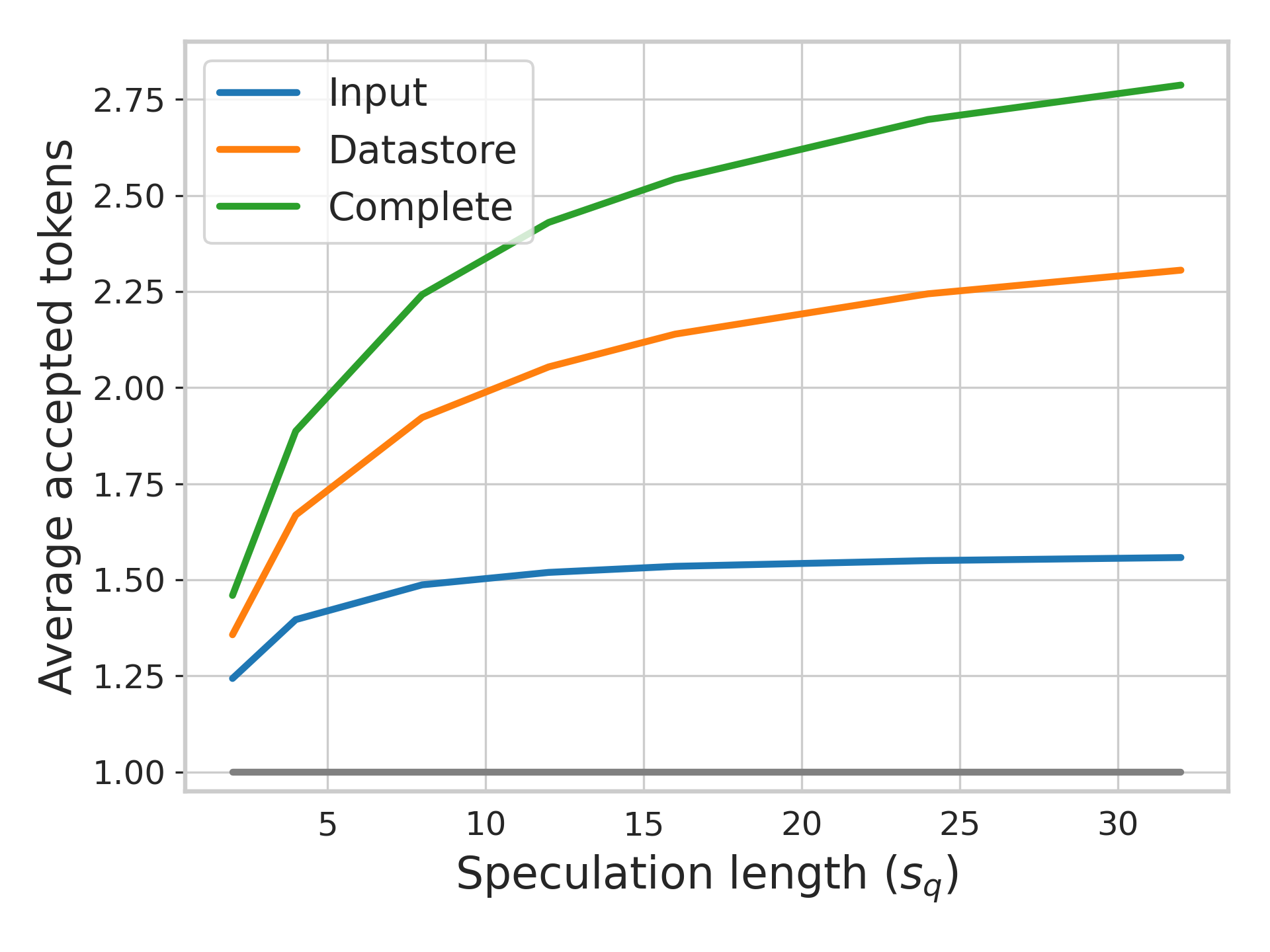
- 实验表明,SSSD在多种基准测试中达到与训练方法相当的性能,延迟降低高达2.9倍,且鲁棒性更强。
📝 摘要(中文)
推测解码已成为加速大型语言模型推理的常用技术。然而,现有方法在生产服务系统中仅产生适度的改进。能够实现显著加速的方法通常依赖于额外的训练过的草稿模型或辅助模型组件,增加了部署和维护的复杂性。这种额外的复杂性降低了灵活性,尤其是在服务工作负载转移到草稿模型训练数据中没有很好表示的任务、领域或语言时。我们引入了简单可扩展的推测解码(SSSD),这是一种无需训练的方法,它将轻量级n-gram匹配与硬件感知推测相结合。相对于标准自回归解码,SSSD最多可减少2.9倍的延迟。它在广泛的基准测试中实现了与领先的基于训练的方法相当的性能,同时需要大大降低的采用工作量——无需数据准备、训练或调整——并且在语言和领域转移以及长上下文设置中表现出卓越的鲁棒性。
🔬 方法详解
问题定义:现有推测解码方法为了提升推理速度,通常需要训练额外的草稿模型。这增加了部署和维护的复杂性,并且草稿模型的训练数据可能无法覆盖所有应用场景,导致在领域或语言发生变化时性能下降。因此,需要一种无需训练、更具鲁棒性的推测解码方法。
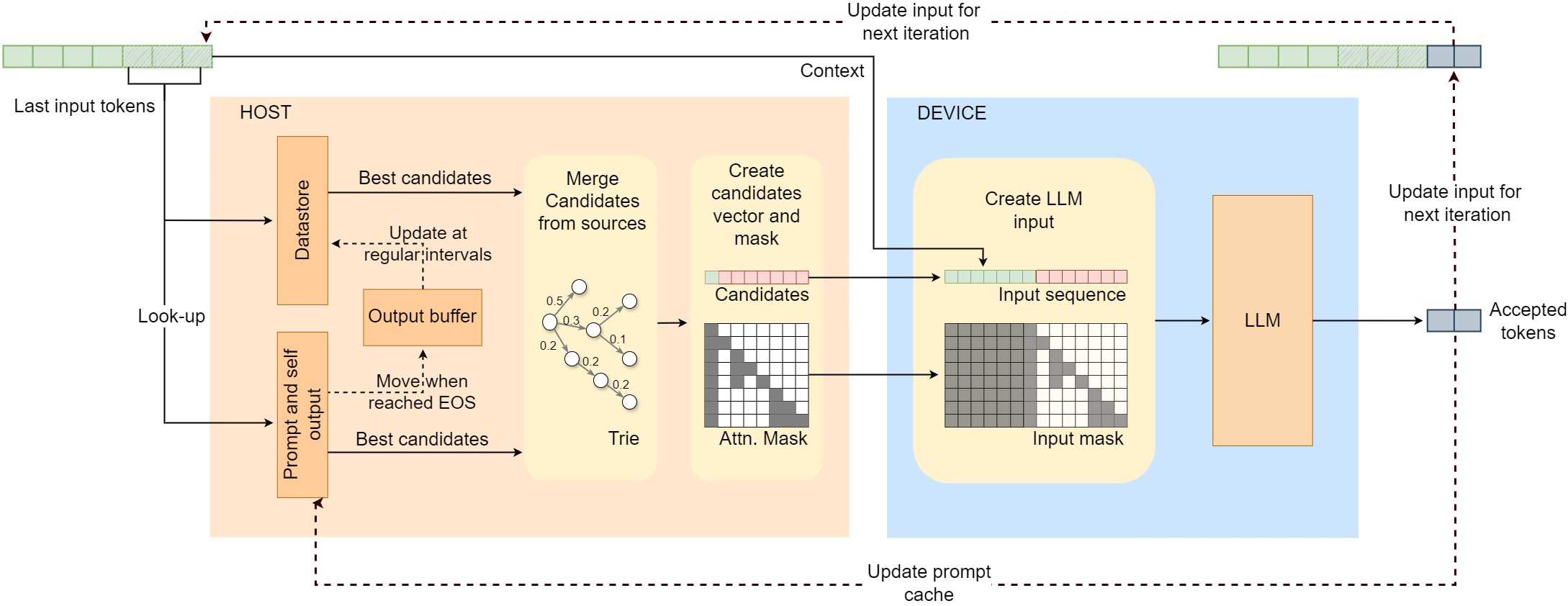
核心思路:SSSD的核心思路是利用n-gram匹配来快速生成候选token序列,然后通过主模型并行验证这些序列。通过结合轻量级的n-gram匹配和硬件感知的推测执行,可以在不增加模型复杂度的前提下,显著提升推理速度。
技术框架:SSSD的整体框架包括以下几个步骤:1) 使用n-gram模型快速生成多个候选token序列;2) 将这些候选序列与主模型并行执行,验证其正确性;3) 将验证通过的token添加到已生成的序列中,并重复上述过程,直到达到预定的序列长度或遇到验证失败的token。
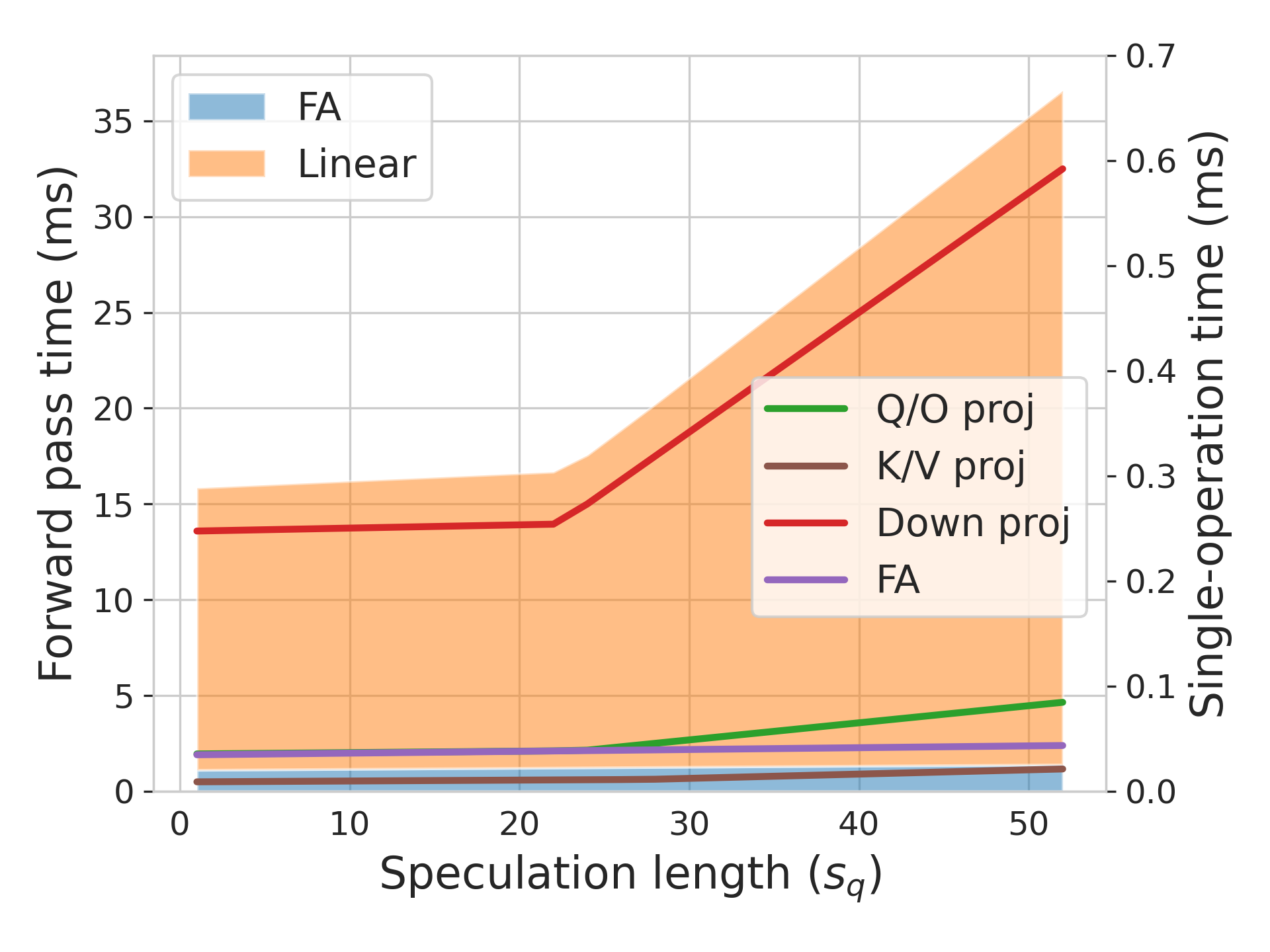
关键创新:SSSD的关键创新在于其无需训练的特性,以及将n-gram匹配与硬件感知推测相结合。与需要训练草稿模型的方法相比,SSSD避免了额外的训练成本和模型维护负担,并且对领域和语言的变化具有更强的适应性。硬件感知推测则充分利用了现代硬件的并行计算能力,进一步提升了推理效率。
关键设计:SSSD的关键设计包括:1) n-gram模型的选择和配置,需要权衡模型的复杂度和预测准确性;2) 候选token序列的生成策略,需要保证序列的多样性和质量;3) 硬件感知的推测执行策略,需要充分利用硬件的并行计算能力,并避免资源竞争。
🖼️ 关键图片
📊 实验亮点
SSSD在多个基准测试中实现了与领先的基于训练的方法相当的性能,同时延迟降低高达2.9倍。与需要训练草稿模型的方法相比,SSSD无需数据准备、训练或调整,大大降低了部署成本。此外,实验表明SSSD在语言和领域转移以及长上下文设置中表现出卓越的鲁棒性。
🎯 应用场景
SSSD可广泛应用于各种需要快速推理的大语言模型应用场景,例如在线对话系统、机器翻译、文本摘要等。其无需训练的特性使其特别适用于资源受限的环境和需要快速部署的场景。此外,SSSD的鲁棒性使其在处理领域或语言变化时具有优势,能够提升用户体验。
📄 摘要(原文)
Speculative Decoding has emerged as a popular technique for accelerating inference in Large Language Models. However, most existing approaches yield only modest improvements in production serving systems. Methods that achieve substantial speedups typically rely on an additional trained draft model or auxiliary model components, increasing deployment and maintenance complexity. This added complexity reduces flexibility, particularly when serving workloads shift to tasks, domains, or languages that are not well represented in the draft model's training data. We introduce Simply-Scalable Speculative Decoding (SSSD), a training-free method that combines lightweight n-gram matching with hardware-aware speculation. Relative to standard autoregressive decoding, SSSD reduces latency by up to 2.9x. It achieves performance on par with leading training-based approaches across a broad range of benchmarks, while requiring substantially lower adoption effort--no data preparation, training or tuning are needed--and exhibiting superior robustness under language and domain shift, as well as in long-context settings.