RefreshKV: Updating Small KV Cache During Long-form Generation
作者: Fangyuan Xu, Tanya Goyal, Eunsol Choi
分类: cs.CL
发布日期: 2024-11-08 (更新: 2025-03-03)
💡 一句话要点
RefreshKV:通过动态更新小KV缓存提升长文本生成性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 KV缓存 注意力机制 语言模型 推理加速
📋 核心要点
- 现有KV缓存压缩方法在长文本生成中性能下降,因为它们过早地移除了后续可能有用的token。
- RefreshKV通过在生成过程中交替使用完整上下文注意力和子集注意力,并动态更新KV缓存来解决此问题。
- 实验表明,RefreshKV在加速推理的同时,提高了长文本生成任务的性能,并且持续预训练可以进一步提升性能。
📝 摘要(中文)
对于大型语言模型(LLM)而言,给定长上下文输入生成长序列token是一项计算密集型任务。一种常见的推理加速方法是构建更小的键值(KV)缓存,从而减轻LLM对长序列token进行注意力计算的负担。虽然这些方法在生成短序列时表现良好,但对于长文本生成,其性能会迅速下降。大多数KV压缩只进行一次,过早地移除了后续生成可能有用的token。我们提出了一种新的推理方法RefreshKV,它在生成过程中灵活地交替使用完整上下文注意力和对输入token子集的注意力。在每个完整注意力步骤之后,我们根据整个输入的注意力模式更新较小的KV缓存。将我们的方法应用于现成的LLM,可以实现与基于驱逐的方法相当的加速,同时提高各种长文本生成任务的性能。最后,我们表明,使用我们的推理设置进行持续预训练可以进一步提高性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本生成过程中,由于上下文长度过长导致的计算效率低下问题。现有的KV缓存压缩方法虽然能加速推理,但由于一次性的压缩策略,会过早地丢弃对后续生成有用的信息,导致长文本生成质量下降。
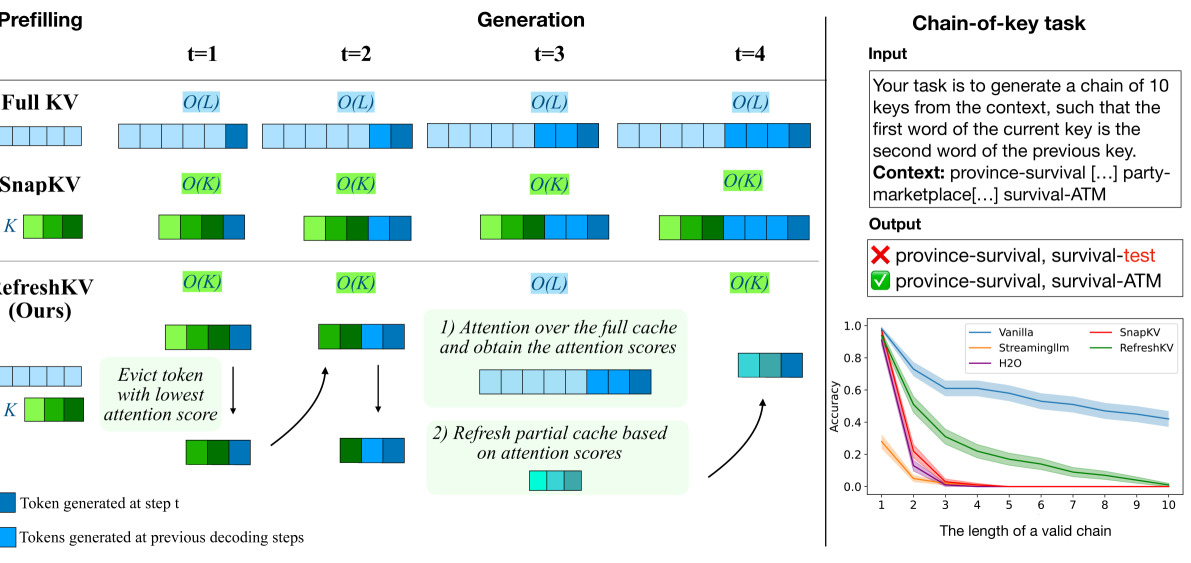
核心思路:RefreshKV的核心思路是在生成过程中,动态地更新KV缓存,而不是像现有方法那样只进行一次静态压缩。通过周期性地执行完整上下文的注意力计算,并根据注意力权重来刷新KV缓存,从而保留重要的历史信息,提升长文本生成质量。
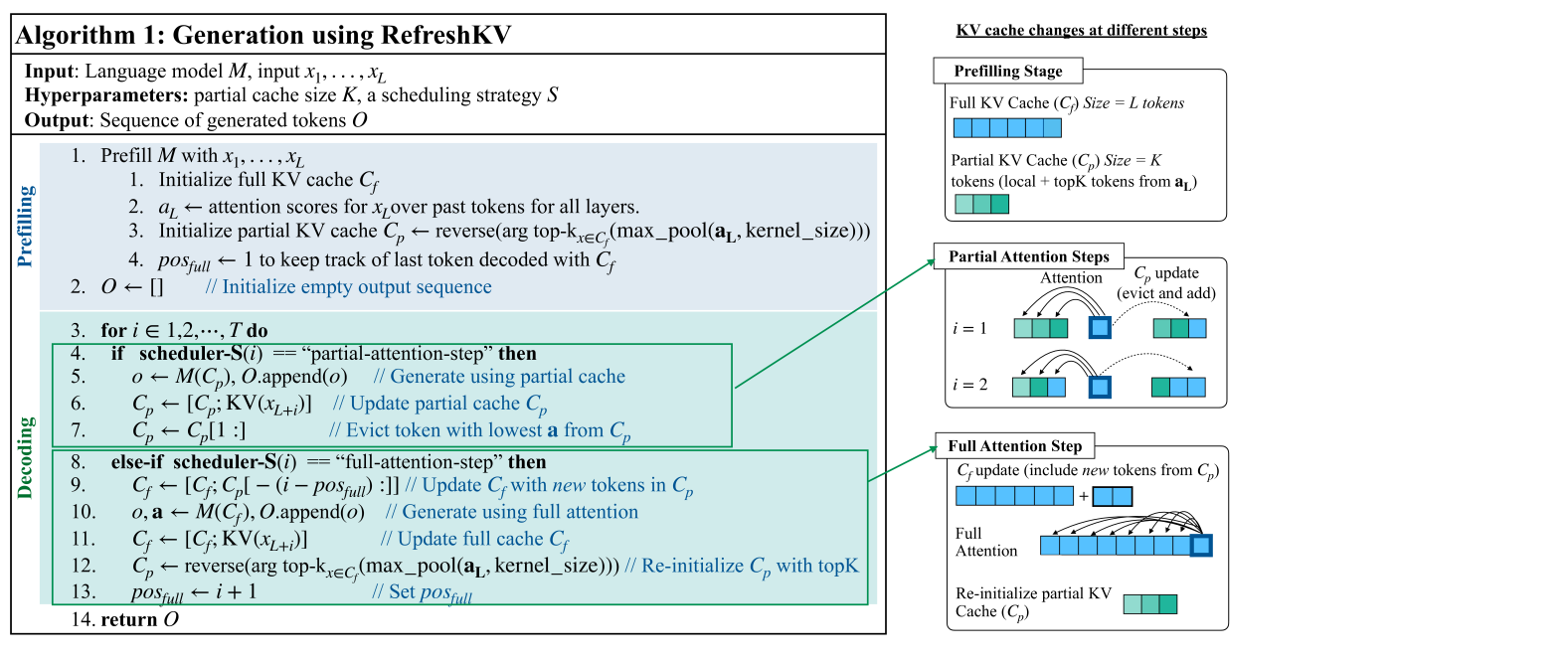
技术框架:RefreshKV的整体框架是在标准的自回归语言模型生成流程中,插入一个KV缓存刷新模块。该模块周期性地执行以下步骤:1) 对整个输入序列执行完整注意力计算;2) 根据注意力权重,选择重要的token,并更新KV缓存;3) 使用更新后的KV缓存进行后续的token生成。
关键创新:RefreshKV的关键创新在于动态更新KV缓存的机制。与静态压缩方法不同,RefreshKV能够根据生成过程中的注意力分布,自适应地调整KV缓存的内容,从而更好地保留重要的上下文信息。
关键设计:RefreshKV的关键设计包括:1) 刷新频率:控制完整注意力计算的周期,需要在计算成本和信息保留之间进行权衡;2) 重要性评估:根据注意力权重选择重要token的策略,例如选择注意力权重最高的top-k个token;3) KV缓存更新:如何将选择的token的KV值合并到现有KV缓存中,例如直接替换或加权平均。
🖼️ 关键图片
📊 实验亮点
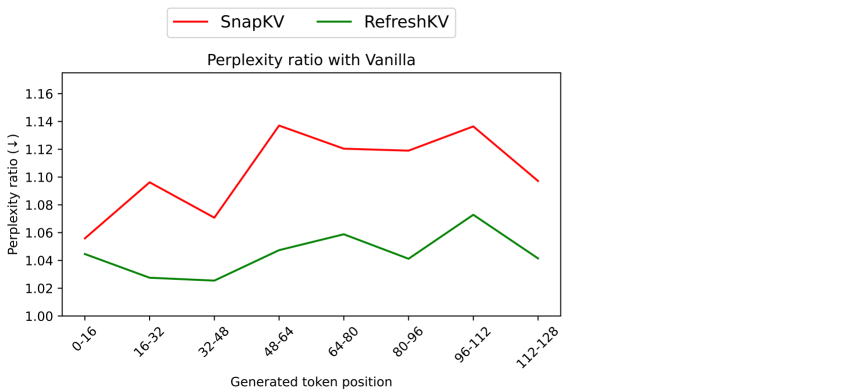
实验结果表明,RefreshKV在保持与现有KV缓存压缩方法相当的加速效果的同时,显著提高了长文本生成任务的性能。通过在多个长文本生成数据集上进行评估,RefreshKV在困惑度等指标上优于基线方法,并且通过持续预训练,性能可以进一步提升。
🎯 应用场景
RefreshKV可应用于各种需要长文本生成的场景,例如长篇小说创作、代码生成、对话系统等。该方法能够提升生成速度,同时保持较高的生成质量,具有重要的实际应用价值。未来,可以将RefreshKV与其他加速技术结合,进一步提升长文本生成的效率和质量。
📄 摘要(原文)
Generating long sequences of tokens given a long-context input is a very compute-intensive inference scenario for large language models (LLMs). One prominent inference speed-up approach is to construct a smaller key-value (KV) cache, relieving LLMs from computing attention over a long sequence of tokens. While such methods work well to generate short sequences, their performance degrades rapidly for long-form generation. Most KV compression happens once, prematurely removing tokens that can be useful later in the generation. We propose a new inference method, RefreshKV, that flexibly alternates between full context attention and attention over a subset of input tokens during generation. After each full attention step, we update the smaller KV cache based on the attention pattern over the entire input. Applying our method to off-the-shelf LLMs achieves comparable speedup to eviction-based methods while improving performance for various long-form generation tasks. Lastly, we show that continued pretraining with our inference setting brings further gains in performance.