Evaluating and Adapting Large Language Models to Represent Folktales in Low-Resource Languages
作者: JA Meaney, Beatrice Alex, William Lamb
分类: cs.CL
发布日期: 2024-11-08
💡 一句话要点
评估并调整大型语言模型以表示低资源语言中的民间故事
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 民间故事 大型语言模型 领域预训练 文本分类
📋 核心要点
- 数字民俗研究依赖于对民间故事文本数据的抽象表示,但现有方法在低资源语言上的表现有待提升。
- 论文通过调整大型语言模型,使其能够更好地处理长序列,并在民间故事领域进行持续预训练,从而提升模型性能。
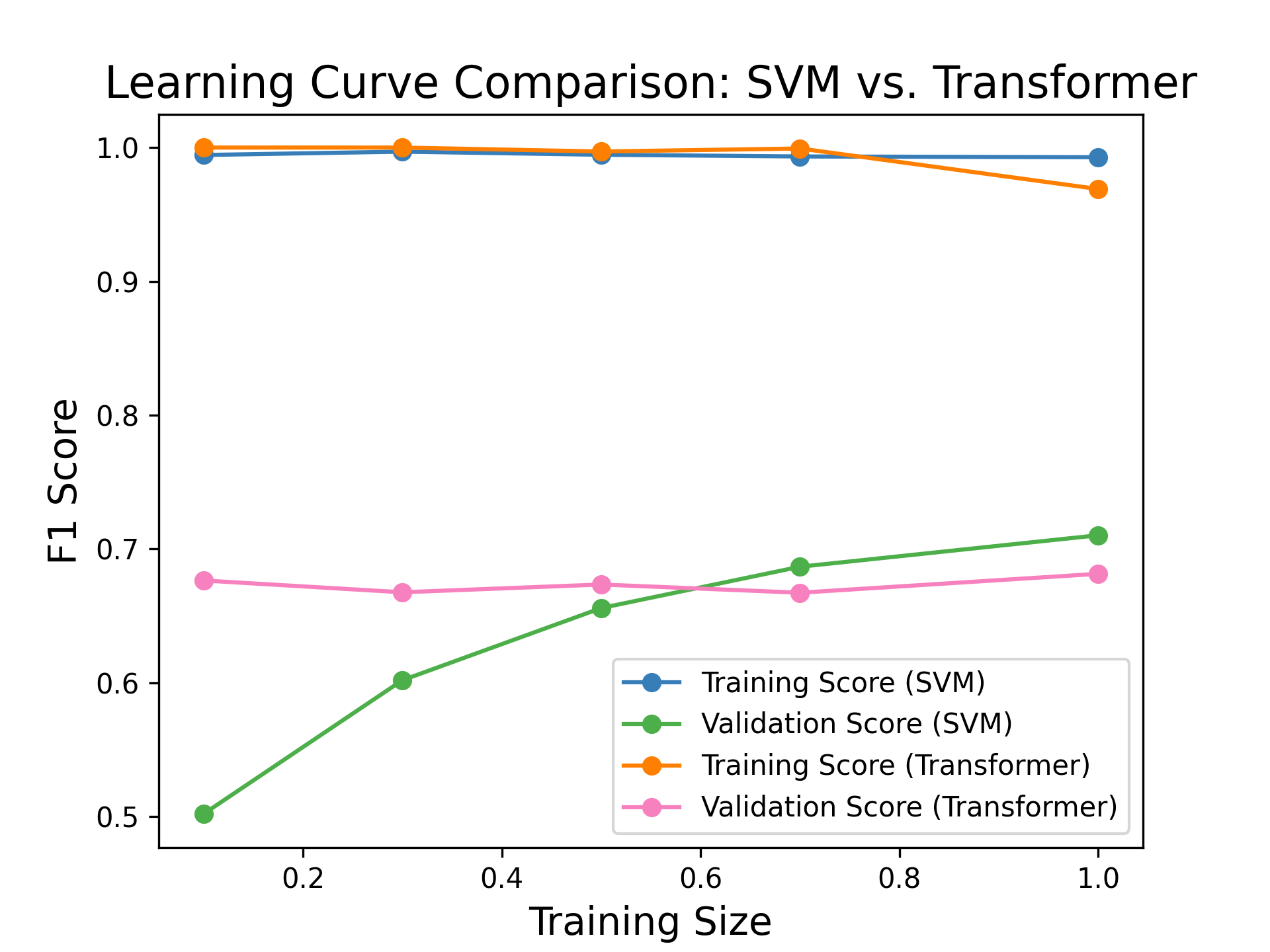
- 实验结果表明,所提出的调整方法能够提高分类性能,但同时也发现基线SVM在非上下文特征上的表现也相当出色。
📝 摘要(中文)
民间故事是关于一个文明的社会和文化的丰富知识资源。数字民俗研究旨在利用自动化技术来更好地理解这些民间故事,并且它依赖于文本数据的抽象表示。虽然许多大型语言模型(LLM)声称能够表示爱尔兰语和盖尔语等低资源语言,但我们提出了两个分类任务来探索这些表示的有用性,以及三个调整来提高这些模型的性能。我们发现,调整模型以处理更长的序列,并继续在民间故事领域进行预训练,可以提高分类性能,尽管这些发现因具有非上下文特征的基线SVM的令人印象深刻的性能而有所缓和。
🔬 方法详解
问题定义:论文旨在解决低资源语言(如爱尔兰语和盖尔语)的民间故事表示问题。现有的大型语言模型虽然声称支持这些语言,但在实际应用中,其表示能力和分类性能仍有不足,难以有效支持数字民俗研究。现有方法的痛点在于无法充分捕捉低资源语言民间故事的语言特征和文化内涵。
核心思路:论文的核心思路是通过对现有大型语言模型进行针对性的调整和优化,使其更好地适应低资源语言民间故事的特点。具体而言,包括调整模型以处理更长的序列,以及在民间故事领域进行持续预训练。这样设计的目的是为了增强模型对长文本的理解能力,并使其更好地学习和掌握民间故事的特定知识和表达方式。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择合适的大型语言模型作为基础模型;2) 构建包含低资源语言民间故事的训练数据集;3) 对基础模型进行调整,包括调整序列长度和进行领域预训练;4) 在分类任务上评估调整后的模型性能;5) 与基线方法(如SVM)进行比较。
关键创新:论文的关键创新在于提出了针对低资源语言民间故事的语言模型调整策略。与直接使用预训练模型相比,该方法能够更好地适应特定领域的数据特征,从而提高模型在相关任务上的性能。此外,论文还探讨了序列长度和领域预训练对模型性能的影响,为后续研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) 调整模型以适应更长的序列长度,以便处理包含复杂情节和细节的民间故事;2) 使用低资源语言民间故事数据集对模型进行持续预训练,以增强模型对特定领域知识的理解;3) 设计合适的分类任务来评估模型性能,例如故事分类和主题分类;4) 选择合适的评估指标,如准确率、精确率、召回率和F1值。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过调整模型以处理更长的序列,并在民间故事领域进行持续预训练,可以提高分类性能。虽然具体性能数据未在摘要中给出,但强调了这些调整方法带来的性能提升。同时,论文也指出,具有非上下文特征的基线SVM表现出色,这表明在低资源语言环境下,传统方法仍然具有一定的竞争力。
🎯 应用场景
该研究成果可应用于数字民俗研究、文化遗产保护、低资源语言自然语言处理等领域。通过构建更有效的低资源语言民间故事表示模型,可以促进对这些珍贵文化资源的理解、传承和利用,并为相关领域的研究提供技术支持。未来,该研究思路还可以推广到其他低资源语言和文化领域。
📄 摘要(原文)
Folktales are a rich resource of knowledge about the society and culture of a civilisation. Digital folklore research aims to use automated techniques to better understand these folktales, and it relies on abstract representations of the textual data. Although a number of large language models (LLMs) claim to be able to represent low-resource langauges such as Irish and Gaelic, we present two classification tasks to explore how useful these representations are, and three adaptations to improve the performance of these models. We find that adapting the models to work with longer sequences, and continuing pre-training on the domain of folktales improves classification performance, although these findings are tempered by the impressive performance of a baseline SVM with non-contextual features.