Assessing the Answerability of Queries in Retrieval-Augmented Code Generation
作者: Geonmin Kim, Jaeyeon Kim, Hancheol Park, Wooksu Shin, Tae-Ho Kim
分类: cs.CL
发布日期: 2024-11-08 (更新: 2024-11-25)
💡 一句话要点
提出RaCGEval评估基准,用于评估检索增强代码生成中查询的可回答性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 检索增强 大型语言模型 可回答性评估 基准数据集
📋 核心要点
- 现有RaCG方法在处理无法通过检索到的API回答的查询时,容易生成看似合理但不正确的代码。
- 论文提出评估查询可回答性的任务,判断RaCG能否基于用户查询和检索到的API生成有效答案。
- 构建了RaCGEval基准数据集,实验表明现有模型在该任务上表现不佳,仍有很大提升空间。
📝 摘要(中文)
大型语言模型(LLM)在语言理解和生成方面的能力空前强大,检索增强代码生成(RaCG)已在软件开发者中得到广泛应用。虽然这提高了生产力,但仍然经常出现提供不正确代码的情况。特别是在某些情况下,对于用户提出的、无法通过给定的查询和API描述回答的问题,会生成看似合理但不正确的代码。本研究提出了一项评估可回答性的任务,该任务评估在RaCG中,基于用户的查询和检索到的API是否可以生成有效的答案。此外,我们构建了一个名为检索增强代码生成能力评估(RaCGEval)的基准数据集,以评估执行此任务的模型的性能。实验结果表明,这项任务仍然具有很大的挑战性,基线模型的性能仅为46.7%。此外,本研究还讨论了可以显著提高性能的方法。
🔬 方法详解
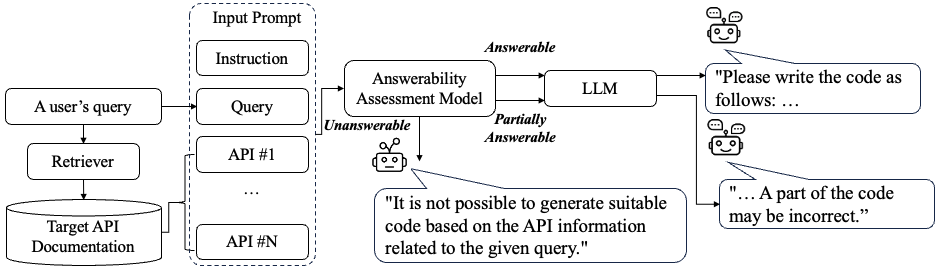
问题定义:论文旨在解决检索增强代码生成(RaCG)中,模型对于无法回答的查询生成“幻觉”代码的问题。现有RaCG方法在面对用户提出的、无法通过检索到的API描述来回答的查询时,仍然会生成看似合理但实际上不正确的代码。这降低了RaCG的可靠性和实用性,也给开发者带来困扰。
核心思路:论文的核心思路是引入一个可回答性评估任务,即判断给定的用户查询和检索到的API描述是否足以生成正确的代码。通过显式地评估模型的可回答性,可以帮助模型更好地识别无法回答的查询,从而避免生成错误的“幻觉”代码。
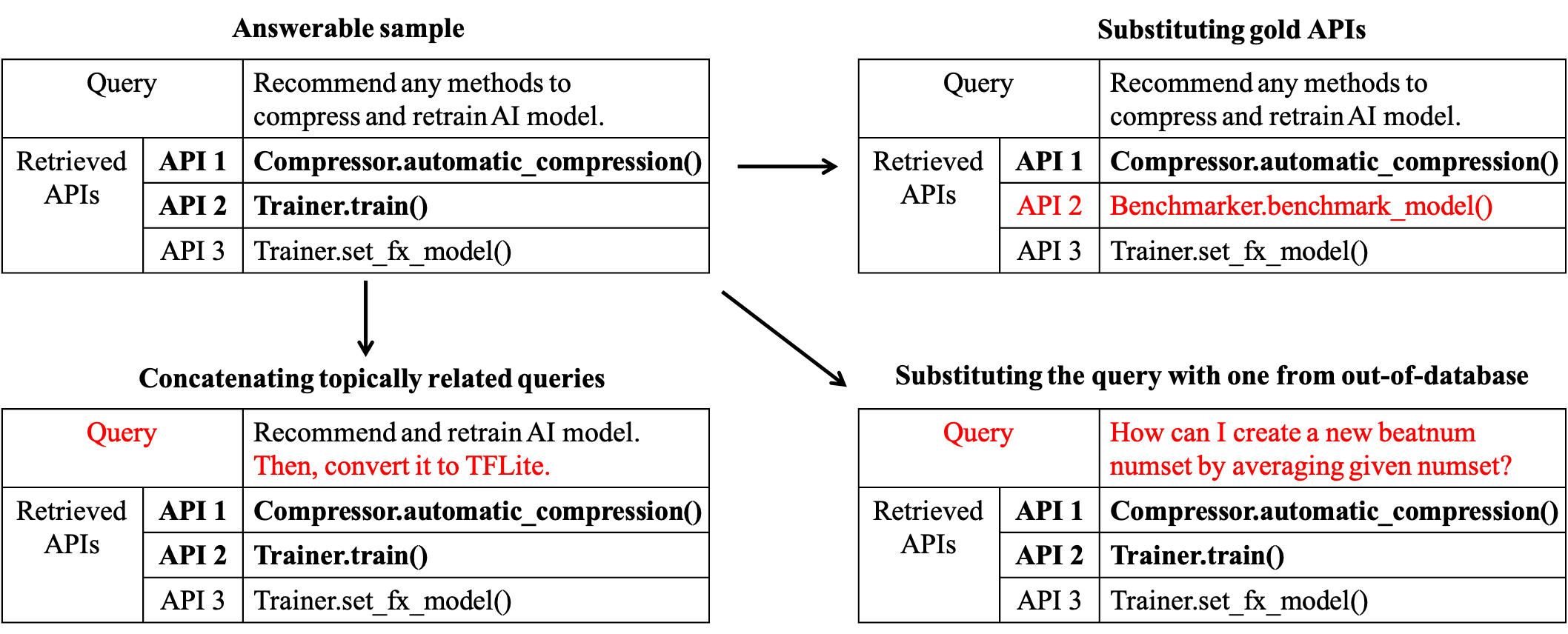
技术框架:论文构建了一个名为RaCGEval的基准数据集,用于评估模型的可回答性。该数据集包含用户查询、检索到的API描述以及对应的代码。模型需要判断给定的查询和API描述是否足以生成正确的代码。论文还提出了几种基线模型,并评估了它们在RaCGEval上的性能。
关键创新:论文的关键创新在于提出了一个全新的评估任务——可回答性评估,并构建了相应的基准数据集RaCGEval。这为研究RaCG中的“幻觉”问题提供了一个新的视角和评估工具。此外,论文还探讨了如何利用可回答性评估来提高RaCG的性能。
关键设计:RaCGEval数据集的构建细节未知,论文中没有详细描述数据集的规模、数据来源以及标注方法。基线模型采用的具体架构和训练策略也未知。论文中提到了一些可以提高性能的方法,但具体细节也未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有基线模型在RaCGEval基准上的性能较低,仅为46.7%,表明该任务具有很大的挑战性。这说明现有RaCG模型在判断查询可回答性方面存在明显不足,需要进一步的研究和改进。论文还讨论了可能显著提高性能的方法,但具体细节未知。
🎯 应用场景
该研究成果可应用于提升代码生成工具的可靠性和准确性,减少开发者在调试和验证代码方面的工作量。通过提高代码生成的可信度,可以加速软件开发流程,降低开发成本。未来,该技术还可以应用于智能编程助手、自动化代码审查等领域。
📄 摘要(原文)
Thanks to unprecedented language understanding and generation capabilities of large language model (LLM), Retrieval-augmented Code Generation (RaCG) has recently been widely utilized among software developers. While this has increased productivity, there are still frequent instances of incorrect codes being provided. In particular, there are cases where plausible yet incorrect codes are generated for queries from users that cannot be answered with the given queries and API descriptions. This study proposes a task for evaluating answerability, which assesses whether valid answers can be generated based on users' queries and retrieved APIs in RaCG. Additionally, we build a benchmark dataset called Retrieval-augmented Code Generability Evaluation (RaCGEval) to evaluate the performance of models performing this task. Experimental results show that this task remains at a very challenging level, with baseline models exhibiting a low performance of 46.7%. Furthermore, this study discusses methods that could significantly improve performance.