KyrgyzNLP: Challenges, Progress, and Future
作者: Anton Alekseev, Timur Turatali
分类: cs.CL
发布日期: 2024-11-08 (更新: 2024-11-16)
备注: Keynote talk at the 12th International Conference on Analysis of Images, Social Networks and Texts (AIST-2024)
💡 一句话要点
关注吉尔吉斯语NLP:挑战、进展与未来展望
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 吉尔吉斯语 自然语言处理 低资源语言 语言资源 社区驱动
📋 核心要点
- 大型语言模型主要服务于高资源语言,低资源语言的NLP发展滞后,吉尔吉斯语是典型代表。
- 论文强调人工标注数据的重要性,尤其是在低资源语言中,自动评估可能不准确,需要人工干预。
- 论文回顾了吉尔吉斯语NLP的现有资源和研究进展,并提出了未来发展的路线图,强调社区驱动的重要性。
📝 摘要(中文)
大型语言模型(LLMs)在众多基准测试中表现出色,推动了人工智能在语言和非语言任务中的应用。然而,这主要使资源丰富的语言受益,而使资源匮乏的语言(LRLs)处于不利地位。本文重点介绍了吉尔吉斯语(一种资源匮乏的语言)的自然语言处理(NLP)领域的现状。人工评估,包括由母语人士创建的带注释的数据集,仍然是可靠的NLP性能不可替代的组成部分,特别是对于自动评估可能不足的LRL。在最近对突厥语种资源的评估中,吉尔吉斯语被标记为“勉强维持”状态,这是一种由数百万人使用的资源严重不足的语言。考虑到该语言日益增长的重要性,这令人担忧,不仅在吉尔吉斯斯坦,而且在没有官方地位的侨民社区中也是如此。我们回顾了该领域之前的努力,注意到许多公开可用的资源都是最近才开发的,除了词典之外几乎没有例外。虽然最近的论文取得了一些进展,但仍有许多工作要做。尽管吉尔吉斯共和国的商业和政府部门都表示出兴趣和支持,但吉尔吉斯语资源的情况仍然具有挑战性。我们强调社区驱动的努力对于构建这些资源的重要性,以确保未来的进步和可持续性。然后,我们分享我们对吉尔吉斯语NLP中最紧迫的挑战的看法。最后,我们提出了未来研究课题和语言资源发展的路线图。
🔬 方法详解
问题定义:论文旨在解决吉尔吉斯语作为一种低资源语言,在自然语言处理领域面临的资源匮乏和发展滞后的问题。现有方法在高资源语言上表现良好,但无法直接应用于吉尔吉斯语,因为缺乏高质量的标注数据、预训练模型和相关的工具链。这导致吉尔吉斯语NLP任务的性能远低于高资源语言,阻碍了其在实际应用中的推广。
核心思路:论文的核心思路是强调社区驱动的重要性,通过汇集母语人士的知识和力量,共同构建吉尔吉斯语的语言资源。同时,论文呼吁政府和商业部门提供支持,共同推动吉尔吉斯语NLP的发展。此外,论文还提出了未来研究方向和资源建设的路线图,为吉尔吉斯语NLP的长期发展提供指导。
技术框架:论文没有提出具体的技术框架,而是侧重于对吉尔吉斯语NLP领域的现状进行分析和展望。它回顾了现有的资源和研究进展,并指出了未来发展的方向。论文强调了人工标注数据的重要性,并呼吁构建高质量的吉尔吉斯语数据集。此外,论文还建议开发适用于吉尔吉斯语的预训练模型和相关的工具链。
关键创新:论文的主要创新在于其对吉尔吉斯语NLP领域的系统性分析和未来展望。它强调了社区驱动的重要性,并提出了未来发展的路线图。虽然没有提出具体的技术创新,但论文为吉尔吉斯语NLP的发展提供了重要的指导。
关键设计:论文没有涉及具体的技术细节,而是侧重于宏观层面的分析和建议。它强调了数据质量的重要性,并建议采用人工标注的方式构建高质量的吉尔吉斯语数据集。此外,论文还建议开发适用于吉尔吉斯语的预训练模型和相关的工具链,以提高吉尔吉斯语NLP任务的性能。
🖼️ 关键图片

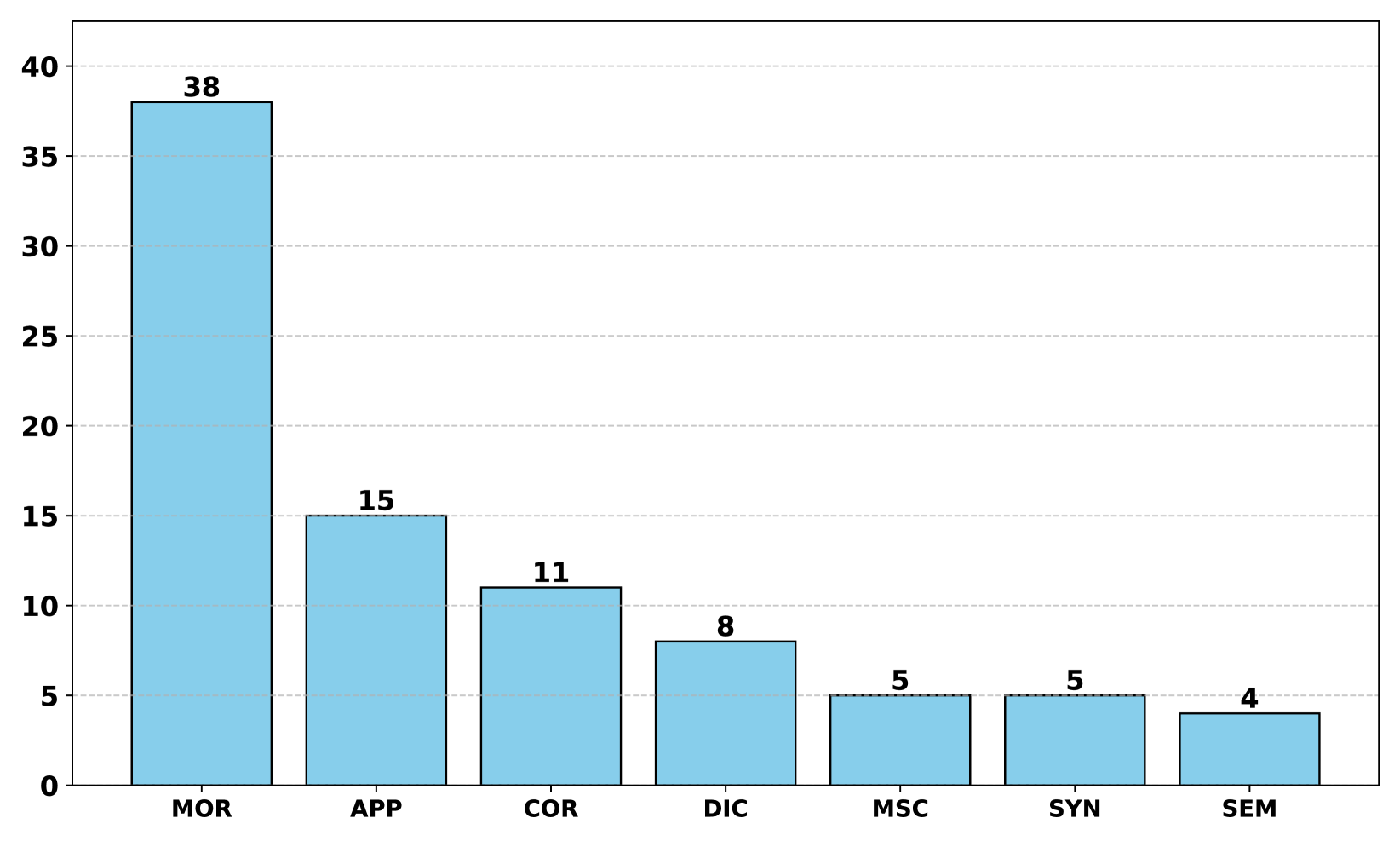

📊 实验亮点
该论文并非实验性研究,而是对吉尔吉斯语NLP领域的现状进行了全面的回顾和分析,并提出了未来发展的方向和建议。它强调了社区驱动的重要性,并呼吁构建高质量的吉尔吉斯语数据集和开发相关的工具链。虽然没有提供具体的性能数据,但该论文为吉尔吉斯语NLP的发展提供了重要的指导。
🎯 应用场景
该研究成果可应用于吉尔吉斯语相关的机器翻译、语音识别、文本分类、信息检索等自然语言处理任务。通过提升吉尔吉斯语NLP技术水平,可以促进吉尔吉斯语在互联网、教育、文化传承等领域的应用,并为吉尔吉斯语使用者提供更便捷的信息服务。
📄 摘要(原文)
Large language models (LLMs) have excelled in numerous benchmarks, advancing AI applications in both linguistic and non-linguistic tasks. However, this has primarily benefited well-resourced languages, leaving less-resourced ones (LRLs) at a disadvantage. In this paper, we highlight the current state of the NLP field in the specific LRL: kyrgyz tili. Human evaluation, including annotated datasets created by native speakers, remains an irreplaceable component of reliable NLP performance, especially for LRLs where automatic evaluations can fall short. In recent assessments of the resources for Turkic languages, Kyrgyz is labeled with the status 'Scraping By', a severely under-resourced language spoken by millions. This is concerning given the growing importance of the language, not only in Kyrgyzstan but also among diaspora communities where it holds no official status. We review prior efforts in the field, noting that many of the publicly available resources have only recently been developed, with few exceptions beyond dictionaries (the processed data used for the analysis is presented at https://kyrgyznlp.github.io/). While recent papers have made some headway, much more remains to be done. Despite interest and support from both business and government sectors in the Kyrgyz Republic, the situation for Kyrgyz language resources remains challenging. We stress the importance of community-driven efforts to build these resources, ensuring the future advancement sustainability. We then share our view of the most pressing challenges in Kyrgyz NLP. Finally, we propose a roadmap for future development in terms of research topics and language resources.