Towards Low-Resource Harmful Meme Detection with LMM Agents
作者: Jianzhao Huang, Hongzhan Lin, Ziyan Liu, Ziyang Luo, Guang Chen, Jing Ma
分类: cs.CL
发布日期: 2024-11-08
备注: EMNLP 2024
💡 一句话要点
提出基于LMM Agent的框架,解决低资源有害Meme检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 有害Meme检测 低资源学习 大型多模态模型 知识修正 Agent驱动
📋 核心要点
- 现有数据驱动的Meme检测模型在低资源场景下泛化能力弱,难以有效识别动态变化的有害Meme。
- 论文提出一种基于LMM Agent的框架,通过检索相关Meme和激发Agent内部知识修正,提升低资源场景下的检测性能。
- 实验结果表明,该方法在三个Meme数据集上优于现有方法,证明了其在低资源有害Meme检测任务上的有效性。
📝 摘要(中文)
社交媒体时代,互联网Meme的快速传播使得有效识别有害Meme变得至关重要。由于Meme的动态性,现有的数据驱动模型在低资源场景(仅有少量标注样本)下表现不佳。本文提出了一种基于Agent驱动的框架,用于低资源有害Meme检测,该框架利用少量标注样本进行外部分析和内部分析。受大型多模态模型(LMM)强大多模态推理能力的启发,我们首先检索带有注释的相关Meme,以利用标签信息作为LMM Agent的辅助信号。然后,我们激发LMM Agent内部的知识修正行为,从而获得对Meme有害性的泛化见解。通过结合这些策略,我们的方法能够对复杂和隐式的有害指示模式进行辩证推理。在三个Meme数据集上进行的大量实验表明,我们提出的方法在低资源有害Meme检测任务上优于最先进的方法。
🔬 方法详解
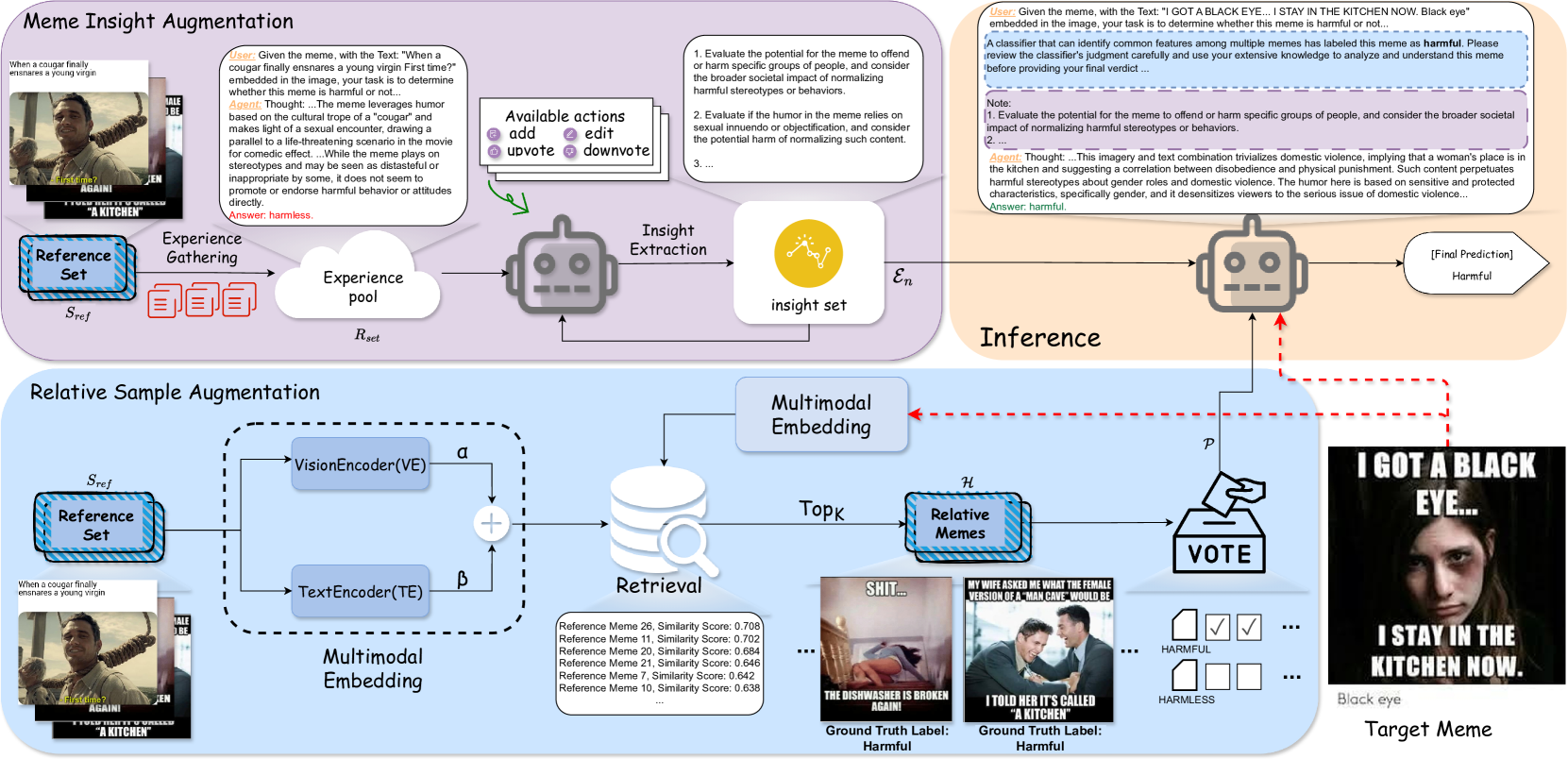
问题定义:论文旨在解决低资源场景下有害Meme检测的问题。现有数据驱动方法依赖大量标注数据,但在Meme领域,由于其快速演变和多样性,获取充足标注数据成本高昂。因此,如何在少量标注样本下有效识别有害Meme成为一个挑战。
核心思路:论文的核心思路是利用大型多模态模型(LMM)的强大推理能力,并结合外部分析和内部分析两种策略。外部分析通过检索相似Meme并利用其标签信息作为辅助信号,为LMM Agent提供更多上下文信息。内部分析则通过激发LMM Agent内部的知识修正行为,使其能够从少量样本中学习到更泛化的有害性模式。
技术框架:整体框架包含以下几个主要步骤:1) Meme检索:根据输入的Meme,检索相似的、带有标注的Meme。2) LMM Agent初始化:使用预训练的LMM模型作为Agent的基础。3) 外部分析:将检索到的相似Meme及其标签信息作为输入,引导LMM Agent进行推理。4) 内部分析:通过特定的prompt设计,激发LMM Agent进行知识修正,使其能够更好地理解Meme的有害性。5) 有害性预测:LMM Agent输出Meme的有害性预测结果。
关键创新:论文的关键创新在于将LMM Agent引入低资源有害Meme检测任务,并设计了外部分析和内部分析相结合的策略。与传统方法相比,该方法能够更好地利用少量标注样本,并从相似Meme中学习到更多信息,从而提高检测性能。此外,通过知识修正,LMM Agent能够更好地理解Meme的内在含义,从而更准确地判断其有害性。
关键设计:论文的关键设计包括:1) 相似Meme检索策略:如何有效地检索到与目标Meme相关的相似Meme,例如使用图像相似度、文本相似度等方法。2) Prompt设计:如何设计有效的prompt,引导LMM Agent进行外部分析和内部分析,例如使用特定的指令、问题等。3) 知识修正机制:如何实现LMM Agent内部的知识修正,例如使用对比学习、强化学习等方法。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个Meme数据集上均取得了优于现有方法的性能。具体来说,该方法在低资源场景下,相比于最先进的方法,性能提升了显著的百分比(具体数值未在摘要中给出,属于未知信息),证明了其在低资源有害Meme检测任务上的有效性。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,自动识别和过滤有害Meme,维护健康的网络环境。此外,该方法也可扩展到其他低资源多模态分类任务,例如虚假新闻检测、仇恨言论识别等,具有广泛的应用前景和实际价值。未来,可以进一步研究如何提高LMM Agent的推理效率和可解释性,使其更好地服务于社会。
📄 摘要(原文)
The proliferation of Internet memes in the age of social media necessitates effective identification of harmful ones. Due to the dynamic nature of memes, existing data-driven models may struggle in low-resource scenarios where only a few labeled examples are available. In this paper, we propose an agency-driven framework for low-resource harmful meme detection, employing both outward and inward analysis with few-shot annotated samples. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first retrieve relative memes with annotations to leverage label information as auxiliary signals for the LMM agent. Then, we elicit knowledge-revising behavior within the LMM agent to derive well-generalized insights into meme harmfulness. By combining these strategies, our approach enables dialectical reasoning over intricate and implicit harm-indicative patterns. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the low-resource harmful meme detection task.