Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
作者: Chien-yu Huang, Wei-Chih Chen, Shu-wen Yang, Andy T. Liu, Chen-An Li, Yu-Xiang Lin, Wei-Cheng Tseng, Anuj Diwan, Yi-Jen Shih, Jiatong Shi, William Chen, Chih-Kai Yang, Wenze Ren, Xuanjun Chen, Chi-Yuan Hsiao, Puyuan Peng, Shih-Heng Wang, Chun-Yi Kuan, Ke-Han Lu, Kai-Wei Chang, Fabian Ritter-Gutierrez, Kuan-Po Huang, Siddhant Arora, You-Kuan Lin, Ming To Chuang, Eunjung Yeo, Kalvin Chang, Chung-Ming Chien, Kwanghee Choi, Jun-You Wang, Cheng-Hsiu Hsieh, Yi-Cheng Lin, Chee-En Yu, I-Hsiang Chiu, Heitor R. Guimarães, Jionghao Han, Tzu-Quan Lin, Tzu-Yuan Lin, Homu Chang, Ting-Wu Chang, Chun Wei Chen, Shou-Jen Chen, Yu-Hua Chen, Hsi-Chun Cheng, Kunal Dhawan, Jia-Lin Fang, Shi-Xin Fang, Kuan-Yu Fang Chiang, Chi An Fu, Hsien-Fu Hsiao, Ching Yu Hsu, Shao-Syuan Huang, Lee Chen Wei, Hsi-Che Lin, Hsuan-Hao Lin, Hsuan-Ting Lin, Jian-Ren Lin, Ting-Chun Liu, Li-Chun Lu, Tsung-Min Pai, Ankita Pasad, Shih-Yun Shan Kuan, Suwon Shon, Yuxun Tang, Yun-Shao Tsai, Jui-Chiang Wei, Tzu-Chieh Wei, Chengxi Wu, Dien-Ruei Wu, Chao-Han Huck Yang, Chieh-Chi Yang, Jia Qi Yip, Shao-Xiang Yuan, Vahid Noroozi, Zhehuai Chen, Haibin Wu, Karen Livescu, David Harwath, Shinji Watanabe, Hung-yi Lee
分类: cs.CL, eess.AS
发布日期: 2024-11-08 (更新: 2025-06-09)
备注: ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
发布Dynamic-SUPERB Phase-2:一个协同扩展的语音语言模型能力评估基准,包含180个任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音语言模型 评估基准 多模态学习 协同构建 开放数据集
📋 核心要点
- 现有语音语言模型缺乏统一的、覆盖全面的评估基准,难以衡量其在各种任务上的通用能力。
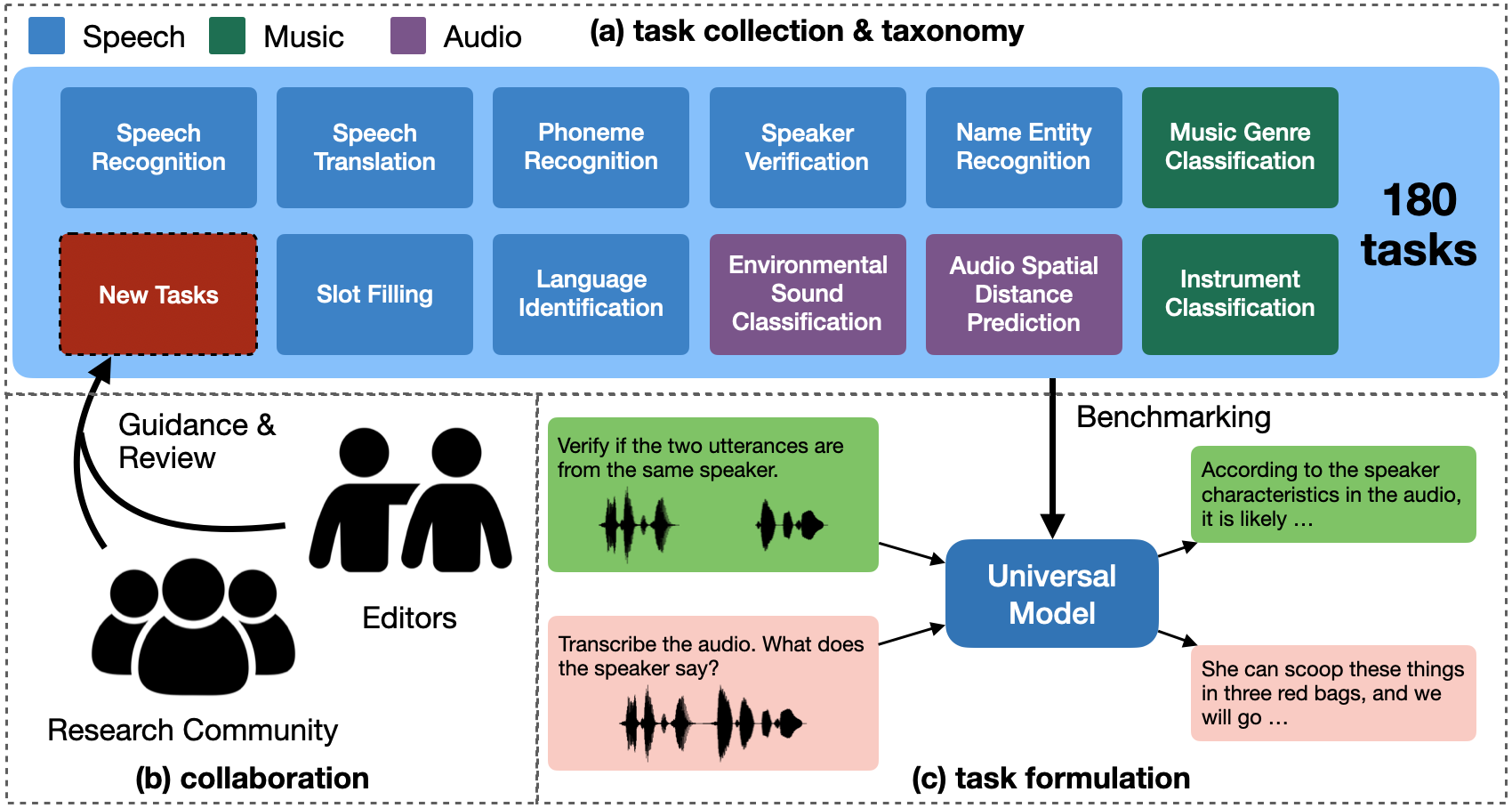
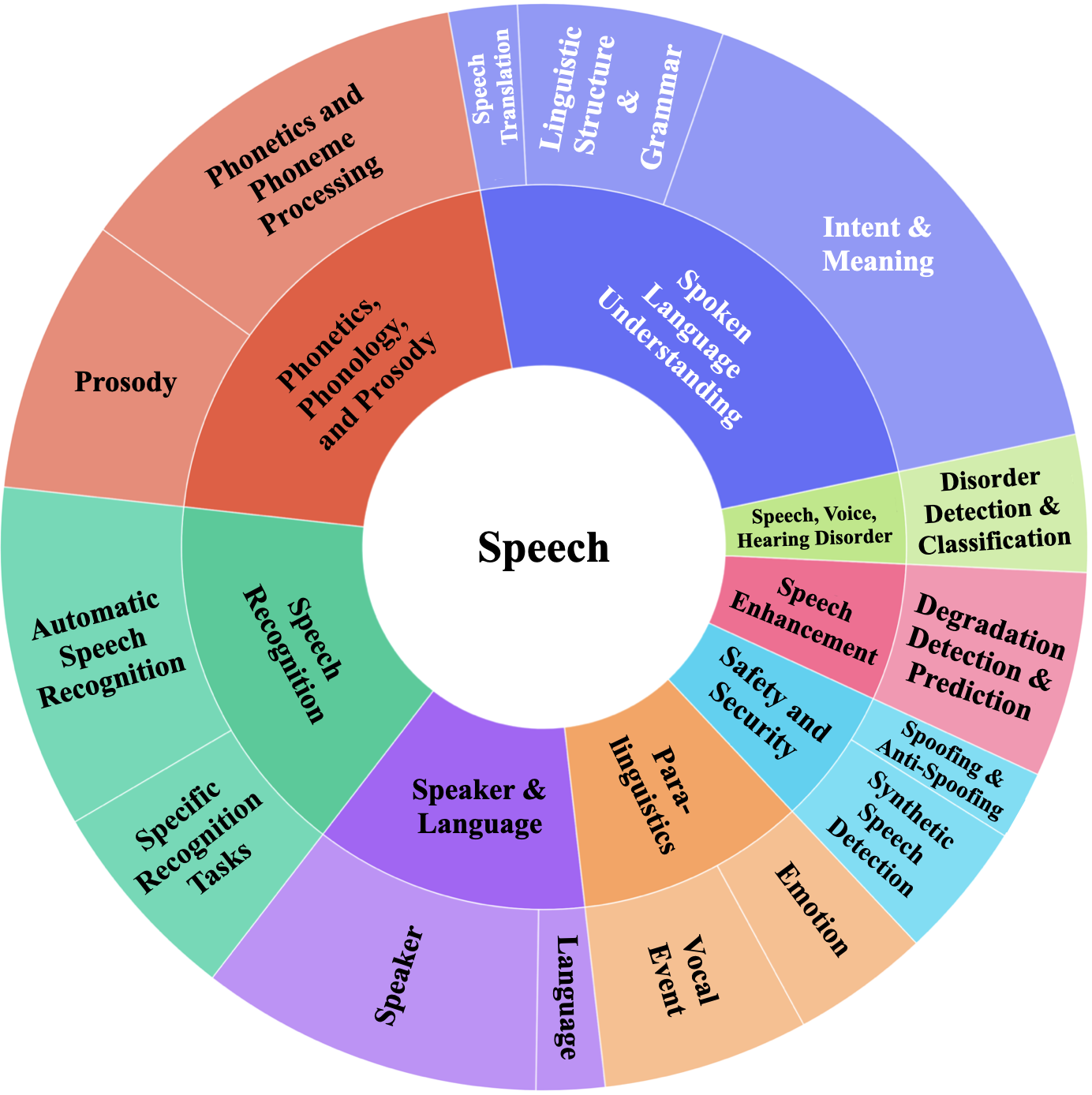
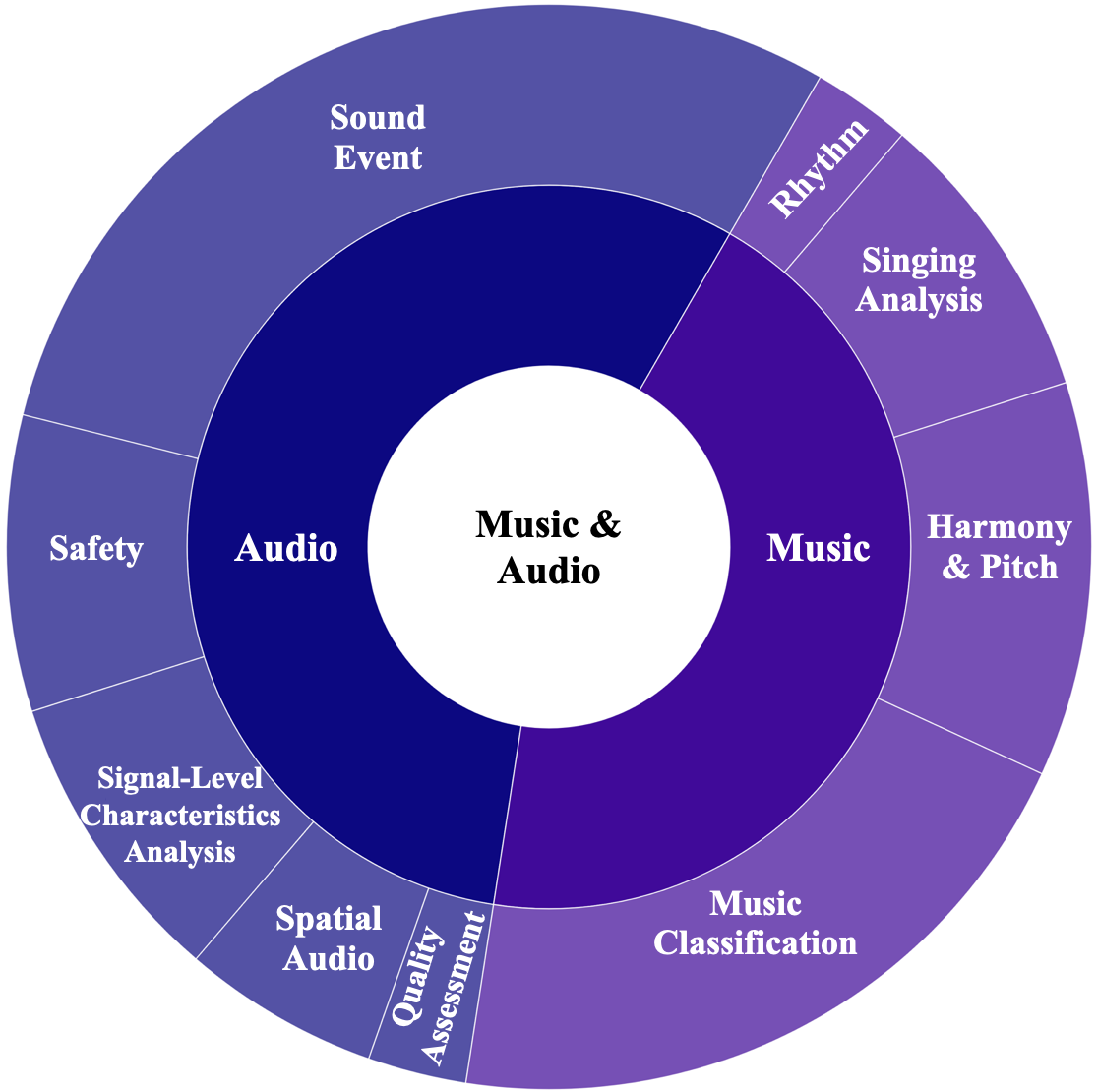
- Dynamic-SUPERB Phase-2通过协同方式构建了一个包含180个任务的开放基准,涵盖语音、音乐和环境音频等多种模态。
- 实验结果表明,现有模型在不同任务上表现差异较大,没有模型能够普遍胜任所有任务,需要进一步的模型创新。
📝 摘要(中文)
多模态基础模型,如Gemini和ChatGPT,通过无缝集成各种形式的数据,彻底改变了人机交互。开发一种能够理解各种自然语言指令的通用语音语言模型,对于弥合沟通鸿沟和促进更直观的交互至关重要。然而,缺乏全面的评估基准构成了一个重大挑战。我们提出了Dynamic-SUPERB Phase-2,这是一个开放且不断发展的基准,用于全面评估基于指令的通用语音模型。在第一代的基础上,第二版整合了全球研究社区协同贡献的125个新任务,将基准扩展到总共180个任务,使其成为语音和音频评估的最大基准。虽然第一代Dynamic-SUPERB仅限于分类任务,但Dynamic-SUPERB Phase-2通过引入各种新颖和多样的任务,包括回归和序列生成,扩展了其评估能力,涵盖语音、音乐和环境音频。评估结果表明,没有模型在所有任务上都表现良好。SALMONN-13B在英语ASR方面表现出色,Qwen2-Audio-7B-Instruct在情感识别方面表现出很高的准确性,但目前的模型仍需要进一步创新才能处理更广泛的任务。我们开源了所有任务数据和评估流程,地址为https://github.com/dynamic-superb/dynamic-superb。
🔬 方法详解
问题定义:论文旨在解决缺乏全面语音语言模型评估基准的问题。现有方法主要痛点在于基准覆盖范围有限,任务类型单一,难以真实反映模型在各种实际应用场景下的能力。之前的Dynamic-SUPERB主要集中在分类任务,无法评估模型在回归和序列生成等任务上的表现。
核心思路:论文的核心思路是通过协同合作的方式,汇集全球研究社区的力量,共同构建一个大规模、多样化的语音语言模型评估基准。通过开放的任务贡献机制,不断扩展基准的任务数量和类型,使其能够更全面地评估模型的通用能力。
技术框架:Dynamic-SUPERB Phase-2的整体框架是一个开放的评估平台,包括任务数据集、评估指标和评估流程。研究人员可以贡献新的任务数据集,并使用平台提供的评估工具对模型进行评估。平台支持多种任务类型,包括分类、回归和序列生成等,涵盖语音、音乐和环境音频等多种模态。
关键创新:Dynamic-SUPERB Phase-2的关键创新在于其协同构建和持续扩展的模式。通过开放的任务贡献机制,吸引了全球研究社区的参与,使得基准能够快速扩展到180个任务,成为目前最大的语音和音频评估基准。此外,Phase-2还引入了更多样化的任务类型,包括回归和序列生成,使得评估更加全面。
关键设计:Dynamic-SUPERB Phase-2的关键设计包括:1) 开放的任务贡献机制,允许研究人员贡献新的任务数据集;2) 标准化的评估流程,确保评估结果的可比性;3) 多样化的评估指标,涵盖不同任务类型的性能评估;4) 持续更新和维护的基准,保持其与时俱进。
🖼️ 关键图片
📊 实验亮点
Dynamic-SUPERB Phase-2的评估结果表明,现有模型在不同任务上的表现差异较大,没有模型能够普遍胜任所有任务。例如,SALMONN-13B在英语ASR方面表现出色,Qwen2-Audio-7B-Instruct在情感识别方面表现出很高的准确性。这些结果揭示了现有模型的局限性,为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于语音识别、语音合成、情感识别、音乐理解、环境声音分析等多个领域。通过使用Dynamic-SUPERB Phase-2基准,研究人员可以更全面地评估语音语言模型的性能,推动相关技术的发展。该基准的开放性和可扩展性,也有助于促进学术界和工业界的合作,共同构建更强大的语音语言模型。
📄 摘要(原文)
Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results show that no model performed well universally. SALMONN-13B excelled in English ASR and Qwen2-Audio-7B-Instruct showed high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We open-source all task data and the evaluation pipeline at https://github.com/dynamic-superb/dynamic-superb.