Deploying Large Language Models With Retrieval Augmented Generation
作者: Sonal Prabhune, Donald J. Berndt
分类: cs.IR, cs.CL
发布日期: 2024-11-07
💡 一句话要点
利用检索增强生成部署大型语言模型,提升信息检索的准确性和可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 信息检索 知识库 AI治理
📋 核心要点
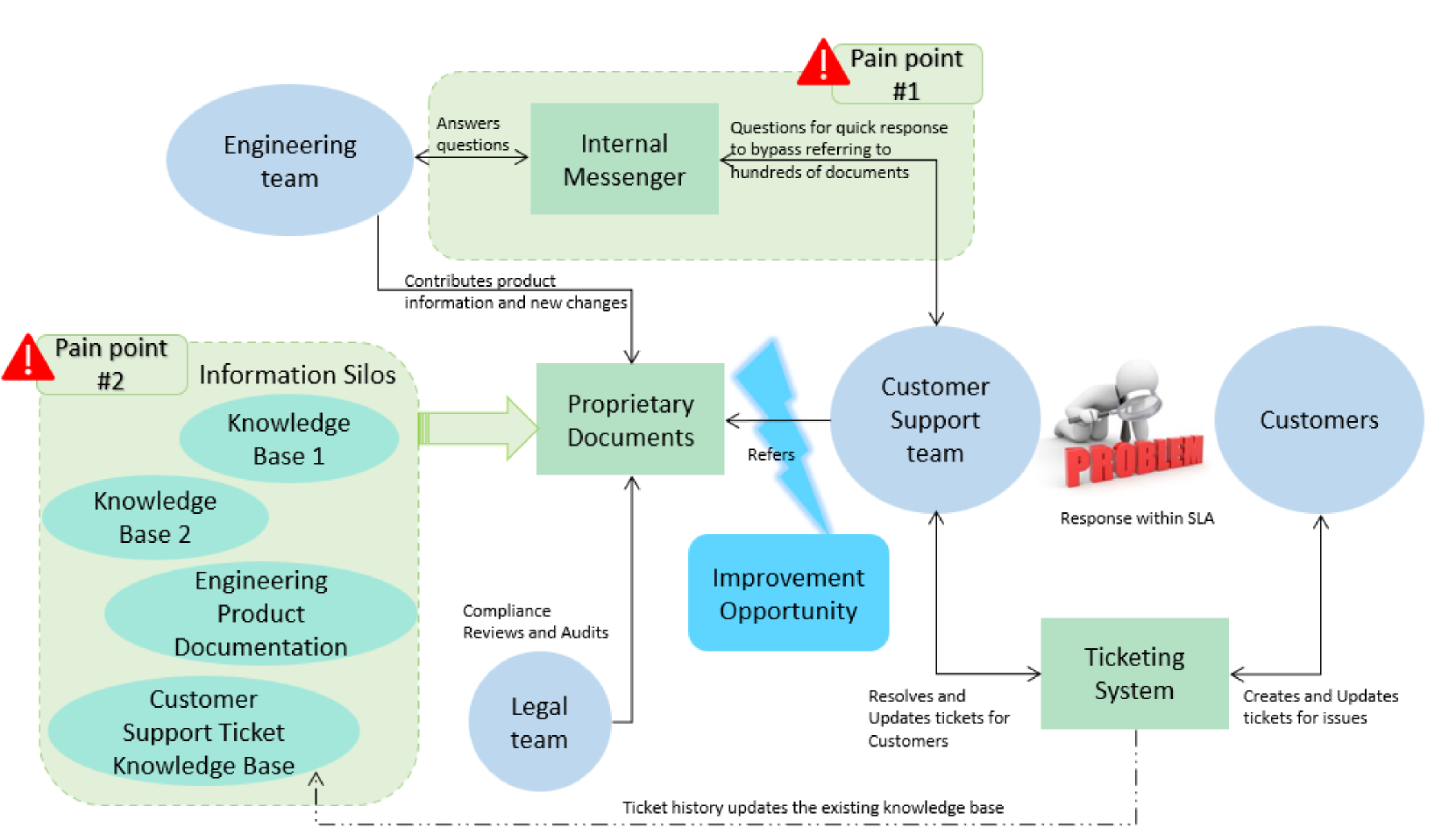
- 大型语言模型容易产生幻觉,生成不准确的信息,限制了其在信息检索等领域的应用。
- 论文提出利用检索增强生成(RAG)框架,将外部知识库的信息融入LLM的生成过程中,提高输出的事实性和可靠性。
- 通过试点项目的开发和现场测试,论文总结了RAG在实际应用中的机遇与挑战,并提出了AI治理模型。
📝 摘要(中文)
大型语言模型(LLM)的生成能力有时会受到幻觉或产生不实信息的倾向的阻碍。为了解决这个问题,研究人员越来越关注将生成输出建立在事实数据基础上的方法。检索增强生成(RAG)已经成为一种关键方法,用于整合来自LLM训练集之外的数据源的知识,包括专有和最新的信息。虽然许多研究论文探讨了各种RAG策略,但它们的真正效力需要在实际数据上的真实应用中进行测试。本文介绍了将LLM与RAG集成用于信息检索的试点项目的开发和现场测试的经验。此外,我们还研究了对信息价值链(包括人员、流程和技术)的影响。我们的目标是识别实施这项新兴技术的机遇和挑战,特别是在信息系统(IS)领域的行为研究背景下。这项工作的贡献包括开发最佳实践和建议,以采用这项有前景的技术,同时通过提出的AI治理模型确保符合行业法规。
🔬 方法详解
问题定义:大型语言模型(LLM)在生成文本时,容易产生幻觉,即生成不真实或不准确的信息。这限制了LLM在需要高度准确性的信息检索等领域的应用。现有的LLM通常依赖于其训练数据中的知识,无法及时获取最新的信息或访问专有数据。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,将外部知识库的信息融入LLM的生成过程中。RAG首先从外部知识库中检索相关信息,然后将这些信息作为上下文提供给LLM,引导LLM生成基于事实的答案。这样可以有效地减少LLM的幻觉问题,并使其能够利用最新的和专有的信息。
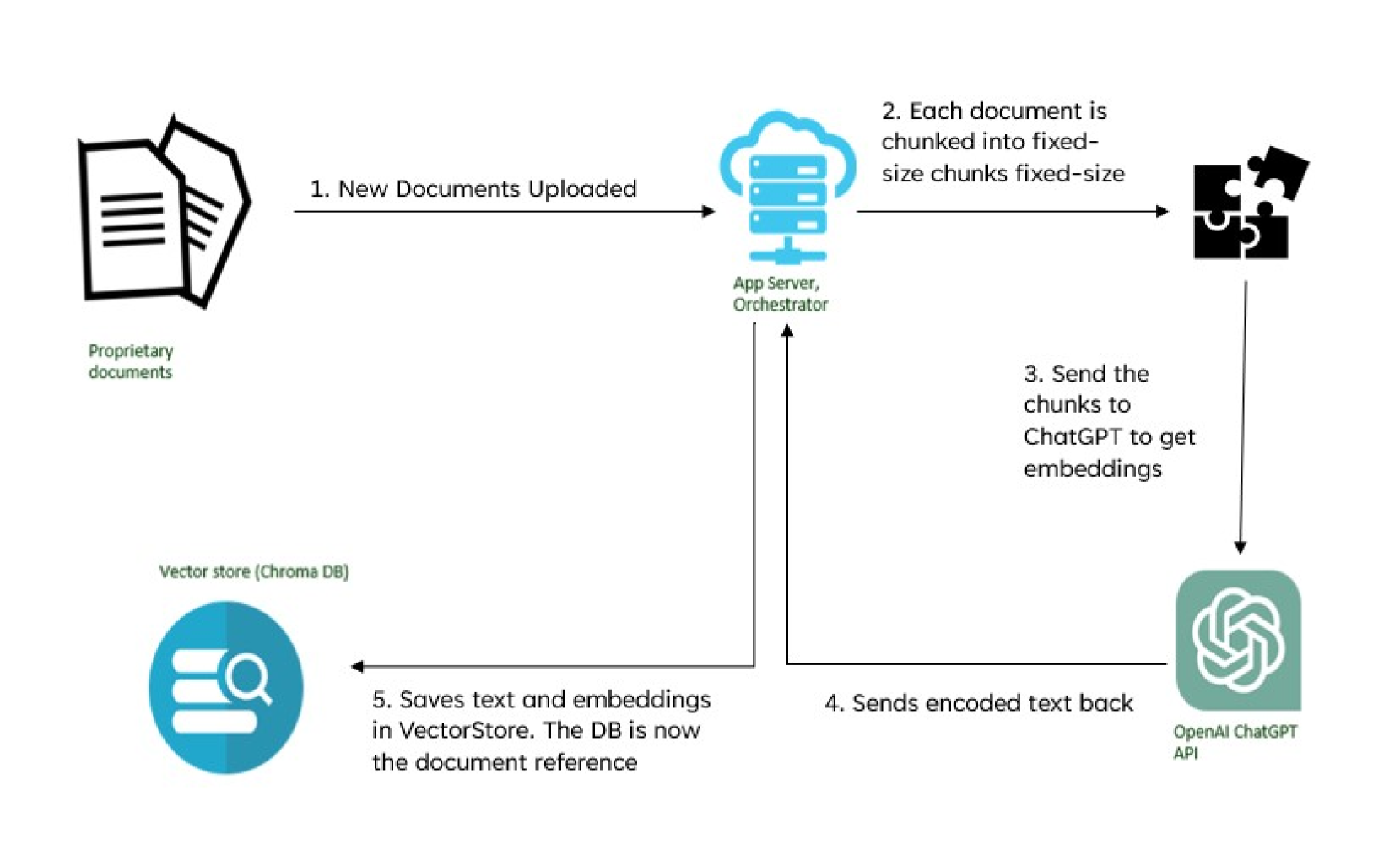
技术框架:RAG框架通常包含以下几个主要模块:1) 索引构建:将外部知识库中的文档进行索引,以便快速检索。2) 检索器:根据用户查询,从索引中检索相关文档。常用的检索方法包括基于关键词的检索和基于语义相似度的检索。3) LLM:接收用户查询和检索到的文档作为输入,生成最终的答案。LLM需要能够理解检索到的文档,并将其中的信息整合到答案中。
关键创新:论文的关键创新在于将RAG框架应用于实际的信息检索场景,并对RAG的部署和应用进行了深入的分析和总结。论文不仅关注RAG的技术细节,还关注其对信息价值链的影响,包括人员、流程和技术。此外,论文还提出了一个AI治理模型,以确保RAG的部署符合行业法规。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,论文强调了选择合适的检索器和LLM的重要性。检索器的性能直接影响RAG的检索效果,而LLM的生成能力则决定了最终答案的质量。此外,论文还强调了对检索到的文档进行预处理的重要性,例如去除噪声和提取关键信息。
🖼️ 关键图片

📊 实验亮点
论文通过一个试点项目,验证了RAG在实际信息检索场景中的有效性。虽然论文没有提供具体的性能数据,但强调了RAG能够显著减少LLM的幻觉问题,并使其能够利用最新的和专有的信息。此外,论文还总结了RAG在部署和应用过程中遇到的挑战和机遇,为其他研究人员和企业提供了宝贵的经验。
🎯 应用场景
该研究成果可应用于各种需要高度准确性和可靠性的信息检索场景,例如企业知识库检索、法律咨询、医疗诊断等。通过RAG框架,LLM可以访问最新的和专有的信息,从而提供更准确和有用的答案。此外,该研究提出的AI治理模型可以帮助企业在部署RAG时遵守行业法规,降低风险。
📄 摘要(原文)
Knowing that the generative capabilities of large language models (LLM) are sometimes hampered by tendencies to hallucinate or create non-factual responses, researchers have increasingly focused on methods to ground generated outputs in factual data. Retrieval Augmented Generation (RAG) has emerged as a key approach for integrating knowledge from data sources outside of the LLM's training set, including proprietary and up-to-date information. While many research papers explore various RAG strategies, their true efficacy is tested in real-world applications with actual data. The journey from conceiving an idea to actualizing it in the real world is a lengthy process. We present insights from the development and field-testing of a pilot project that integrates LLMs with RAG for information retrieval. Additionally, we examine the impacts on the information value chain, encompassing people, processes, and technology. Our aim is to identify the opportunities and challenges of implementing this emerging technology, particularly within the context of behavioral research in the information systems (IS) field. The contributions of this work include the development of best practices and recommendations for adopting this promising technology while ensuring compliance with industry regulations through a proposed AI governance model.