CodeLutra: Boosting LLM Code Generation via Preference-Guided Refinement
作者: Leitian Tao, Xiang Chen, Tong Yu, Tung Mai, Ryan Rossi, Yixuan Li, Saayan Mitra
分类: cs.CL
发布日期: 2024-11-07 (更新: 2025-06-25)
备注: TMLR 2025
💡 一句话要点
CodeLutra:通过偏好引导的精炼提升LLM代码生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 偏好学习 迭代精炼 微调 数据科学 Llama-3 开源模型
📋 核心要点
- 现有代码生成LLM资源需求大且易过度泛化,限制了其在特定任务上的效率,而微调小型开源LLM是一种经济的替代方案。
- CodeLutra通过迭代的偏好精炼,比较成功和失败的代码输出,从正反两方面学习,从而更准确地逼近期望结果。
- 实验表明,CodeLutra仅用少量样本即可显著提升小型LLM的代码生成准确率,性能接近大型闭源模型。
📝 摘要(中文)
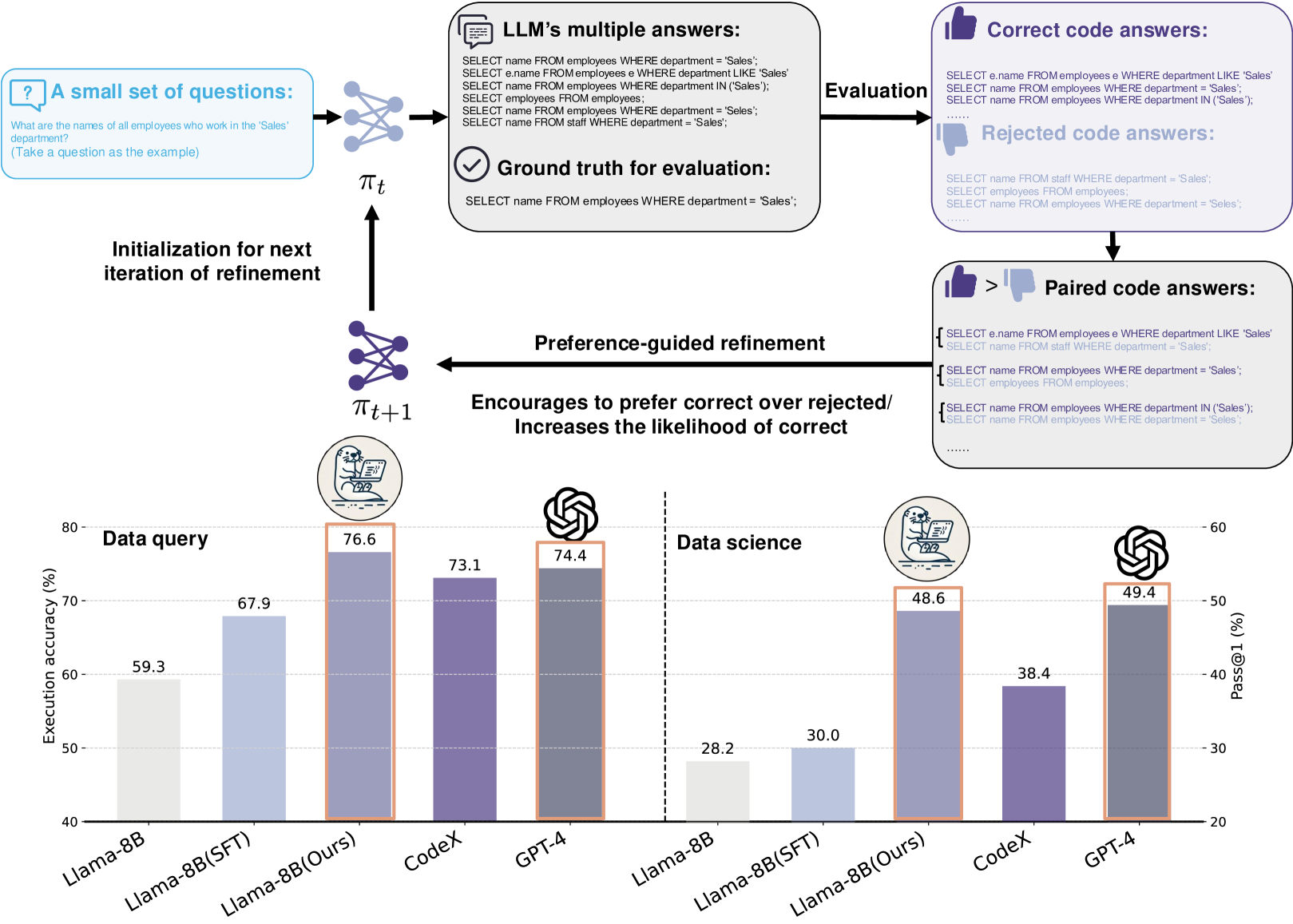
大型语言模型(LLMs)彻底改变了代码生成领域,但它们需要大量资源并且常常过度泛化,限制了其特定任务的效率。微调较小的开源LLM提供了一种经济高效的替代方案。然而,标准的监督方法仅依赖于正确的示例,忽略了失败案例中的宝贵见解。我们提出了CodeLutra,一个利用正确和不正确的代码尝试的框架。CodeLutra不只使用正确的解决方案,而是应用迭代的基于偏好的精炼,比较成功和失败的输出,以更好地逼近期望的结果。这种方法缩小了与最先进的大型模型之间的性能差距,而无需海量数据集或辅助模型。例如,在一个具有挑战性的数据科学编码任务中,仅使用500个样本就将Llama-3-8B的准确率从28.2%提高到48.6%,接近GPT-4的水平。通过从成功和错误中学习,CodeLutra为高质量代码生成提供了一条可扩展且高效的途径,使较小的开源模型更具竞争力,可以与领先的闭源替代方案相媲美。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码生成任务中资源消耗大、泛化能力过强,以及现有微调方法仅依赖正确示例而忽略失败经验的问题。现有方法无法充分利用数据中的信息,导致模型效率不高。
核心思路:CodeLutra的核心思路是通过偏好学习,让模型不仅学习正确的代码示例,还学习错误的示例,从而更好地理解代码的正确性和错误性。通过比较成功和失败的输出,模型可以学习到更细粒度的代码特征,从而提高代码生成的准确率。
技术框架:CodeLutra的技术框架主要包含以下几个阶段:1) 使用LLM生成多个候选代码片段;2) 根据执行结果或人工标注,对候选代码片段进行排序,确定偏好关系(即哪些代码片段更接近正确答案);3) 使用偏好数据训练模型,目标是使模型能够预测代码片段的偏好顺序;4) 使用训练好的模型进行代码生成,并对生成的代码进行迭代精炼,直到满足要求。
关键创新:CodeLutra的关键创新在于引入了偏好学习的思想,将代码生成问题转化为一个排序问题。与传统的监督学习方法不同,CodeLutra不仅利用了正确的代码示例,还利用了错误的示例,从而更全面地学习了代码的特征。此外,CodeLutra还采用了迭代精炼的方法,不断改进生成的代码,从而提高了代码生成的质量。
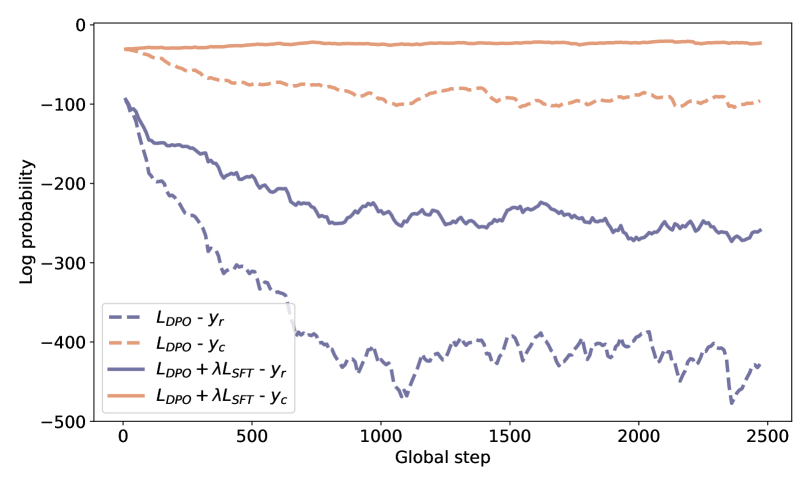
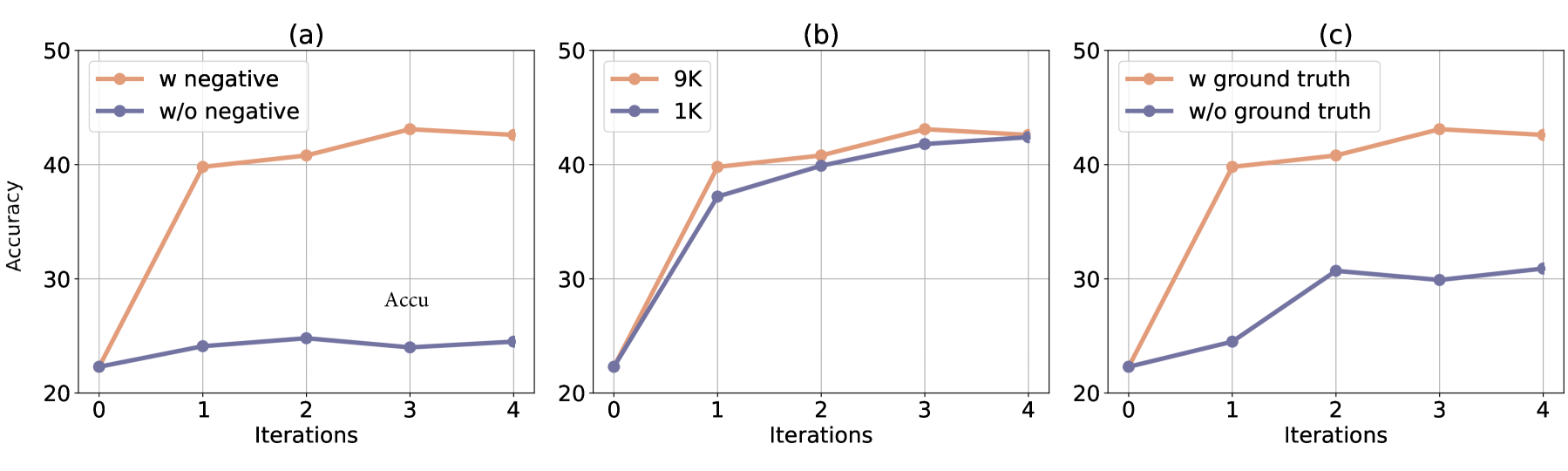
关键设计:在偏好学习阶段,可以使用不同的损失函数来训练模型,例如pairwise ranking loss或listwise ranking loss。在迭代精炼阶段,可以使用不同的策略来生成新的代码片段,例如mutation或crossover。具体的参数设置需要根据具体的任务和数据集进行调整。此外,如何有效地获取偏好数据也是一个关键问题,可以使用人工标注或自动评估的方法。
🖼️ 关键图片
📊 实验亮点
CodeLutra在数据科学编码任务中表现出色,仅使用500个样本就将Llama-3-8B的准确率从28.2%提高到48.6%,显著缩小了与GPT-4的差距。这一结果表明,CodeLutra能够有效地利用少量数据提升小型LLM的代码生成能力。
🎯 应用场景
CodeLutra具有广泛的应用前景,可以应用于各种代码生成任务,例如软件开发、数据科学、人工智能等。它可以帮助开发者更高效地生成高质量的代码,从而提高开发效率和降低开发成本。此外,CodeLutra还可以用于教育领域,帮助学生更好地学习编程。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized code generation but require significant resources and often over-generalize, limiting their task-specific efficiency. Fine-tuning smaller, open-source LLMs provides a cost-effective alternative. However, standard supervised approaches rely only on correct examples, missing valuable insights from failures. We introduce CodeLutra, a framework that leverages both correct and incorrect code attempts. Instead of using only correct solutions, CodeLutra applies iterative preference-based refinement, comparing successful and failed outputs to better approximate desired results. This approach narrows the performance gap with state-of-the-art larger models without requiring massive datasets or auxiliary models. For instance, on a challenging data science coding task, using only 500 samples improved Llama-3-8B's accuracy from 28.2% to 48.6%, approaching GPT-4's level. By learning from both successes and mistakes, CodeLutra provides a scalable and efficient path to high-quality code generation, making smaller open-source models more competitive with leading closed-source alternatives.